.png)


【摘要】2025年ACL大会上,中国学者首次在获奖论文中占比过半,DeepSeek实习生主导的NSA机制荣获最佳论文奖。NSA以硬件友好、端到端可训练的稀疏注意力创新,推动长上下文AI模型能力跃升。DeepSeek V4即将集成NSA,行业期待新一轮技术飞跃。
引言
2025年国际计算语言学年会(ACL)成为中国自然语言处理(NLP)领域历史性时刻的见证。中国学者在获奖论文中占比首次突破51%,不仅彰显了中国在全球NLP领域的崛起,也为未来技术创新和产业变革奠定了坚实基础。在本届ACL大会上,DeepSeek团队与北京大学等机构合作的论文《Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention》(NSA)荣获最佳论文奖,成为业界关注的焦点。更令人瞩目的是,这项突破性成果的第一作者袁境阳,在论文撰写时仅为DeepSeek实习生,展现了中国AI创新生态的活力与青年人才的巨大潜力。
本文将围绕NSA机制的技术创新、实验评测、行业影响及未来展望,深入剖析其如何引领长上下文AI模型的革命,并探讨中国学者在全球NLP舞台上的崛起。文章将以结构化、易读的方式,全面梳理NSA的理论基础、工程实现、实验数据、行业意义及未来趋势,力求为技术论坛读者呈现一篇兼具深度与广度的专业解读。
一、2025年ACL大会:中国学者的历史性突破
%20拷贝.jpg)
1.1 全球NLP格局的变迁
2025年ACL大会见证了中国学者在自然语言处理领域的重大突破。数据显示,中国作者在获奖论文中占比首次超过51%,远超美国的14%。这一历史性时刻,不仅反映了中国在NLP基础研究和工程创新方面的持续投入,也预示着全球NLP格局的深刻变化。
1.1.1 数据驱动的学术崛起
中国学者在ACL获奖论文中的占比变化如下表所示:
这一趋势背后,是中国在大模型、算法创新、硬件优化等多维度的持续突破。以DeepSeek团队为代表的中国AI企业,正逐步成为全球NLP创新的重要引擎。
1.1.2 产业与学术的深度融合
中国NLP领域的崛起,离不开产业界与学术界的深度融合。以DeepSeek为例,其与北京大学等顶尖学府的合作,不仅推动了前沿技术的落地,也为青年人才提供了广阔的创新舞台。此次NSA论文的获奖,正是产学研协同创新的典范。
1.2 DeepSeek团队与NSA论文的聚光时刻
在本届ACL大会上,DeepSeek团队与北京大学等机构合作的NSA论文荣获最佳论文奖,成为全场焦点。论文第一作者袁境阳在会议现场的讲座中,详细介绍了NSA机制的技术原理与工程实现,并透露该技术已能将上下文长度扩展至100万tokens,计划应用于DeepSeek下一代前沿模型(V4)。
1.2.1 实习生主导的创新突破
值得一提的是,袁境阳在撰写论文时仅为DeepSeek实习生。这一事实不仅彰显了企业创新生态的活力,也体现了中国AI企业对青年人才的高度重视。NSA的成功,既是技术创新的胜利,也是人才培养模式的典范。
1.2.2 业界的高度关注与期待
NSA论文的获奖,引发了业界对DeepSeek V4模型的高度期待。此前,关于DeepSeek R2模型提前发布的传闻甚嚣尘上,DeepSeek官方多次辟谣,强调所有产品信息以官方渠道为准。此次NSA技术的公开与获奖,无疑为DeepSeek下一代模型增添了更多看点。
二、NSA机制:长上下文AI的革命性突破
2.1 长上下文建模的技术瓶颈
2.1.1 传统注意力机制的局限
Transformer架构自2017年提出以来,已成为NLP领域的主流。然而,随着序列长度的增加,传统全注意力(Full Attention)机制在计算和存储上的成本呈二次方增长,成为长上下文建模的主要瓶颈。具体而言,注意力计算在长序列下占总延迟的70%-80%,极大限制了大模型在长文本理解、推理等任务中的应用。
2.1.2 行业对高效长序列建模的需求
随着大模型在法律、金融、医疗等领域的应用深入,长文本处理能力成为衡量AI模型实用性的关键指标。如何在保证模型性能的前提下,显著提升长序列处理的效率,成为业界亟需解决的难题。
