.png)


【摘要】SEAP技术以人脑“按需激活”为灵感,实现了大语言模型的动态、任务自适应剪枝,极大提升推理效率并降低能耗,为AI模型普及和绿色发展提供了新范式。
引言
在人工智能技术飞速发展的今天,大语言模型(LLM)已成为推动自然语言处理、智能对话、自动问答等领域变革的核心引擎。然而,随着模型规模的不断膨胀,庞大的参数量和高昂的计算资源消耗,成为制约其普及和落地的主要瓶颈。如何让大模型既保持强大的智能能力,又能高效、低耗地运行在各种终端设备上,成为学术界和产业界共同关注的难题。
2025年3月,中国人民大学与上海高级算法研究院的研究团队联合提出了SEAP(Sparse Expert Activation Pruning,稀疏专家激活修剪)技术。这项创新成果以人脑“按需激活”机制为灵感,首次实现了大语言模型的动态、任务自适应剪枝。SEAP不仅显著提升了模型推理效率,降低了能耗,还为AI模型的普及和绿色发展提供了全新范式。本文将从SEAP的技术原理、创新机制、实验表现、行业意义、局限性与未来展望等多个维度,深入剖析这一前沿技术,力求为读者呈现一幅完整、立体的SEAP技术图景。
一、SEAP技术简介与核心创新
%20拷贝.jpg)
1.1 人脑启发的“按需激活”机制
1.1.1 认知神经科学的启示
人类大脑以极高的能效完成复杂的认知任务,其奥秘之一在于“按需激活”机制。不同任务会激活大脑中不同的功能区。例如,数学运算主要激活顶叶皮层,语言理解则依赖颞叶区域。这种选择性激活让大脑能够以有限的能量,完成多样且复杂的任务。
1.1.2 LLM中的“专家分工”现象
SEAP团队通过实验证明,大语言模型内部同样存在“专家分工”现象。不同类型的任务输入会激活模型中不同的神经元群,这些“专家神经元”在功能上呈现聚类趋势。如下表所示,不同任务激活的神经元分布具有明显的分工特征:
1.1.3 理论基础与创新突破
这一发现为SEAP的动态剪枝提供了坚实的理论基础。通过模拟人脑的“按需激活”,SEAP能够让大模型在不同任务下只激活必要的神经元,大幅减少无效计算,实现高效推理。
1.2 训练免费、任务自适应的剪枝流程
1.2.1 无需重新训练的技术优势
传统的模型剪枝方法往往需要对原始模型进行重新训练,耗时耗力。SEAP则是一种“训练免费”的剪枝技术,无需对原始模型进行任何再训练,极大降低了技术应用门槛和部署成本。
1.2.2 剪枝流程详解
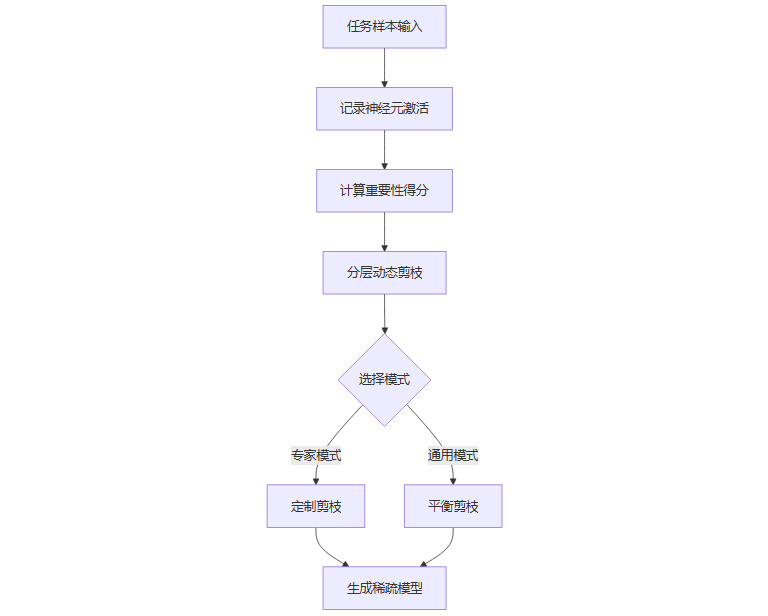
SEAP的核心流程包括以下几个步骤:
构建任务特定知识库
收集多种任务样本,输入模型,记录各神经元的激活强度,识别出“专家神经元”。计算重要性得分
基于神经元的活跃度、稳定性及权重,量化其对特定任务的关键性。分层动态剪枝
采用logistic函数等策略,浅层保留更多神经元,深层可更激进剪枝,实现分层稀疏分配。双模式支持
专家模式:针对特定任务定制剪枝方案,极致优化单一场景。
通用模式:多任务平衡剪枝,适用于综合应用场景。
1.2.3 SEAP剪枝流程图
1.3 动态激活与休眠机制
1.3.1 智能开关式推理
SEAP根据输入任务类型,自动选择激活相应“专家团队”,关闭无关神经元,实现“智能开关”式的高效推理。例如,处理数学问题时仅激活数学专家神经元,极大减少无效计算。
1.3.2 任务分类器的自动化支持
为实现自动化部署,SEAP配备了高准确率的任务分类器。该分类器能够快速识别用户输入的问题类型,并自动选择合适的专家模式,支持模型在实际应用中的高效切换。
二、SEAP的实验表现与技术优势
2.1 推理效率与性能表现
2.1.1 实验平台与任务设置
SEAP团队在Llama-2-7B和Llama-2-13B等主流大模型上进行了系统性实验,涵盖常识推理、数学问题、科学问答等七类任务,全面评估了SEAP的性能与效率。
2.1.2 主要实验结果
剪掉20%神经元时:性能仅下降2.2%,推理速度提升近50%。
剪掉50%神经元时:SEAP性能比WandA、FLAP等同类方法高出20%以上,推理速度提升也超过50%。
2.1.3 性能损失极小的原因
SEAP通过任务自适应剪枝,能够精准保留对当前任务最关键的神经元,避免了传统“一刀切”方法带来的性能大幅下降。
2.2 训练免费与自动化部署
2.2.1 降低技术门槛
SEAP无需对原始模型进行再训练,极大降低了技术应用门槛和部署成本。对于企业和开发者而言,SEAP的易集成特性意味着可以快速将其应用于现有AI系统中。
