.png)
(1).png)

【摘要】2025年高考AI大模型“考生”成绩放榜,豆包大模型1.6以文科683分、理科最高676分的优异表现,展现出超越人类学霸的多模态推理与深度思考能力。本文系统梳理评测流程、学科表现、技术创新与行业影响,深度剖析AI大模型在复杂认知任务中的突破与挑战,展望其在教育及多行业的广阔应用前景。
引言
2025年,人工智能大模型在高考这一极具挑战性的综合性考试中,首次以“考生”身份集体亮相,成为科技与教育领域的年度焦点。豆包大模型1.6(Seed 1.6-Thinking)以文科683分、理科最高676分的成绩,冲击清华、北大等顶尖学府的分数线,刷新了AI在复杂认知任务中的能力上限。与此同时,Gemini、DeepSeek、Claude等大模型也展现出接近人类优秀考生的实力。本文将以技术论坛的深度视角,系统梳理AI大模型高考评测的流程、学科表现、技术创新、国际对比与行业影响,全面剖析AI“学霸”背后的技术密码与未来图景。
一、📝 成绩盘点与排名:AI“学霸”横空出世
.png)
1.1 豆包大模型1.6:文理双优,冲击顶尖学府
2025年高考AI大模型评测中,豆包大模型1.6以文科683分、理科648分的原始成绩,成为本次测试的最大赢家。更为亮眼的是,在理科试卷更换高清图片后,豆包理科总分提升至676分,超越Gemini 2.5 Pro(655分),在山东省“3+3”高考赋分制下,豆包最高可达690分左右,模拟排名进入全省前80,具备冲击清华、北大等顶尖学府的实力。
1.2 其他大模型表现一览
Gemini 2.5 Pro:理科655分,文科略逊于豆包,整体表现稳居第一梯队。
DeepSeek R1:数学单科145分,成为数学单科冠军,理科综合表现优秀。
Claude:整体分数达到优秀学生水准,文理均衡。
OpenAI O3:因语文作文跑题,语文仅95分,拉低总分,显示出跨文化语境下的适应性挑战。
1.3 AI高考成绩对比表
注:理科总分“648/676”表示原始分与高清图片后分数。
二、🔍 评测标准与流程:严谨公正,拒绝“提示词优化”
2.1 试卷选择:全国新一卷与山东卷结合
本次AI大模型高考评测,主科(语文、数学、英语)采用2025年全国新一卷,副科(物理、化学、生物/政治、历史、地理)采用山东卷,满分750分,全面考察大模型的综合能力与泛化水平。
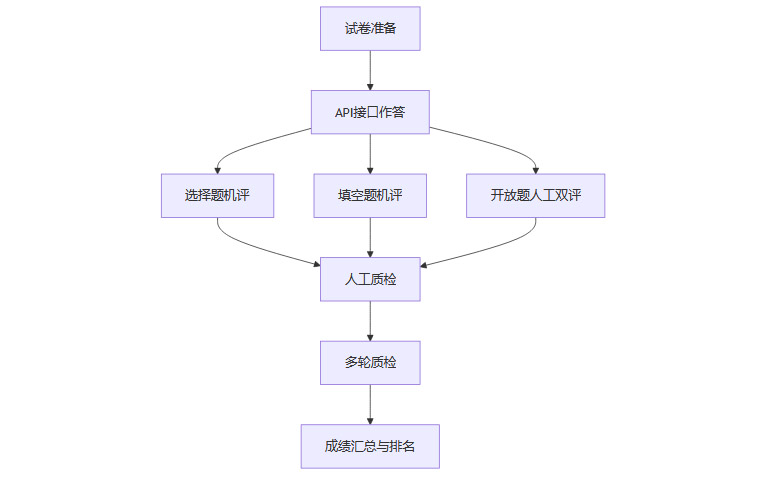
2.2 评分方式:机评+人工双重保障
API测试:所有模型均通过API接口作答,不联网查询,完全依赖模型自身泛化能力。
选择题、填空题:机评为主,人工质检,确保客观准确。
开放题(如作文、论述题):由两位有联考阅卷经验的重点高中教师匿名双评,多轮质检,确保评分公正。
提示词限制:全程未用任何提示词优化技巧,杜绝“投机取巧”,最大程度还原真实考场环境。
2.3 评测流程Mermaid流程图
三、📚 学科表现深度解析:优势与短板并存
.png)
3.1 理科:推理与多模态能力提升,图像识别为短板
3.1.1 数学:推理能力显著提升,细节把控待加强
豆包、DeepSeek、Gemini等大模型在数学科目上均能考到140分以上,DeepSeek R1以145分成为数学单科冠军。大模型在函数、概率、立体几何等高难度题型上展现出强大的推理与运算能力,解题思路清晰,步骤完整。然而,在全国一卷第6题(含复杂图像)上,所有模型均答错,显示出图像理解与题意还原能力的短板。此外,数学压轴题常因推导不严谨、漏写证明过程被扣分,细节把控有待进一步提升。
3.1.2 理综:多模态推理能力初显,图像清晰度影响得分
理综科目(物理、化学、生物)对多模态推理能力提出更高要求。豆包和Gemini的图像理解能力相对较强,能解析实验装置图、统计图等复杂图像,但在化学、生物等依赖图像的题目中,题图清晰度直接影响得分。更换高清图片后,豆包理科总分提升近30分,充分显示多模态推理能力对理科成绩的决定性作用。
3.1.3 细节处理与推理链条
在理科大题中,AI模型常因推理链条过长、步骤跳跃、证明过程不严谨被扣分。部分模型在物理、化学实验设计题中,存在对实验原理理解不够深入、答题模板化等问题。未来,提升推理链条的严密性与细节还原能力,将是AI模型进一步突破的关键。
3.2 文科:知识储备强,作文与创造性表达为弱项
3.2.1 语文/英语:选择题、阅读题“学霸”本色,作文短板突出
在语文和英语科目中,豆包等大模型在选择题、阅读理解等客观题型上得分率极高,英语成绩接近满分,展现出强大的知识储备与语言理解能力。然而,作文部分则暴露出明显短板:内容刻板、缺乏情感、字数不达标或超标、立意不准、结构模板化,甚至出现小标题等不规范写作方式。语文作文得分低于Gemini,成为拉低总分的主要因素。