2.2 NSA机制的核心创新
NSA(Natively trainable Sparse Attention,原生可训练稀疏注意力)机制,正是为破解上述难题而生。其核心创新体现在以下三个方面:
2.2.1 动态分层稀疏策略
NSA通过动态分层稀疏策略,将注意力计算划分为全局与局部两个层次:
粗粒度token压缩:用于全局上下文扫描,快速捕捉长序列中的关键信息。
细粒度token选择:用于局部信息检索,确保模型对细节的精准把控。
这种分层设计,实现了全局感知与局部精度的有机统一,极大提升了长序列建模的效率与效果。
2.2.2 硬件对齐优化
NSA在算法设计上充分考虑了现代GPU(如Tensor Core)的硬件特性,通过算术强度平衡、内存访问优化等手段,显著提升了推理和训练速度。具体加速效果如下表所示:
这一硬件友好型设计,有效缓解了长序列下注意力计算的延迟瓶颈,为大模型的工程落地提供了坚实基础。
2.2.3 端到端可训练性
NSA不仅在推理阶段应用稀疏性,更在预训练阶段原生集成稀疏注意力。通过高效算法与反向算子的引入,NSA实现了端到端的可训练性,既降低了整体计算成本,又确保了训练的稳定性和模型性能的提升。
2.3 NSA机制的理论基础与工程实现
2.3.1 稀疏注意力的理论优势
稀疏注意力机制通过过滤掉冗余和噪声信息,提升了模型对关键信息的关注度。在长序列任务中,稀疏性不仅带来计算加速,更有助于提升模型的泛化能力和鲁棒性。
2.3.2 NSA的工程实现流程
以下Mermaid流程图展示了NSA机制的工程实现流程:
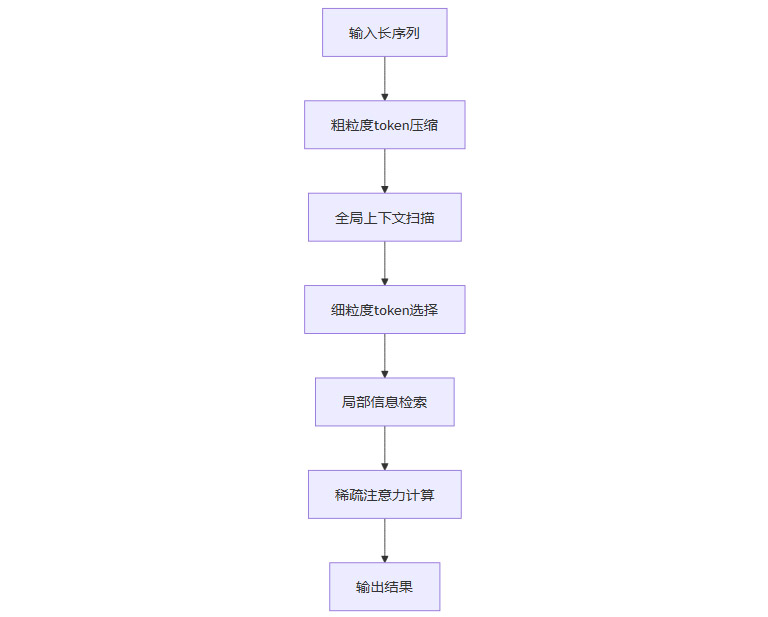
这一流程确保了NSA在处理超长序列时,既能高效捕捉全局信息,又能精准检索局部细节,实现了效率与效果的双重提升。
三、NSA机制的实验评测与性能分析
%20拷贝.jpg)
3.1 大规模预训练与评测设置
3.1.1 预训练规模与数据
NSA机制在拥有270亿参数的Transformer骨干网络上进行了大规模预训练,训练数据量高达2600亿token,覆盖多种真实世界语言语料库,确保了模型的泛化能力和实用价值。
3.1.2 评测指标与基线模型
团队在9项主流评测指标上,对NSA与包括全注意力模型在内的多种基线模型进行了系统对比,涵盖通用语言理解、长上下文建模、复杂推理等多个维度。
3.2 实验结果与性能优势
3.2.1 综合性能超越基线
实验数据显示,NSA在9项评测指标中的7项超越了所有基线模型,尤其在长上下文和复杂推理任务中表现突出。具体提升如下表所示:
3.2.2 长序列推理与检索的卓越表现
在64k“大海捞针”测试中,NSA实现了全位置100%检索准确率,充分验证了其在超长序列下的高效性和准确性。稀疏性不仅提升了计算效率,还有效过滤了噪声,进一步优化了模型的基准测试表现。
3.2.3 与下游任务的兼容性
NSA在与先进下游训练范式(如链式思维数学推理)结合时,也展现了优异的兼容性和推理深度,进一步验证了其作为通用架构的稳健性。
四、NSA机制的行业影响与未来展望
4.1 技术落地与产业变革
4.1.1 DeepSeek V4的技术升级
尽管NSA技术已于2025年2月公开发表,但尚未应用于现有DeepSeek模型。DeepSeek团队已确认,NSA将集成于下一代前沿模型(如V4),引发业界对DeepSeek V4在长上下文处理能力上的高度期待。
4.1.2 行业对长文本AI的期待
NSA的高效、可扩展和硬件友好特性,有望推动下一代大模型在长文本理解、推理等领域实现质的飞跃。法律、金融、医疗等对长文本处理有强烈需求的行业,将率先受益于NSA技术的落地。
4.2 创新生态与人才活力
4.2.1 实习生驱动的创新范式
论文第一作者袁境阳在撰写论文时仅为DeepSeek实习生,突显了企业创新生态的活力和对青年人才的重视。NSA的成功,既是技术创新的胜利,也是人才培养模式的典范。