2.2.2 自动化任务分类与切换
SEAP内置的任务分类器准确率高达93%,能够自动识别任务类型并切换到最优的专家模式,支持多任务场景下的高效运行。
2.3 基础能力与可靠性验证
2.3.1 困惑度测试
在WikiText-2等数据集上,SEAP剪枝后的模型基础语言能力(如困惑度)影响极小,验证了其在保持任务特定性能的同时,对模型基础能力的影响可控。
2.3.2 多任务协同效应
实验还发现,在某些情况下,通用模式的SEAP甚至比专家模式表现更好,提示不同任务之间可能存在有益的相互促进作用。这一现象反映了语言理解的复杂性和知识的内在关联性。
三、SEAP的行业意义与深层价值
%20拷贝.jpg)
3.1 大幅降低AI模型部署门槛
3.1.1 资源受限设备的普及
SEAP让原本只能在高性能服务器上运行的大模型,有望在个人电脑、手机等资源受限设备上高效运行,极大推动了AI技术的普及化。
3.1.2 赋能边缘计算与移动端
随着物联网和移动互联网的发展,边缘计算和移动端AI需求日益增长。SEAP的高效剪枝能力,为这些场景下的大模型部署提供了可行路径。
3.2 节能减排,助力绿色AI
3.2.1 降低能耗的技术路径
通过“聪明偷懒”,SEAP显著降低了AI推理过程中的能耗,契合全球可持续发展与碳中和目标。
3.2.2 环保与社会价值
在全球日益关注碳排放和能源消耗的背景下,SEAP的推广应用具有重要的社会价值,为绿色AI发展提供了技术支撑。
3.3 支持AI个性化与定制化
3.3.1 专家模式的个性化优化
用户可根据自身主要应用场景,定制专属“专家模式”AI助手,获得更高效、更贴合需求的智能服务。
3.3.2 通用模式的多场景适应
对于需要处理多种任务的用户,SEAP的通用模式能够在保证性能的同时,实现多任务的平衡优化。
3.4 推动AI优化范式转变
3.4.1 从“暴力计算”到“智能计算”
SEAP代表了AI模型优化思路的根本性转变,从传统的“暴力计算”走向“智能计算”,开创了任务自适应优化的新领域。
3.4.2 激发行业创新与专用模型研究
SEAP的创新机制为医疗、金融等行业的专用模型研究提供了新思路,推动AI技术在垂直领域的深度应用。
四、SEAP的局限性与未来展望
%20拷贝.jpg)
4.1 通用能力与泛化性挑战
4.1.1 任务特定优化的局限
SEAP在极致优化特定任务时,可能导致模型在处理陌生任务时灵活性略有下降。未来需进一步提升模型的泛化能力,确保在多样化场景下的稳定表现。
4.1.2 多轮对话与混合任务的挑战
在多轮对话、混合任务等复杂场景下,如何实现专家模式的智能切换,仍是SEAP需要攻克的技术难题。
4.2 数据依赖性与多样性提升
4.2.1 标准数据集的局限
当前SEAP主要依赖标准数据集进行任务特定激活数据的收集,难以完全覆盖实际应用中的多样化需求。
4.2.2 合成数据与自动化采集
未来可结合数据合成与自动化采集技术,生成更丰富多样的训练样本,提升模型的任务多样性与泛化能力。
4.3 自动化与智能化机制优化
4.3.1 任务分类器的智能升级
尽管SEAP的任务分类器准确率已达93%,但在极端复杂场景下,仍需进一步提升其智能化水平,实现更精准的专家模式切换。
4.3.2 机制优化的研究方向
未来可探索基于元学习、强化学习等前沿技术,进一步优化SEAP的动态激活与休眠机制,提升其在复杂环境下的自适应能力。
4.4 商用化与落地前景
4.4.1 研究阶段与应用前景
目前SEAP尚处于研究阶段,尚未大规模商用。但其训练免费、易集成的特性,使其具备快速落地的潜力,尤其适合移动端和资源受限设备。
4.4.2 行业应用的广阔空间
随着AI技术的不断演进,SEAP有望在智能助手、智能客服、医疗诊断、金融分析等多个领域实现规模化应用,推动AI技术的普及与深化。
结论
SEAP技术以人脑“按需激活”为灵感,创新性地实现了大语言模型的动态、任务自适应剪枝,极大提升了推理效率并降低能耗。其“训练免费”、高性能、易部署等特性,为AI模型的普及和绿色发展提供了新范式。尽管在泛化能力和复杂场景适应性上仍有提升空间,SEAP无疑为AI行业带来了更高效、更智能的发展方向,具有广阔的应用前景和深远的社会价值。未来,随着数据多样化和机制优化的不断推进,SEAP有望在更多实际场景中发挥更大作用,助力AI技术迈向更高效、更绿色、更智能的新时代。
📢💻 【省心锐评】
“SEAP技术是AI效率优化的里程碑,任务自适应思路令人振奋,期待其早日商用,助力行业迈向智能计算新时代!”

评论