.png)


【摘要】一项牛津大学领衔的研究揭示了大型语言模型普遍存在的“深度诅咒”现象,即深层网络贡献度递减。文章深入剖析其根源在于Pre-LN架构导致的方差爆炸,并详细介绍了一种创新的层归一化缩放(LNS)技术,该技术能有效激活深层网络,显著提升模型效率与性能。
引言
在人工智能的浪潮之巅,大型语言模型(LLM)无疑是最耀眼的明星。我们见证了模型参数从百万、千万到千亿、万亿的飞跃,也习惯了一个朴素的信念——模型越深,能力越强。这个信念如同摩天大楼的地基,支撑着整个领域的架构设计哲学。我们不断投入惊人的计算资源,像建造巴别塔一样,将模型的层数堆得更高,期望它能触及通用人工智能的苍穹。
但是,现实果真如此吗?
一项由牛津大学刘世伟教授团队领衔,联合西湖大学、埃默里大学等多所顶尖学府的合作研究,向这个根深蒂固的观念发起了颠覆性的挑战。他们于2025年7月发表的论文《大型语言模型中的深度困境》,如同一道惊雷,划破了AI研究界的宁静。这篇论文系统性地揭示了一个普遍存在却一直被忽视的现象——“深度诅咒”(The Curse of Depth)。
研究发现,在当前主流的LLM中,深层网络并非我们想象中那般勤勉。它们更像是一群“懒惰的工匠”,在智慧大厦的高层消极怠工,几乎不产生新的价值。这意味着,我们为训练这些深层网络所付出的巨额算力、能源和时间,很大一部分都付诸东流。
这篇文章将带你深入这篇重磅研究的内核。我们将一起探寻“深度诅咒”的蛛丝马迹,揭开其背后的理论根源,并详细解读研究团队提出的那个简洁而强大的解决方案——层归一化缩放(LayerNorm Scaling, LNS)。这不仅是一次技术细节的剖析,更是一场对现有LLM架构设计的深刻反思。
一、🏛️ “深度诅咒”的幽灵,盘旋在大型模型之上
%20拷贝.jpg)
长久以来,深度学习的“深度”二字几乎与“强大”划等号。从AlexNet的8层到ResNet的上百层,再到Transformer架构动辄数十上百层的堆叠,增加深度一直是提升模型性能的核心手段。然而,牛津团队的研究却告诉我们,在LLM的世界里,这条路似乎走到了一个奇怪的拐点。
1.1 现象初探,智慧大楼的“懒惰工匠”
研究团队的第一个发现就足以让人震惊。他们设计了一系列巧妙的“外科手术式”实验,对多个主流LLM家族(包括Llama、Mistral、DeepSeek和Qwen)进行层层剖析。实验方法简单直接,就是逐一或分块地移除模型的Transformer层,然后观察模型性能的变化。
结果出乎所有人的预料。
移除深层网络,性能波澜不惊。当研究人员移除模型最顶部的多个层级时,模型的整体表现几乎没有受到影响。在某些测试案例中,性能甚至还出现了微乎其微的提升。这就像一座宏伟的智慧大楼,你拆掉了顶上的好几层,大楼的整体功能却丝毫未损。这明确地指向一个结论,这些深层网络几乎是“冗余”的。
移除浅层网络,性能瞬间崩塌。与深层网络形成鲜明对比的是,只要移除靠近输入端的任何一个浅层网络,模型的性能就会立刻出现断崖式下跌。这说明浅层网络承担了模型最核心、最基础的特征提取和表示学习功能,是整个智慧大楼不可或缺的承重墙。
这个现象被研究团队生动地比喻为**“智慧大楼里的懒惰工匠”**。每一层Transformer本应是一位技艺精湛的工匠,对输入的信息进行加工、提炼,然后传递给下一位工匠。然而,现实却是,底层的工匠们兢兢业业,而高层的工匠们却几乎在“摸鱼”,只是将楼下传递上来的半成品原封不动地再往上传递。
这种**“高层无效性”**,就是“深度诅咒”最直观的表现。它意味着我们投入巨大成本构建的“摩天大楼”,其有效高度可能远低于设计高度。大量的计算资源被浪费在这些“消极怠工”的深层网络上,这在追求极致效率和绿色计算的今天,无疑是一个亟待解决的严峻问题。
1.2 实验证据,诅咒的普适性验证
为了确保这一发现不是偶然,研究团队在多个当前最流行的开源LLM家族上重复了他们的实验。这覆盖了不同的架构变体和训练数据,结果惊人地一致。
这张表格清晰地展示了“深度诅咒”的普适性。它并非某个特定模型的“专利”,而是广泛存在于当前主流LLM设计范式中的一个系统性问题。无论模型的“血统”如何,似乎都难以逃脱这个幽灵的纠缠。
这一系列坚实的实验证据,将“深度诅咒”从一个模糊的猜想,变成了一个有数据支撑、不容忽视的客观事实。它迫使整个AI社区必须正视一个问题,我们真的理解“深度”在LLM中扮演的角色吗?
