.png)


【摘要】本文系统梳理了从0构建大型AI推荐系统排序模型产品化的关键环节,涵盖特征工程、目标优化、Badcase治理、可解释性、用户价值显性化、工程实践与未来趋势等内容,深度挖掘技术与应用的结合路径,助力推荐系统实现商业价值与用户体验的双赢。
引言
在数字经济浪潮席卷全球的今天,AI推荐系统已成为互联网平台、内容分发、智能零售等行业的核心引擎。无论是电商平台的千人千面,还是内容社区的兴趣流派,背后都离不开强大的排序模型。排序模型的产品化,是将前沿算法能力转化为用户价值和商业成果的关键一环。它不仅仅是技术的堆砌,更是用户体验、业务目标、系统可解释性与持续优化的多维协同。
本文将以“从0构建大型AI推荐系统:排序模型产品化的关键环节”为主题,全面梳理推荐系统产品化的技术路径与工程实践,深度挖掘其在特征工程、目标优化、Badcase治理、可解释性、用户价值显性化、系统架构与未来趋势等方面的核心要素。希望通过这篇文章,为推荐系统的从业者、产品经理、算法工程师、架构师等提供一份兼具深度与广度的实战指南。
一、🌟特征工程:多维用户理解与场景适配的基石
%20拷贝-tsex.jpg)
1.1 用户画像与行为建模
1.1.1 静态属性:用户分层的起点
静态属性是用户画像的基础,主要包括年龄、性别、地域、设备类型等。这些信息为用户分层和基础偏好建模提供了坚实的支撑。例如:
年龄与性别:影响商品品类偏好(如母婴、美妆、数码等)。
地域:决定本地化服务、物流时效、文化偏好等。
设备类型:区分APP、H5、小程序等多端体验,影响内容展现形式。
1.1.2 动态行为:兴趣变化的晴雨表
动态行为特征是刻画用户兴趣变化和活跃度的关键。包括:
点击、收藏、加购、购买等行为序列
停留时长、滑动速度、页面跳转路径
跨端行为聚合(如APP与小程序的行为合并)
这些数据需按会话或用户粒度实时聚合,既要反映短期兴趣波动,也要兼顾长期偏好积累。
1.1.3 心理需求挖掘:深层兴趣的钥匙
通过NLP等技术分析用户评论、客服对话、搜索意图等文本数据,可以挖掘用户的深层心理需求。例如:
“追求健康生活”——健身器材、健康食品
“渴望自我提升”——在线课程、书籍、知识付费内容
将这些需求与商品/内容建立映射,实现兴趣标签的深层次结构化。
1.2 上下文与交互特征
1.2.1 时空特征:动态适配的利器
时间维度:区分工作日/周末、早晚高峰、节假日等,动态调整推荐内容。例如,通勤时段推送轻量内容,周末推送深度内容。
空间维度:利用GPS、Wi-Fi定位,理解用户所处位置(如家、公司、商圈),实现本地化推荐。
1.2.2 交互感知:实时策略调整的基础
滑动速度、内容停留时长等微交互数据,驱动内容复杂度和推送策略的实时调整。例如,用户快速滑动时降低内容复杂度,慢速浏览时推送高价值内容。
1.3 特征数据质量与更新
1.3.1 数据采集与存储
数据采集频率需根据业务场景灵活设定(如实时/批量),存储粒度可按用户、会话、端类型等多维度设计。
采用高效的数据管道,保障特征数据的时效性和准确性。
1.3.2 特征选择与泛化能力
利用机器学习方法(如特征选择、降维、特征交叉等)优化特征集,兼顾行为模式与社会属性,提升模型泛化能力,防止过拟合。
1.3.3 多模态特征融合
结合文本、图像、音频、行为等多模态特征,提升用户理解和推荐精准度。例如,商品图片特征、短视频内容特征与用户行为特征的联合建模。
