.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】OpenAI正研发新一代多模态音乐生成模型,旨在与Sora等工具深度融合,重塑内容创作流程。此举在推动技术革新的同时,也直面全球性的版权授权与合规挑战。
引言
在相继发布ChatGPT与Sora,分别颠覆了文本与视频内容的生成范式之后,OpenAI将目光投向了第三个关键创意领域,音乐。这并非一次简单的技术版图扩张,而是其构建多模态AI生态闭环的必然一步。从理解语言的逻辑,到解析视觉的动态,再到如今捕捉旋律的情感,OpenAI正试图打通人类创意的任督二脉。
新一代音乐生成模型的研发,标志着AI从“能听懂”到“会创作”的决定性跨越。它所承载的期望,远不止是生成几段悦耳的旋律。它旨在成为内容创作者的协同工具,无缝嵌入从视频制作到互动娱乐的各类工作流中。然而,正如Sora的出现引发了对视觉内容真实性的讨论,AI音乐的诞生也必然会踏入一片更为复杂的雷区,那就是技术创新与现行版权法律体系的激烈碰撞。本文将从技术架构、应用生态、版权困境及全球竞争格局四个维度,深度剖析OpenAI在AI音乐领域的布局,并探讨其面临的双重边界挑战。
一、🎵 新一代音乐生成模型的技术解构
%20拷贝.jpg)
OpenAI的新模型并非凭空出世,它站在其前辈MuseNet与Jukebox的肩膀上,但其技术内核与设计理念已发生根本性变革。其目标不再是实验性的音乐片段生成,而是追求录音室级别的音质、精细化的创作控制以及与其它模态的无缝协同。
1.1 核心架构推演与技术前瞻
尽管OpenAI尚未公布新模型的具体技术论文,但基于其技术路线与行业发展趋势,我们可以对其核心架构进行合理的推演。
1.1.1 基于Transformer的自回归框架
新模型极有可能延续GPT系列与Sora所采用的Transformer架构,并针对音频信号的特性进行深度优化。在这一框架下,音乐生成过程被建模为一个序列预测任务。
音频离散化 (Tokenization):原始的连续音频波形(Waveform)无法直接被Transformer处理。模型需要先通过一个高效的音频编解码器(Codec),如Google的SoundStream或Meta的EnCodec,将音频压缩成离散的声学单元(Token)。这个过程类似于自然语言处理中的分词,将复杂的声波信息转化为模型可以理解的“声学词汇”。高质量的Tokenization是保证生成音质的基础。
序列预测:模型以自回归(Autoregressive)的方式,根据已经生成的Token序列,预测下一个最有可能出现的Token。通过逐个Token的预测与拼接,最终解码还原成完整的音频波形。这种机制使得模型能够学习到音乐的内在结构,包括旋律走向、和声进行和节奏模式。
1.1.2 多模态融合的输入机制
新模型的革命性在于其多模态输入能力,它打破了传统音乐生成工具单一的输入限制,为用户提供了前所未有的控制自由度。
文本提示 (Text Prompts):这是最基础的控制方式。用户可以通过自然语言描述音乐的风格、情绪、乐器配置、节奏快慢等。例如,“一段适合在海边日落时播放的,带有忧郁感的民谣吉他独奏,BPM约80”。