1.3 数学透视,层间信息的冗余之谜
直观的现象背后,必然有其深刻的数学原理。为了从理论层面理解为何深层网络会“偷懒”,研究团队引入了一个关键的度量工具——角度距离(Angular Distance)。
角度距离可以用来衡量两个向量在方向上的差异。如果两个向量的角度距离接近于0,意味着它们的方向几乎完全一致。研究团队利用这个工具来测量模型中相邻两个Transformer层输出表示(Output Representations)之间的相似性。
分析结果再次印证了此前的猜想。
在浅层网络中,相邻两层的输出表示之间存在着显著的角度距离。这表明每一层都在对信息进行有效的、非平凡的转换和加工,产生了新的、有价值的语义表示。信息在这里是流动和演化的。
然而,在深层网络中,情况发生了戏剧性的变化。相邻两层的输出表示之间的角度距离迅速趋近于0。这意味着,从某一深度开始,后续的层级几乎不再对输入进行任何有意义的转换。它们只是在机械地“复刻”前一层的输出。信息流在这里陷入了停滞,产生了严重的信息冗余。
这个发现从数学上解释了“懒惰工匠”的行为模式。深层网络之所以可以被移除而性能不受影响,正是因为它们的工作本质上只是一个“恒等变换”(Identity Transformation),输入什么,就输出什么。它们没有为模型贡献任何新的知识或能力,自然也就成了可以被轻易拿掉的“赘余”。
至此,“深度诅咒”的现象、普适性和数学表征都已清晰。但一个更深层次的问题浮出水面,这个诅咒究竟从何而来?是什么样的机制,导致了现代LLM架构会系统性地陷入这种深层冗余的困境?
二、🔬 追根溯源,Pre-LN架构的原罪
要解开“深度诅咒”的谜团,就必须深入到Transformer架构的心脏地带——层归一化(Layer Normalization, LN)的设计。正是这个看似不起眼的模块,成为了问题的关键。
2.1 两种归一化范式,Pre-LN与Post-LN的对决
在Transformer的演化史中,关于层归一化(LN)的放置位置,一直存在两种主流方案,它们之间的差异虽小,却对模型的行为产生了深远影响。
后置层归一化(Post-LN)
这是最初Transformer论文中采用的经典设计。LN层被放置在残差连接(Residual Connection)之后。它的数据流可以简化为x + SubLayer(x)之后再进行归一化。前置层归一化(Pre-LN)
这是后来被广泛采用的改进设计。LN层被放置在残差连接之前,即在自注意力(Self-Attention)或前馈网络(FFN)这些子层(SubLayer)的输入端。其数据流简化为x + SubLayer(LN(x))。
我们可以用一个流程图来更清晰地展示它们的区别。
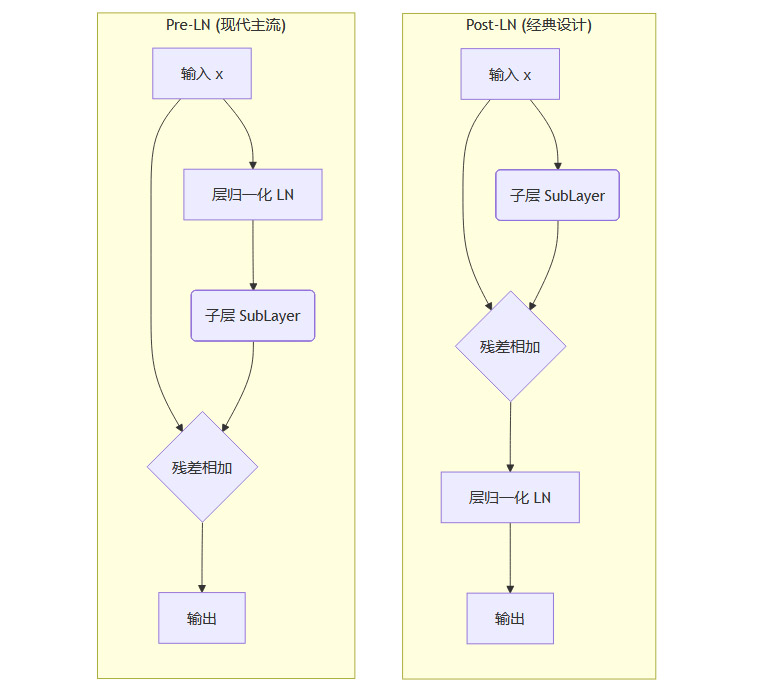
Pre-LN架构之所以能成为现代LLM(如GPT系列、Llama系列)的标配,是因为它展现出了更优越的训练稳定性。在Post-LN架构中,随着网络加深,梯度容易出现爆炸或消失的问题,导致训练过程非常脆弱,需要精细的超参数调整和学习率预热(Warmup)。而Pre-LN通过在主干路径上直接传递未经处理的梯度,极大地稳定了训练过程,使得训练更深、更大的模型成为可能。