1.4 特征工程流程图
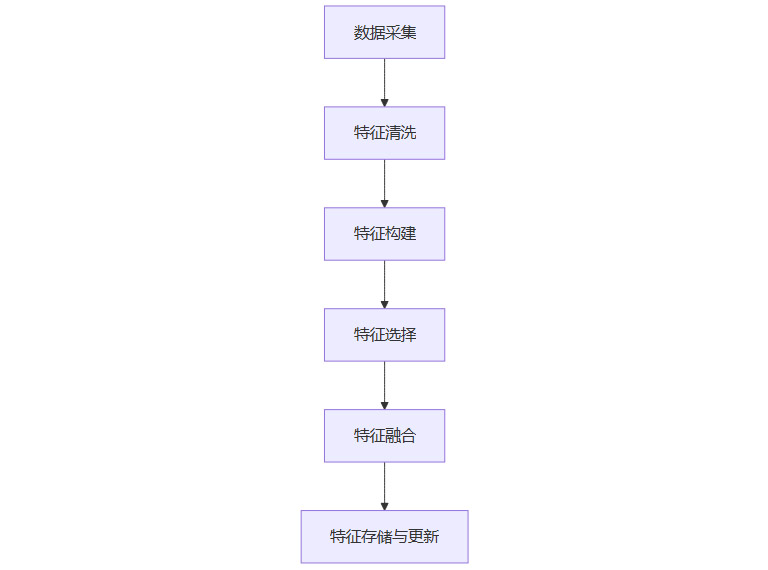
二、🚀排序模型目标设定与多目标动态优化
2.1 主目标与辅助目标分层
2.1.1 主目标:业务KPI的锚点
排序模型的主目标需紧密绑定核心业务KPI,如:
电商场景:GMV(剔除退款订单)、转化率、客单价
内容平台:完播率、活跃度、内容消费时长
主目标的定义需排除异常数据(如短时播放、异常订单),确保指标的准确性和业务相关性。
2.1.2 辅助目标:多样性与公平性的守护者
推荐多样性:防止模型陷入单一内容/商品的最优,提升用户探索体验。
公平性:保障新老用户、不同地域、不同兴趣群体的推荐体验差异不超过设定阈值(如<15%)。
内容新颖性:鼓励新内容/商品的曝光,防止信息茧房。
2.2 多目标权重与动态调整
2.2.1 初始权重设定
可基于历史数据和业务经验设定初始权重(如点击率60%、转化率30%、停留时长10%)。
2.2.2 动态权重调整
通过在线学习、A/B测试等机制,实时监控各目标表现,动态调整权重。例如,当点击率提升但转化率下降时,系统自动下调点击率权重,提升转化率权重。
2.2.3 多目标优化算法
多任务学习:通过共享参数或独立子网络,联合优化多个目标。
分数融合:各目标独立建模,最终加权融合排序分数。
遗传算法、帕累托最优:用于实时生成多目标最优解,兼顾各目标表现。
2.2.4 多目标优化流程表
2.3 公平性与伦理合规
2.3.1 公平性约束
通过技术手段保障不同用户群体的推荐体验,设置品类曝光上限(如≤40%),防止某一类内容/商品过度曝光。
2.3.2 数据隐私与合规
强化数据隐私保护,采用联邦学习、差分隐私等技术,确保用户数据安全合规。
三、🛡️Badcase分析与闭环治理:质量防火墙
%20拷贝.jpg)
3.1 问题识别与分层定位
3.1.1 Badcase类型
低质内容:如标题党、重复推荐、内容质量差
兴趣不匹配:用户连续多次点击的内容未被推荐
体验问题:加载慢、推荐结果无关、负反馈内容反复出现
3.1.2 问题监控与采集
通过埋点日志、用户反馈、异常监控等手段,持续监控推荐结果,及时发现Badcase。
3.1.3 分层定位流程
召回层:检查内容库覆盖率、召回策略合理性
排序层:分析模型预估分数与实际行为的偏差
策略层:排查重排规则、曝光策略等是否引发问题
3.2 问题处理与系统迭代
3.2.1 即时干预
对负反馈内容短期屏蔽(如7天),防止用户体验恶化
针对高频Badcase,快速调整策略或规则止损
3.2.2 长期优化
将Badcase样本注入训练集,驱动特征工程和模型结构升级
新增“负反馈次数”等特征,提升模型对难样本的区分能力
引入对比学习、难例挖掘等前沿技术,提升模型鲁棒性
3.3 闭环机制
3.3.1 闭环治理流程图
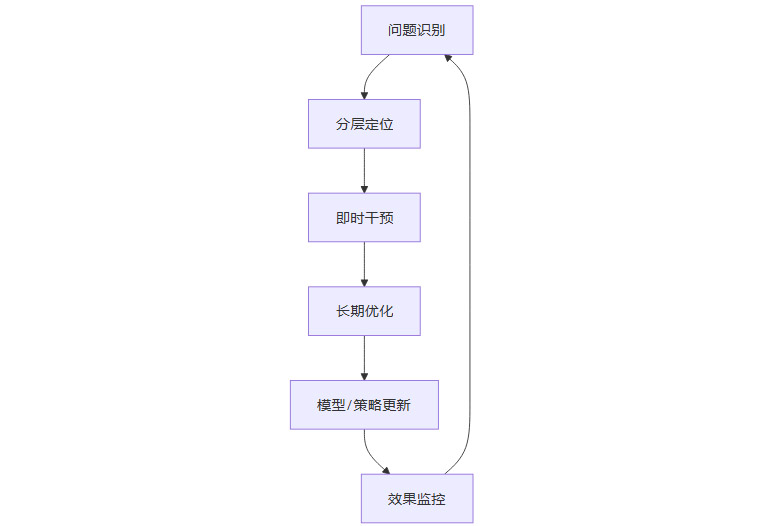
3.3.2 持续自我进化
建立“识别-定位-干预-迭代”闭环,确保问题发现后能快速反馈到模型和策略优化中,形成持续自我进化的系统。
四、🔍可解释性与用户价值显性化:增强信任与体验
4.1 推荐理由与动态标签
4.1.1 多层次理由标签体系
基础型:“您关注过的品牌”、“同类用户也喜欢”
场景型:“通勤时段热门内容”、“周末家庭活动推荐”
价值型:“用户评价高分精选”、“历史低价商品”
4.1.2 标签展示策略
