.png)


【摘要】OmniGen2由北京人工智能研究院团队研发,采用创新的双轨制架构和自我反思机制,极大提升了AI文生图、图像编辑与情境生成的能力。本文深度解析其技术原理、数据体系、评测标准、实际表现及未来展望,全面展示OmniGen2在多模态AI领域的突破与价值。
引言
🎨🧠 近年来,AI文生图技术如雨后春笋般涌现,从最初的GAN到扩散模型,再到多模态大模型,AI生成内容(AIGC)正以前所未有的速度重塑内容创作、设计、娱乐、教育等行业。然而,现有的AI图像生成工具往往各有所长,难以兼顾多任务、多场景的需求。更重要的是,绝大多数模型缺乏“自我反思”与持续优化的能力,用户体验常常受限于“试错—重试”的低效循环。
2025年6月,北京人工智能研究院(BAAI)吴晨原、郑鹏飞、闫瑞然、肖世涛等团队发布了OmniGen2(论文arXiv:2506.18871v1),以“全能大厨”式的创新思路,打破了多模态生成的壁垒。OmniGen2不仅实现了文生图、图像编辑、情境生成等多任务统一,还引入了AI自我反思机制,极大提升了生成质量与用户交互体验。本文将从架构创新、数据体系、评测标准、性能表现、实际应用、技术细节与未来展望等多个维度,全面剖析OmniGen2的技术突破与行业意义。
一、🛤️双轨制设计:让专业的人做专业的事
%20拷贝.jpg)
1.1 设计理念的转变
1.1.1 “全能大厨”与“专精厨师”的比喻
在AI文生图领域,传统模型往往试图用一套参数体系同时处理文本理解与图像生成,类似让一个厨师既写菜单又下厨,结果往往顾此失彼。OmniGen2则采用了“双厨房”设计:
一个“厨房”专注于文本理解与生成(自回归文本建模)
另一个“厨房”专注于图像创作(扩散图像生成)
这种分工协作的架构,极大提升了各自任务的表现力和灵活性。
1.1.2 术业有专攻:实验发现
团队在实验中发现,盲目提升语言模型能力反而会损害图像生成质量。正如顶级文学评论家未必能画好画,OmniGen2选择让“莎士比亚”和“达芬奇”各司其职,分别用独立参数处理文本与图像,互不干扰。
1.2 架构实现
1.2.1 双路径独立建模
文本路径:自回归文本建模,专注于理解和生成复杂文本指令。
图像路径:扩散模型专注于高质量图像生成,采用独立的参数体系。
1.2.2 分层图像编码
OmniGen2采用ViT(视觉变换器)理解图像语义,VAE(变分自编码器)捕捉细节特征。
ViT:负责整体语义(如“猫坐在沙发上”)
VAE:关注细节(如“猫毛质感”、“沙发布料纹理”)
1.2.3 三维位置编码Omni-RoPE
传统位置编码仅为像素编号,难以应对多图像、多对象任务。OmniGen2创新性地引入三维位置编码(Omni-RoPE):
这种设计如同“门牌号+楼层+房间号”,既能区分不同建筑,又能精确定位内部房间。
二、🌱数据工厂:从源头保证食材新鲜
2.1 数据质量的核心地位
2.1.1 现有数据集的局限
开源数据集如同“隔夜蔬菜”,在图像编辑与情境生成任务上质量堪忧,难以支撑高质量模型训练。
2.2 视频驱动的数据采集
2.2.1 从视频中提取高质量样本
视频天然包含同一对象在不同条件下的多样表现,为模型提供丰富的学习素材。OmniGen2团队建立了“数据农场”,以视频为源,提取关键帧,识别主要对象,定位与分割,形成高质量训练样本。
2.2.2 数据采集流水线
流程图如下:
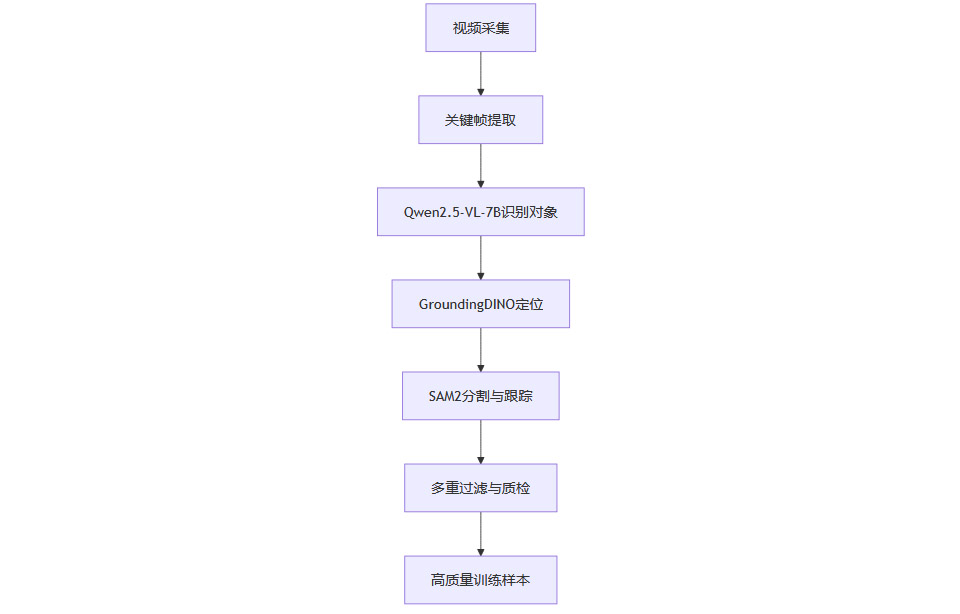
2.2.3 多重质检机制
DINO相似性过滤
VLM一致性检查
多轮人工与自动质检
2.3 图像编辑与反思数据的创新构建
2.3.1 逆向工程法
先制作图像对,再让AI描述编辑过程,避免指令与实际效果不匹配。
2.3.2 反思数据生成
模型生成图像后自我评判,发现问题后分析原因并提出改进方案,形成“自我批改作业”的闭环。
三、🏆全能测试:OmniContext基准的诞生
%20拷贝-vktl.jpg)
3.1 评测标准的创新
3.1.1 现有评测的不足
传统评测如“小学数学题考大学生”,难以全面衡量情境生成能力。
3.2 OmniContext基准测试
3.2.1 设计理念