然而,正是这份“稳定”的馈赠,在暗中标好了价格。研究团队通过对比实验发现,采用Post-LN架构的模型,不仅没有出现“深度诅咒”,反而表现出深层比浅层更重要的相反趋势。这个惊人的对比,将所有疑点都聚焦到了Pre-LN架构本身。它在提供稳定性的同时,似乎也埋下了一颗导致深层网络失效的“定时炸弹”。
2.2 方差爆炸,深层网络的“透明化”危机
为了揭开Pre-LN架构的“原罪”,研究团队对其进行了深入的理论分析,最终定位到了一个核心问题——输出方差的指数级增长。
在Pre-LN架构中,每一层的输出都是前一层的输出 x 与经过子层处理后的 SubLayer(LN(x)) 相加。由于LN层会将输入的方差归一化到1附近,SubLayer 的输出方差相对可控。但是,残差连接的主干路径上的 x 的方差是逐层累积的。
简单来说,每一层输出的方差,约等于输入方差加上一个常数。这个过程在数学上构成了一个累加序列。当模型层数 L 变得很大时,第 L 层的输出方差会与 L 呈线性关系。由于模型的输出范数(magnitude)与方差的平方根成正比,这意味着模型深层输出的范数会随着层数 L 的增加而以 √L 的速度增长。
这个增长带来了灾难性的后果。
当一个向量的范数变得非常大时,它在残差连接中会占据主导地位。x + SubLayer(LN(x)) 的结果会无限趋近于 x 本身,因为 SubLayer(LN(x)) 的贡献相比之下变得微不足道。
这导致了深层网络的**“透明化”**。这些层级几乎变成了“透明”的管道,输入什么,就近乎原样地输出什么。它们不再对信息进行有效的加工和转换,学习能力被严重抑制。
更进一步的数学推导表明,这种范数的增长会导致网络的雅可比矩阵(Jacobian Matrix)趋近于单位矩阵。雅可比矩阵描述了网络的输入变化如何影响输出变化,是梯度计算的核心。当它趋近于单位矩阵时,意味着反向传播的梯度也会原封不动地通过这些层,这些层对梯度的调整作用几乎为零,从而无法进行有效的参数更新。
这就是“深度诅咒”的理论根源。Pre-LN架构为了追求训练稳定性,牺牲了深层网络的表达能力。随着层数的增加,这种结构性缺陷被不断放大,最终导致了深层网络的集体“怠工”。
2.3 理论推导,诅咒背后的数学原理
为了让这个过程更具体,我们可以想象一个简化的信号传递过程。
初始信号。在第一层,输入信号
x_0具有一定的能量(方差)。第一层处理。输出
x_1 = x_0 + SubLayer(LN(x_0))。x_1的能量约等于x_0的能量加上一个小的增量。第二层处理。输出
x_2 = x_1 + SubLayer(LN(x_1))。x_2的能量约等于x_1的能量再加上一个增量。...第L层处理。输出
x_L的能量已经累积了L次增量,变得非常巨大。
此时,在第 L+1 层,输入是能量巨大的 x_L。SubLayer(LN(x_L)) 虽然经过了归一化,其能量相对固定,但与 x_L 相比就像是大海里的一滴水。所以 x_{L+1} = x_L + SubLayer(LN(x_L)) 的结果几乎就等于 x_L。