3.2.2 文综:知识面广,地理题多模态分析待提升
在历史、地理、政治三科中,豆包均获最高分,地理、历史均突破90分,显示出对中国基础教育知识点的深度掌握。国外大模型在中国知识点掌握上存在短板,尤其在地理题中,分析统计图和地形图的能力有待提升。豆包在文综主观题中,能较好地结合材料进行论述,但在创新表达和观点深度上仍有提升空间。
四、🌏 国际考试表现:多模态能力再获验证
4.1 JEE Advanced:全球顶级多模态推理挑战
豆包、Gemini等大模型还参加了印度理工学院JEE Advanced考试,该考试以图片形式呈现,考察多模态推理与泛化能力。豆包在数学5次采样中全部答对,物理、化学表现突出,最终得分329.6分,位列全印度前10,显示出国际顶级的多模态推理能力。
4.2 国际对比视角下的AI“学霸”
与全印度人类考生对比,JEE Advanced前十名分数在317-332分之间,豆包与Gemini具备进入前10的实力。Gemini在物理和化学表现突出,豆包在数学稳定性上更胜一筹。这一成绩不仅验证了AI大模型在中国高考场景下的能力,也彰显了其在全球顶级考试中的竞争力。
五、🛠️ 技术突破与创新机制:AI“学霸”养成记
.png)
5.1 多模态融合与长上下文能力
5.1.1 三阶段预训练:筑牢知识与推理基础
豆包大模型1.6采用三阶段预训练策略:
纯文本预训练:提升数据质量与知识密度,夯实基础知识。
多模态混合训练:强化文本与视觉数据融合,提升图像理解与多模态推理能力。
长上下文训练:将最大支持长度从32K提升至256K,实现一次性处理整卷试题,避免信息遗漏。
5.1.2 视觉语言模型(VLM):解析复杂图像
豆包集成了先进的视觉语言模型(VLM),能够解析图表、实验装置图、地形图等复杂图像,极大提升理科带图题目的表现力。VLM的引入,使得AI模型在多模态场景下具备更强的泛化与推理能力。
5.2 深度思考能力:攻克复杂推理难题
5.2.1 多阶段RFT与强化学习(RL)优化
豆包通过多阶段RFT(Reinforcement Fine-Tuning)与强化学习(RL)迭代优化,拓展算力和数据规模,提升复杂问题的思考长度。数学、物理等科目的推导严谨性已接近人类学霸水平,能快速定位关键参数,推导解题路径,减少单一模态误判。
5.2.2 Parallel Decoding技术:提升推理效率
引入parallel decoding技术,实现多路径并行推理,提升解题效率与准确率,尤其在高难度测试集上表现突出。
5.3 动态调节机制(AutoCoT):拒绝“过度思考”
5.3.1 动态思考能力:三种模式自适应切换
针对长链推理(Long CoT)易导致的“过度思考”问题,豆包提出“动态思考能力”,提供全思考、不思考、自适应思考三种模式。通过强化学习训练新奖励函数,惩罚过度思考,奖励恰当思考,实现推理链条的动态压缩,平衡效率与准确性,提升推理质量。
5.3.2 AutoCoT机制流程表
六、🏭 行业影响与未来展望:AI“学霸”走向产业深水区
6.1 行业落地:多模态AI赋能千行百业
豆包大模型1.6已在教育、金融、汽车、智能终端等行业广泛应用,覆盖4亿终端设备,服务70%系统重要性银行和八成主流车企。其多模态推理、长文本理解等能力,为智能教育、自动驾驶、金融风控等场景提供了坚实的技术支撑。
6.2 技术意义:AI在复杂认知任务中的突破
高考成绩的突破,标志着AI大模型在复杂认知任务上的巨大潜力。尤其在教育辅助、跨模态推理、智能问答等场景,AI有望成为人类学习与决策的重要助手。
6.3 持续挑战与改进方向
尽管豆包等大模型在多模态推理、长文本理解等方面实现了重大突破,但在图像识别、作文创造性表达、推理细节等方面仍有提升空间。未来,持续优化多模态能力和推理精度,将通用推理能力转化为行业解决方案,是AI大模型进化的必由之路。
结论
2025年高考AI大模型“考生”成绩放榜,豆包大模型1.6以文科683分、理科最高676分的优异表现,展现出超越人类学霸的多模态推理与深度思考能力。评测流程的严谨公正、学科表现的全面突破、技术创新的持续迭代,以及在国际顶级考试中的优异成绩,共同标志着AI大模型已迈入复杂认知任务的新纪元。未来,随着多模态融合、动态推理等技术的不断进步,AI大模型有望从“考生”转变为“导师”,推动教育、金融、智能制造等行业的深度变革。AI“学霸”时代已然到来,通用人工智能的曙光正悄然升起。
📢💻【省心锐评】
尽管大模型在高考中表现亮眼,但仍有提升空间,如图像识别、作文情感表达等。你对这些大模型的 “高考” 成绩有何看法?

评论