音频提示 (Audio Prompts):这是实现更高级控制的关键。用户可以输入一段音频作为“引子”或“参考”。
旋律续写:输入一段哼唱的旋律,模型可以此为基础,将其发展成一首完整的、配器丰富的乐曲。
风格迁移:输入一首参考曲目,要求模型以其风格生成全新的音乐。
伴奏生成:输入一段纯人声(Acapella),指令模型为其添加特定乐器,如贝斯、鼓点和合成器,这是其核心应用之一。
下表清晰展示了不同输入模态组合带来的创作可能性。
1.1.3 数据驱动的音乐理解
为了让模型真正“理解”音乐,而非简单模仿,高质量的训练数据至关重要。OpenAI与**茱莉亚音乐学院(Juilliard School)**的合作,正是在为此铺路。
乐谱注解:由专业音乐学生对大量乐谱进行精细化标注,这些标注信息可能包括和弦标记、曲式结构、配器法、演奏技巧等。
多层级数据对齐:模型训练时,不仅学习原始音频数据,还会学习与之对齐的乐谱、MIDI信息和文本描述。这种多层级的数据输入,使得模型能够建立起从抽象概念(如“悲伤的”)到具体音乐元素(如小调和弦、慢速节奏)之间的映射关系。这正是新模型有望超越前辈,实现更深层次音乐理解与表达的关键所在。
1.2 从Jukebox到新模型的代际跃迁
OpenAI在2020年发布的Jukebox AI,虽然在当时实现了生成带人声歌曲的突破,但其局限性也十分明显。新一代模型正是在全面解决这些痛点。
这次代际跃迁的核心,是从一个技术验证性质的研究项目,转向一个面向实际应用的生产力平台。它标志着AI音乐生成技术正在走出实验室,真正具备了赋能广大内容创作者的潜力。
二、🎼 应用场景与生态闭环的战略构想
OpenAI开发音乐模型,其战略意图远超音乐本身。它的目标是将音乐生成能力作为一块关键拼图,嵌入其庞大的AI生态系统,从而构建一个前所未有的多模态内容创作闭环。
2.1 内容创作流程的重塑
新模型将直接作用于内容创作的多个环节,极大地降低技术门槛,提升生产效率。
2.1.1 视频内容的声画一体化
这是新模型最令人期待的应用场景,特别是与Sora的联动。目前,为视频寻找或制作合适的背景音乐,是一个耗时耗力的过程,涉及版权购买、音乐剪辑、音画同步等多个专业步骤。
AI驱动的新工作流可能如下所示:
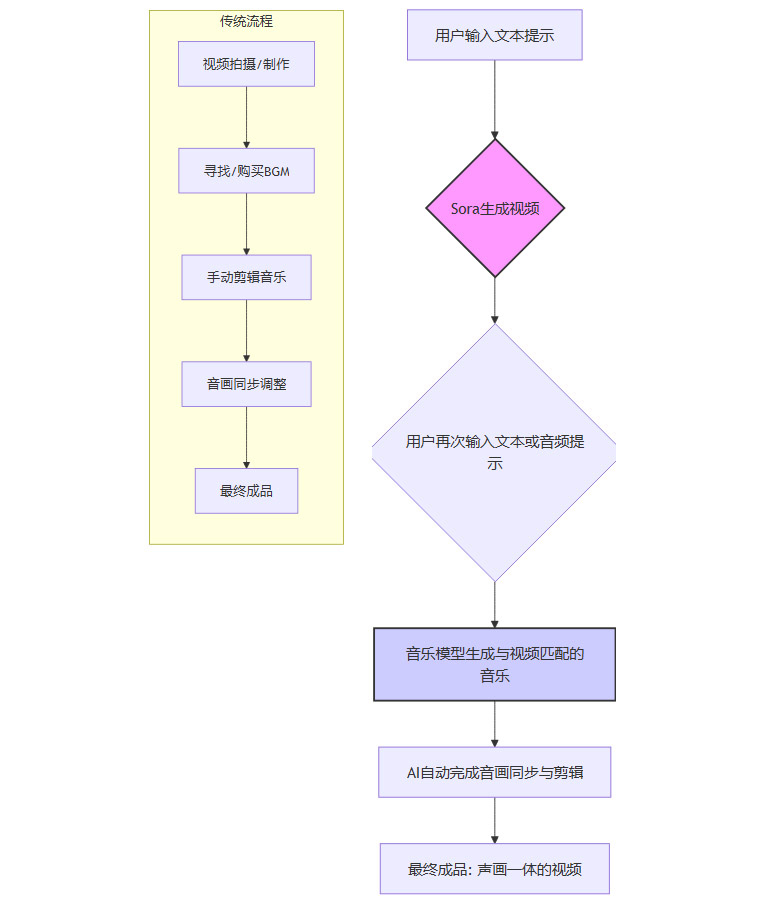
这个流程的变革性在于:
效率:将原本数小时甚至数天的工作,压缩到分钟级别。
创意:音乐不再是视频的附属品,而是在创作初期就与画面同步构思、同步生成,实现了真正的声画共创。
成本:对于独立创作者和小团队而言,昂贵的版权音乐库和专业的音频工程师将不再是必需品。
2.1.2 音乐制作的辅助与增强
对于音乐人而言,AI不会完全取代创作,但会成为一个强大的“灵感激发器”和“效率工具”。
快速原型搭建:当音乐人有一个旋律动机时,可以立即让AI为其生成不同风格的伴奏原型,快速验证想法。
自动化繁琐工作:AI可以自动完成和弦编配、鼓点编写、贝斯线填充等相对模式化的工作,让音乐人更专注于核心的旋律与创意。