这个恶性循环一旦开始,后续所有层都将失去作用。它们只是在不断地传递一个能量越来越大的、几乎不再变化的信号。模型虽然在物理上很“深”,但在功能上却变得很“浅”。
相比之下,Post-LN架构 LN(x + SubLayer(x)) 的设计,在每次残差连接后都进行一次归一化,强制将每一层的输出方差拉回到一个稳定的水平。这虽然可能导致梯度不稳定,但也确保了每一层都有机会对信息进行处理,避免了方差的失控累积。
现在,病灶已经找到。Pre-LN架构的结构性缺陷是导致“深度诅咒”的元凶。那么,有没有一种方法,既能保留Pre-LN的训练稳定性,又能治愈其深层网络失效的顽疾呢?
三、💡 破解魔咒,简洁而强大的LNS技术
%20拷贝.jpg)
面对Pre-LN架构这一棘手的“结构性缺陷”,一个直接的想法是回归Post-LN。但这无异于因噎废食,我们将重新面临训练不稳定的困境,这对于动辄千亿、万亿参数的现代LLM来说是不可接受的。
研究团队的目标非常明确,找到一种方法,能够在不破坏Pre-LN稳定性的前提下,抑制住方差的失控增长。经过深入的理论探索和实验,一个优雅而简洁的解决方案应运而生——层归一化缩放(LayerNorm Scaling, LNS)。
3.1 核心思想,给方差套上“缰绳”
LNS技术的核心思想极其简单,在每次Pre-LN操作之后,对残差分支的输出进行一次缩放。具体来说,就是给每个Transformer子层(自注意力或FFN)的输出乘以一个与层深度相关的缩放因子。
这个缩放因子被设定为一个非常特定的值。对于第 l 层(l 从1开始计数),其缩放因子 α_l 为:
α_l = 1 / √l
也就是说,第一层的输出乘以 1/√1 = 1,第二层的输出乘以 1/√2,第三层的输出乘以 1/√3,以此类推。层数越深,这个缩放因子就越小。
经过LNS改造后的Pre-LN数据流变成了 x + (1/√l) * SubLayer(LN(x))。
这个小小的改动,就像是给狂奔的方差套上了一根精准的“缰绳”。它通过逐层递减的缩放,主动去抵消方差在残差连接主干路径上的累积效应。
3.2 理论分析,从指数增长到多项式增长
LNS为何能起作用?其背后的数学原理同样坚实。
我们之前分析过,在标准的Pre-LN架构中,输出方差与层数 L 呈线性关系 Var(x_L) ≈ c * L。而LNS的引入,彻底改变了这个增长动态。
经过LNS缩放后,每一层增加的方差不再是一个常数,而是 (1/√l)² = 1/l。那么,第 L 层输出的总方差,就约等于所有前面层级增加的方差之和,即 Σ(1/l) 从 l=1 到 L。
这个级数在数学上被称为调和级数。当 L 很大时,调和级数的值约等于 ln(L),即 L 的自然对数。
这意味着,通过LNS技术,研究团队成功地将输出方差的增长速度,从与 L 线性相关,大幅降低到了与 ln(L) 对数相关。这是一个巨大的飞跃。它意味着即使模型深达数百上千层,其输出的范数也会被控制在一个非常温和的范围内,不会出现失控的指数级爆炸。
方差被有效控制后,深层网络的“透明化”危机自然就解除了。SubLayer 的输出不再是汪洋中的一滴水,而是能够持续对主干信息流产生有效影响的关键部分。每一层网络都能恢复其应有的学习和表达能力,梯度可以有效地在深层网络中传播和更新,沉睡的“懒惰工匠”被彻底唤醒。