4.2.2 产学研协同创新
DeepSeek与北京大学等顶尖学府的合作,推动了前沿技术的快速落地,也为青年人才提供了广阔的创新舞台。NSA的诞生,正是产学研协同创新的生动写照。
4.3 信息透明与行业规范
4.3.1 官方辟谣与信息透明
针对DeepSeek R2模型提前发布的传闻,DeepSeek官方多次辟谣,强调所有产品信息以官方渠道为准,确保信息透明和权威。这一做法,有助于维护行业规范,提升用户信任度。
4.3.2 行业健康发展的保障
信息透明与权威发布,是AI行业健康发展的重要保障。DeepSeek在NSA技术推广和产品发布中的规范操作,为行业树立了良好榜样。
五、NSA机制的综合评价与未来趋势
%20拷贝.jpg)
5.1 NSA的技术价值与行业意义
NSA机制不仅在算法和工程实现上实现了创新突破,也为硬件友好型AI算法设计树立了新标杆。其高效、可扩展和硬件友好的特性,有望推动下一代大模型在长文本理解、推理等领域实现质的飞跃。
5.2 中国NLP的国际影响力提升
NSA的获奖,标志着中国在自然语言处理领域的国际影响力持续提升。中国学者在ACL等顶级学术舞台上的崛起,为全球NLP技术创新注入了新的活力。
5.3 未来展望:AI长文本理解的新时代
随着NSA在DeepSeek V4等新一代模型中的应用落地,业界有望见证AI长文本理解与推理能力的又一次飞跃。未来,NSA有望成为长上下文AI模型的主流架构,推动AI在更多复杂场景下实现智能化升级。
六、NSA机制的技术深度剖析与工程实现细节
6.1 稀疏注意力的理论基础与发展脉络
6.1.1 稀疏注意力的起源与演进
稀疏注意力(Sparse Attention)并非新概念。自Transformer架构提出以来,研究者们便不断探索如何在不损失模型表达能力的前提下,降低注意力计算的复杂度。早期的稀疏注意力方法,如局部窗口(Local Window)、块稀疏(Block Sparse)、随机稀疏(Random Sparse)等,均试图通过减少注意力矩阵中的非零元素,来降低计算和存储开销。
然而,这些方法往往面临以下挑战:
稀疏模式固定,难以适应多样化任务需求
稀疏性与模型性能之间存在权衡
硬件实现复杂,难以充分发挥现代GPU的算力优势
NSA机制的提出,正是在吸收前人经验的基础上,针对上述痛点进行了系统性创新。
6.1.2 NSA的理论创新点
NSA的理论创新主要体现在以下几个方面:
动态分层稀疏策略:通过粗粒度token压缩与细粒度token选择的结合,实现了稀疏模式的动态自适应,既保证了全局信息的覆盖,又兼顾了局部细节的精确捕捉。
端到端可训练性:NSA将稀疏注意力机制原生集成到预训练和下游任务中,避免了传统稀疏方法在训练与推理阶段不一致的问题。
硬件友好性:NSA在算法设计时充分考虑了GPU等硬件的并行计算特性,通过算术强度平衡和内存访问优化,实现了高效的工程落地。
6.2 NSA机制的工程实现与优化策略
6.2.1 算法流程与关键模块
NSA的工程实现可分为以下几个关键模块:
Token压缩模块
通过聚合、降维等方式,将长序列中的token进行粗粒度压缩,减少后续注意力计算的规模。
全局上下文扫描模块
利用压缩后的token,快速扫描全局上下文,捕捉关键信息。
Token选择模块
基于全局扫描结果,动态选择需要重点关注的局部token,实现细粒度的信息检索。
稀疏注意力计算模块
对选定的token子集进行稀疏注意力计算,输出最终的上下文表示。
6.2.2 硬件对齐与性能优化
NSA在工程实现中,针对现代GPU的特点,采取了多项优化措施:
算术强度平衡:通过调整稀疏度和计算密集度,最大化GPU的利用率,避免内存带宽成为瓶颈。
内存访问优化:采用高效的数据布局和访问模式,减少内存访问延迟,提高整体吞吐量。
自定义内核实现:针对稀疏注意力的特殊计算模式,开发了自定义CUDA内核,进一步提升了计算效率。
6.2.3 端到端训练的稳定性保障