突破创作瓶颈:通过AI生成意想不到的旋律片段或和声进行,可以为陷入瓶颈的创作者提供新的灵感来源。
2.2 OpenAI生态系统的战略延伸
坐拥超过8亿的周活跃用户,OpenAI推广任何新功能都具备天然的流量优势。音乐模型的推出,是其巩固平台地位、提升用户价值的重要一步。
2.2.1 用户黏性与平台价值
通过提供从文本、代码、图片、视频到音乐的全方位AI生成能力,OpenAI正在打造一个“一站式”的AI创意工作平台。用户一旦习惯在这个生态内完成所有创作任务,其迁移成本将变得极高,从而极大地提升了用户黏性。平台的价值也从单一的工具提供商,转变为一个综合性的创意基础设施服务商。
2.2.2 产品形态的猜想
关于新模型的最终产品形态,目前存在两种主要可能性,每种都有其战略考量。
无论最终形态如何,其背后都离不开OpenAI强大的开发者生态。通过开放API,开发者可以将AI音乐生成能力集成到自己的应用中,例如游戏引擎、视频剪辑软件、在线教育平台等,从而构建一个庞大的AI音乐应用生态。
三、⚖️ 版权困境与合规的“达摩克利斯之剑”
%20拷贝.jpg)
技术上的突破固然令人兴奋,但真正决定AI音乐能否顺利商业化、甚至能否合法存在的,是其头顶悬着的版权与合规这把“达摩克利斯之剑”。这是OpenAI乃至整个生成式AI行业都无法回避的终极挑战。
3.1 训练数据的原罪与“合理使用”的模糊地带
生成式AI的强大能力,建立在对海量数据的学习之上。对于音乐模型而言,这意味着需要“聆听”数百万甚至数千万首歌曲。而当今世界,几乎所有高质量的录音制品都受到版权保护。这就引发了一个根本性的法律冲突。
数据来源的争议:AI公司很少会公开其训练数据的具体来源。但业界普遍认为,这些数据不可避免地包含了大量未经授权的、受版权保护的音乐作品。这些数据可能通过网络爬虫等方式从公开平台抓取,其合法性备受质疑。
“合理使用”原则的辩护:AI公司通常会援引“合理使用”(Fair Use)原则为自己辩护。他们认为,使用受版权保护的作品进行模型训练,属于一种“转换性使用”(Transformative Use),因为其目的不是复制原作,而是学习其内在的模式与风格,最终生成全新的、原创的作品。
法律体系的滞后:然而,“合理使用”原则的界定本身就非常复杂,且在不同国家和地区的司法实践中存在巨大差异。现有的版权法律体系在制定时,并未预见到生成式AI这种全新的技术形态。因此,将其应用于AI训练数据是否合法,目前在全球范围内都没有明确的法律定论,这给整个行业带来了巨大的不确定性。
3.2 行业的反击:从诉讼到谈判
面对AI的崛起,传统音乐产业的反应是复杂且矛盾的。一方面,他们看到了AI作为创作工具的潜力;另一方面,他们更担心其对现有商业模式和版权利益的颠覆。
3.2.1 法律诉讼的号角
全球各大唱片公司已经开始采取法律行动。针对Suno、Udio等新兴AI音乐公司的集体诉讼案,标志着音乐产业的正式反击。这些诉讼的核心诉求通常包括:
侵犯版权:指控AI公司未经许可,大规模复制其拥有版权的音乐用于模型训练。
要求赔偿:就过去的侵权行为索要巨额经济赔偿。
寻求禁令:要求法院禁止这些公司继续使用其版权作品进行训练,甚至要求其销毁已经训练好的模型。