首页采用“1主因+3辅因”组合,突出主要推荐理由,辅以次要标签
详情页采用渐进式解释,用户停留时间较长(如>10秒)时,加载更详细的推荐理由(如“该商品与您收藏的连衣裙风格匹配度85%”)
4.2 价值可视化与个性化指数
4.2.1 个性化指数与推荐体验分
设计“个性化指数”或“推荐体验分”(1-10分),综合准确性、多样性、新颖性等指标,直观展示推荐带来的价值
在用户中心可视化呈现,如“本月发现新兴趣”、“节省决策时间”等
4.2.2 价值可视化表
4.3 用户反馈与主动参与
4.3.1 轻量反馈机制
推荐结果旁设置“喜欢/不喜欢”按钮,点击后可展开二级反馈选项(如“不感兴趣”、“已购买”)
反馈实时回流,驱动用户画像和模型动态更新
4.3.2 主动探索与偏好调节
提供“推荐探索实验室”等功能,允许用户主动调整推荐偏好(如“增加科技类内容”、“减少广告推荐”)
支持对比不同偏好设置下的推荐结果,提升用户参与度和系统自适应能力
五、🏗️工程实践与系统能力要求
%20拷贝-lndu.jpg)
5.1 分层系统架构
5.1.1 数据采集与特征工程层
高效采集多源数据,标准化特征处理流程,保证线上线下一致性
支持多模态特征融合,提升用户理解和推荐精准度
5.1.2 召回-排序-重排多级架构
召回层:快速筛选候选内容/商品,提升系统响应速度
排序层:精细建模,优化多目标表现
重排层:结合业务规则、多样性策略,提升最终推荐质量
5.1.3 可解释性与用户交互层
理由标签、体验分、反馈入口等,提升用户参与度和系统透明度
5.2 实时反馈与A/B测试
5.2.1 低延迟反馈机制
负反馈需在200ms内更新用户画像,支持实时在线学习和策略调整
5.2.2 A/B测试与数据驱动优化
持续进行A/B测试,验证模型和策略的实际效果,确保系统持续响应用户行为和业务目标变化
5.3 多模态与前沿技术融合
5.3.1 多模态特征建模
结合文本、图像、音频、行为等多模态特征,提升推荐系统的泛化能力和精准度
5.3.2 前沿技术应用
引入大模型(如GPT、BERT)、联邦学习、因果推理等新技术,强化隐私保护和误推荐率控制
六、🔮未来趋势与挑战
6.1 大模型与多模态融合
AI大模型推动多模态特征深度融合和语义理解,提升推荐系统的泛化能力和精准度
多模态融合有助于捕捉用户复杂兴趣和场景变化,实现更智能的个性化推荐
6.2 公平性与伦理合规
持续引入公平性约束,保障不同用户群体的推荐体验
强化数据隐私与合规,采用联邦学习、差分隐私等技术,提升用户信任
6.3 可解释性与用户信任
优化推荐解释方式,平衡推荐效果与解释清晰度
推动系统向更透明、用户友好的方向发展,增强用户对AI推荐系统的信任
6.4 持续迭代与动态优化
推荐系统产品化是动态过程,需不断响应用户和业务变化
实现“数据-算法-体验”增强回路,推动系统持续自我进化
结论
大型AI推荐系统排序模型的产品化,是一个涵盖特征工程、多目标优化、Badcase闭环治理、可解释性、用户反馈与工程架构的系统工程。只有将算法能力与用户体验、业务目标深度融合,并通过动态迭代和前沿技术持续优化,才能实现推荐系统的最大商业价值和用户满意度。未来,随着大模型、多模态、因果推理等技术的不断突破,推荐系统将更加智能、透明和人性化,成为数字经济时代不可或缺的基础设施。
📢💻 【省心锐评】
“推荐系统产品化,拼的是细节与闭环,赢在体验与进化。”

评论