3.3 实现之美,零成本的“即插即用”
LNS技术最令人称道的一点,是它的极致简洁和高效。
无需额外参数。它没有引入任何新的、需要学习的权重。缩放因子
1/√l是一个固定的、根据层索引计算得出的值。无需调整超参。开发者不需要为了适配LNS而去调整学习率、权重衰减等其他超参数。
计算开销极小。它仅仅是在前向传播中增加了一次数乘操作,这点计算开销对于整个Transformer的运算量来说完全可以忽略不计。
“即插即用”。在现有的代码库中实现LNS,往往只需要修改一行代码。
这种设计哲学体现了深刻的工程智慧。它在不增加模型复杂度和训练成本的前提下,精准地解决了核心问题。它保留了Pre-LN架构的所有优点(如训练稳定性),同时又完美地规避了其致命缺陷。
四、🚀 实验验证,LNS的惊人效果
理论上的完美,还需要实践的检验。研究团队进行了一系列详尽的实验,从多个维度验证了LNS技术的有效性。
4.1 预训练性能的显著提升
研究团队在不同规模的模型上,从头开始进行了预训练实验,对比了标准Pre-LN和应用了LNS的Pre-LN架构。评估指标是困惑度(Perplexity, PPL),这个值越低,代表模型对语言的建模能力越强。
结果令人信服。
从小型模型到工业级的7B模型,LNS在所有测试规模上都展现出了一致且显著的性能优势。特别是在训练初期,LNS的收敛速度更快,最终能达到更低的困惑度。这直接证明了LNS确实激活了深层网络的潜力,使得整个模型能够更有效地利用其所有参数进行学习。
4.2 下游任务的通用能力增强
一个好的预训练模型,不仅要在预训练指标上表现出色,更重要的是要在各种下游任务中展现出强大的泛化能力和通用性。
为了验证这一点,研究团队将使用LNS预训练的模型,在著名的Commonsense170K数据集上进行了微调。这个数据集覆盖了8个不同的常识推理任务,是检验模型通用推理能力的“试金石”。
实验结果再次表明了LNS的优越性。在全部8个推理任务上,经过LNS预训练的模型在微调后的表现,都明显优于使用标准Pre-LN预训练的基线模型。
这说明,LNS带来的提升并非仅仅是“刷榜”式的指标优化。它通过让模型更充分地利用其深度,实实在在地增强了模型的通用学习能力和推理能力。一个结构更健康、信息流更通畅的模型,自然能更好地学习和泛化到新的任务中去。
4.3 资源节约与巨大的经济价值
LNS的实际价值远不止于性能的提升。在大型模型训练成本日益高昂的今天,效率的提升意味着真金白银的节省。
这项研究的成果对工业界具有极高的吸引力。
更高性价比。在相同的计算预算和训练时间下,使用LNS可以训练出性能更强的模型。
更低成本。要达到与基线模型相同的性能水平,使用LNS可以显著减少所需的训练步数,从而大幅降低计算成本、能源消耗和碳排放。
考虑到训练一个顶级的LLM动辄需要数千万甚至上亿美元的投入,LNS带来的效率提升所对应的经济价值是不可估量的。它为构建更强大、更经济、更环保的AI系统提供了一条切实可行的路径。
五、🧐 学术与工程的深远启示
%20拷贝.jpg)
牛津大学团队的这项研究,其意义已经超越了提出一个具体的技术解决方案。它为整个深度学习领域,特别是LLM的设计和研究,带来了多方面的深刻启示。