这些诉讼的结果,将对整个AI音乐行业产生判例性的影响。
3.2.2 艰难的授权谈判
与直接对簿公堂相比,谈判桌上的博弈更为复杂。OpenAI深知合规的重要性,已经开始与多家主要唱片公司和版权组织进行授权谈判。但谈判进展缓慢,双方在核心利益上存在巨大分歧。
下表梳理了各方在谈判中的核心立场与诉求。
这场谈判的本质,是在为一个全新的、由AI驱动的音乐生态重新制定游戏规则。这不仅是商业利益的博弈,更是对未来音乐产业价值链的重新定义。
四、⚔️ 全球AI旋律竞逐:巨头与新贵的战场
%20拷贝.jpg)
OpenAI并非孤军奋战。事实上,全球AI音乐赛道已经挤满了重量级玩家,一场围绕“AI旋律”的激烈竞赛早已拉开帷幕。
4.1 棋盘上的主要玩家
从科技巨头到明星创业公司,各路玩家纷纷亮出自己的王牌产品,其技术路线和市场策略各有侧重。
4.2 技术竞赛的关键维度
在这场“军备竞赛”中,各家公司比拼的不仅仅是生成音乐的能力,更是在多个技术维度上的综合实力。
音质与保真度 (Audio Fidelity):这是最基础的门槛。能否生成清晰、干净、无杂音的录音室级别音质,是用户体验的第一道关。
控制的粒度 (Control Granularity):从简单的文本提示,到能控制具体音符、和弦、配器的专业级编辑,控制的精细程度决定了模型是“玩具”还是“工具”。
人声的真实性 (Vocal Realism):生成自然、富有情感、吐字清晰的人声是AI音乐领域公认的技术难点,也是Suno V5能够脱颖而出的关键。
结构与连贯性 (Structure & Coherence):能否生成符合音乐理论、结构完整、逻辑连贯的长时程音乐,是衡量模型“音乐智商”的重要指标。
生态与集成 (Ecosystem & Integration):模型能否通过API、插件等形式,方便地集成到现有的数字音频工作站(DAW)、视频剪辑软件等工作流中,直接影响其商业化落地的前景。
这场竞赛的最终赢家,不仅需要拥有最顶尖的技术,更需要找到技术、用户体验与商业模式的最佳结合点。
结论
OpenAI进军AI音乐领域,是其构建全能AI内容生态的必然选择。从技术上看,其新一代模型有望凭借多模态输入和高质量数据,在音乐生成的可控性与专业性上树立新的标杆,并与Suno等产品形成差异化竞争。其与Sora的联动,更预示着一个声画一体化AI创作新时代的到来。
然而,前路并非坦途。横亘在所有玩家面前的,是巨大且复杂的版权高墙。技术的发展速度已经远远超过了法律的更新速度,由此产生的鸿沟正成为行业最大的不确定性来源。OpenAI能否利用其行业地位与资源,率先与音乐产业达成历史性的授权协议,将成为其能否将技术优势转化为市场胜势的关键。
最终,这场从Sora到Symphony的征途,考验的不仅是OpenAI的技术实力,更是其在复杂的商业、法律和道德博弈中,寻找平衡与突破的智慧。这场变革的最终走向,将深刻重塑我们创作、消费乃至理解音乐的方式。
📢💻 【省心锐评】
OpenAI的音乐野心,技术上已箭在弦上,商业上却步步惊心。真正的决胜点,不在代码,而在与版权方的谈判桌上。

评论