覆盖人物、物体、场景三大类别
八个细分任务,每任务50个测试案例
兼顾内容准确性与图像质量
3.2.2 评测流程
3.2.3 评分维度
指令遵循度:图像是否准确执行文本要求
主体一致性:生成对象是否与参考图像保持一致
3.3 测试结果
OmniGen2在OmniContext基准测试中总分7.18(满分10),开源模型中排名第一。
单一对象任务:7.81分
多对象任务:7.23分
场景任务:6.71分
四、🔄反思机制:会自我改进的AI
4.1 反思机制的原理
4.1.1 多轮自我检查与优化
生成图像后,OmniGen2自动检查是否符合指令要求,发现问题后分析原因并重新生成,直至满足要求或确认无误。
4.1.2 典型应用场景
数量要求(如“四个红苹果”)
颜色、形状等细节要求
多轮反思,逐步逼近最优结果
4.2 反思机制的优势与局限
4.2.1 优势
显著提升复杂指令下的生成准确率
降低用户试错成本
支持多轮交互优化
4.2.2 局限
可能出现“过度反思”,对正确结果提出不必要修改
简单任务时增加不必要复杂性
五、📊性能表现:数据说话的实力证明
%20拷贝-vent.jpg)
5.1 视觉理解与生成能力
5.2 文生图与复杂指令处理
5.3 图像编辑能力
5.4 情境生成能力
OmniContext基准测试:
总分7.18,开源模型第一
单一对象7.81,多对象7.23,场景6.71
5.5 参数与数据效率
OmniGen2仅用40亿参数、1500万张图片,达到BAGEL(140亿参数、16亿图片)相近水平,效率极高。
六、🛠️实际应用:从实验室到现实世界
6.1 文生图的多场景适应
支持多种图像比例(方形、宽屏、竖版等)
复杂场景构建与高质量输出
6.2 图像编辑的灵活性
局部修改(如衣服颜色、添加装饰)
整体风格转换(如照片转动漫)
场景替换(如人物移至新背景)
6.3 情境生成的个性化创作
用户上传照片,生成多样场景(如宠物猫在埃菲尔铁塔前)
适用于社交媒体、纪念品制作等
6.4 反思机制的实际价值
用户无需反复试错,系统自动优化
显著提升交互体验与生成效率
6.5 使用限制与改进空间
中文指令支持不如英文稳定
低质量输入图像影响输出
多图像源复杂指令易混淆
人体形态修改、图像文字编辑等任务有待提升
七、🔬技术细节:深入了解工作原理
%20拷贝-ypgk.jpg)
7.1 架构与参数
基于Qwen2.5-VL-3B(30亿参数)多模态理解
扩散生成部分独立变换器,32层,2520隐藏维,40亿参数
修正流(Rectified Flow)高效生成
7.2 Omni-RoPE三维位置编码
7.3 分阶段训练策略
文字转图像任务预训练
混合任务训练
端到端反思能力训练
7.4 推理与数据处理流程
特殊标记触发图像生成
MLLM隐藏状态+VAE视觉特征输入扩散解码器
多重过滤确保数据高质量
八、🚀未来展望:走向更智能的多模态世界
8.1 模型规模与效率的平衡
探索更大规模模型,提升复杂推理能力
保持高效计算与资源利用
8.2 数据质量与多样性的提升
针对性采集文字编辑、人体形态等领域数据
更精细化的数据处理与标注
8.3 反思机制的智能化
引入强化学习,提升反思准确性与效率
避免过度反思与误判
8.4 多语言与全球化支持
加强中文等非英语指令支持
扩展多语言训练数据
8.5 开源生态与行业影响
持续开源模型、代码、数据集
促进全球AI社区协作与创新
结论
🧩OmniGen2以其创新的双轨制架构、全流程高质量数据体系、全能基准测试与自我反思机制,极大推动了多模态AI文生图技术的发展。它不仅在技术指标上实现了高效与高质的统一,更以开源姿态为行业树立了新标杆。未来,随着模型规模、数据多样性、反思智能化与多语言支持的持续提升,OmniGen2有望成为通用多模态AI的核心基石。对于开发者、内容创作者乃至普通用户而言,这意味着更强大、更智能、更易用的AI工具正加速到来。OmniGen2的探索与突破,预示着多模态AI迈向更高智能、更广应用的新纪元。
📢💻 【省心锐评】
OmniGen2开源即巅峰,双轨架构与反思机制让AI文生图进入全能新时代,值得每个开发者关注。

评论