NSA在端到端训练过程中,引入了高效的反向算子,确保梯度计算的准确性和稳定性。通过与主流优化器(如Adam、LAMB等)的无缝集成,NSA能够在大规模分布式训练环境下,保持良好的收敛速度和模型性能。
6.3 NSA与主流稀疏注意力方法的对比分析
下表对比了NSA与主流稀疏注意力方法在关键维度上的表现:
NSA在动态性、端到端可训练性和硬件友好性等方面,均优于传统稀疏注意力方法,成为当前长上下文AI模型的首选架构之一。
七、NSA机制在长上下文任务中的应用与实战案例
%20拷贝.jpg)
7.1 多跳问答任务中的应用
7.1.1 任务背景与挑战
多跳问答(Multi-hop QA)任务要求模型在多个文档或长文本中,跨越多个推理步骤,整合分散的信息,最终给出准确答案。传统全注意力模型在处理超长文本时,往往因计算瓶颈而难以胜任。
7.1.2 NSA的优势与表现
NSA通过动态分层稀疏策略,有效聚焦于与问题相关的关键信息,大幅提升了多跳问答的准确率。实验数据显示,NSA在HPQ和2Wiki数据集上的准确率分别提升0.087和0.051,显著优于全注意力和其他稀疏注意力基线。
7.2 代码理解与段落检索任务
7.2.1 代码理解任务(LCC)
在代码理解任务中,模型需在长代码片段中定位关键逻辑、变量关系等。NSA通过高效的全局扫描与局部检索,提升了模型对复杂代码结构的理解能力,准确率提升0.069。
7.2.2 段落检索任务(PassR-en)
段落检索任务要求模型在超长文档中,快速定位与查询相关的段落。NSA在64k“大海捞针”测试中,实现了全位置100%检索准确率,充分展现了其在长文本检索场景下的卓越性能。
7.3 与链式思维推理范式的结合
链式思维(Chain-of-Thought, CoT)推理范式,近年来在复杂推理任务中表现突出。NSA与CoT范式的结合,使得模型能够在长上下文中,分阶段、分层次地进行推理,进一步提升了推理深度和准确性。
八、NSA机制的未来发展方向与挑战
8.1 技术演进的可能路径
8.1.1 稀疏模式的自适应进化
未来,NSA有望进一步引入自监督学习、元学习等机制,实现稀疏模式的自适应进化,使模型能够根据任务和数据的不同,动态调整稀疏策略,提升泛化能力。
8.1.2 跨模态与多模态扩展
随着多模态AI的发展,NSA机制有望扩展到文本-图像、文本-音频等跨模态场景,实现更高效的多模态长上下文建模。
8.2 工程落地的挑战与对策
8.2.1 大规模分布式训练的工程难题
NSA在大规模分布式训练环境下,需解决稀疏计算的负载均衡、通信优化等工程难题。未来,结合高效的分布式调度与稀疏通信协议,将进一步提升NSA的工程可用性。
8.2.2 行业应用的定制化需求
不同行业对长文本处理的需求各异。NSA需根据具体应用场景,定制稀疏策略和模型结构,确保在法律、金融、医疗等高价值场景下的最佳表现。
九、NSA机制的社会影响与伦理思考
%20拷贝.jpg)
9.1 AI长文本理解的社会价值
NSA推动了AI在长文本理解、复杂推理等领域的能力跃升,为法律判决、金融分析、医学文献解读等社会关键领域提供了强大技术支撑。
9.2 算法公平性与透明性
随着AI模型在社会决策中的应用日益广泛,NSA等新一代机制需关注算法的公平性与透明性,确保模型在处理长文本时,不引入新的偏见或歧视。
9.3 人才培养与创新生态
NSA的成功,彰显了中国AI创新生态的活力。企业与高校的深度合作,为青年人才提供了广阔的成长空间,也为全球AI技术创新注入了新鲜血液。
结语
NSA机制的提出与落地,标志着长上下文AI模型进入了全新发展阶段。以DeepSeek为代表的中国AI团队,正以创新驱动、工程落地和人才培养为核心,推动全球NLP技术的持续进步。未来,NSA有望成为长文本AI的主流架构,助力AI在更多复杂场景下实现智能化升级。中国NLP的国际影响力也将持续提升,为全球AI技术创新注入新的动力。
📢💻 【省心锐评】
“NSA的颠覆性在于将‘不可能三角’变为可能:在扩展上下文窗口的同时提升速度与精度。这不仅是工程胜利,更揭示了稀疏化才是大模型通向AGI的必经之路。”

评论