5.1 对现有架构的重新审视
这项工作最核心的贡献之一,是它揭示了即便是像Pre-LN这样被广泛采纳、被认为是“标准实践”的架构设计,也可能潜藏着未被发现的根本性缺陷。
这提醒我们,不能将任何设计选择视为理所当然。AI领域的发展日新月异,过去的“最优解”在新的模型尺度和应用场景下,可能就不再适用。我们必须保持批判性的眼光,持续地用更深入的理论分析和更严谨的实验去审视和挑战现有的技术范式。
“深度诅咒”的发现,为未来LLM乃至其他深层神经网络的架构设计敲响了警钟。在追求更大、更深的模型时,必须仔细考量深度对模型内部动态(如方差、梯度流)的复杂影响,而不能简单地进行层数堆叠。
5.2 理论指导实践的典范
这项研究是理论分析指导工程实践的一次完美示范。它从一个反常的实验现象(深层无效)出发,通过严谨的数学推导(方差分析),精准地定位了问题的根源(Pre-LN的结构缺陷),并最终提出了一个理论上完备、实践上简洁的解决方案(LNS)。
整个过程逻辑链条清晰,环环相扣,展现了基础理论研究在推动技术突破中的强大力量。它鼓励研究者们不仅要关注“做什么”(What)和“怎么做”(How),更要深入探究“为什么”(Why)。
5.3 对未来模型设计的指导
LNS的成功,为未来的模型架构创新提供了一条宝贵的思路。即通过精巧的、非学习的机制来主动调节和稳定网络的内部动态,从而释放模型的全部潜力。
此外,研究中还提到了一些值得进一步探索的方向。
初始化策略的协同。研究团队发现,LNS与某些旨在稳定训练的缩放初始化策略(如
GPT-NeoX中使用的)可能存在冲突。当两者并用时,效果反而会下降。这提示我们在使用LNS时,最好移除这些额外的缩放初始化,以获得最佳性能。这说明不同模块之间的相互作用是复杂的,需要系统性的设计和考量。跨模态的潜力。团队在视觉Transformer(ViT)上对LNS进行了初步探索,发现它同样能带来性能提升。这预示着“深度诅咒”可能不仅仅是LLM的专属问题,而是所有采用Pre-LN架构的深度模型的共性问题。LNS或其变体,未来有望在计算机视觉、多模态等更广泛的领域中发挥作用,不过具体的实现可能需要根据不同任务和架构进行微调。
总结
牛津大学团队的这项研究,无疑是近年来LLM领域一项里程碑式的工作。它不仅揭示了困扰主流大模型的“深度诅咒”这一普遍性难题,更以其深刻的理论洞察和优雅的工程实现,为我们提供了破解魔咒的“银色子弹”——层归一化缩放(LNS)技术。
从发现“懒惰工匠”的惊人现象,到追溯Pre-LN架构的“原罪”,再到提出LNS这一简洁高效的解决方案,整个研究过程如同一部精彩的侦探小说,引人入胜。LNS的成功验证,不仅为我们带来了性能更强、效率更高的模型,更重要的是,它促使我们重新思考“深度”的真正含义,推动整个领域向着更健康、更可持续的方向发展。
在AI技术狂飙突进的时代,这样的研究显得尤为珍贵。它告诉我们,真正的突破往往不来自于更大规模的堆砌,而来自于对基础原理更深刻的理解。
📢💻 【省心锐评】
别再盲目堆层了!牛津这项研究直击LLM训练浪费的痛点,LNS用一行代码唤醒沉睡的算力,让每一分投入都掷地有声。

评论