.png)


【摘要】企业AI转型普遍受阻,其症结并非模型能力不足,而是深藏于企业内部的数据孤岛、数据污染与数据壁垒。决胜AI下半场的关键,在于从根本上解决数据问题,通过系统性的数据治理,构建起可持续创造价值的数据资产。
引言
在AI大模型的热潮之下,从决策层的CEO到执行层的一线员工,几乎无人不谈论其最新进展与那些令人眼花缭乱的应用。我们似乎已经踏入一个“模型为王”的时代,仿佛只要能接入最强的模型,就能一举解决所有业务难题。
但现实往往不遂人愿。
许多企业投入巨资,满怀憧憬地开启AI转型之旅。他们接入了ChatGPT的API,招募了顶尖的大模型算法工程师,甚至采购了昂贵的私有化部署服务。一切看起来准备就绪,一个由AI赋能业务的新纪元似乎触手可及。
然而,结果却常常令人失望。
业务流程的瓶颈依旧存在,自动化率的提升微乎其微。
客户体验并未得到实质性改善,AI助手依然在答非所问。
来自销售、客服、运营团队的反馈惊人地一致,没法用、用不准、还不如人。
于是,质疑的声音开始弥漫。是不是模型的能力还不够强大?是不是我们的Prompt写得不够精妙?是不是国产模型终究不如GPT-4?
几天前,一位深耕企业数字化多年的好友留言,一语道破天机。他说,现在AI+最大的问题就是数据。我们的数据一塌糊涂,像一团乱麻般散落在十几个系统里,这该怎么办?
他没有追问算法,却道出了一个最普遍的真相。我们都梦想着能喂养出一个聪明的AI,到头来却发现,自己连一份合格的“数据饲料”都备不齐。这揭示了一个核心的悖论,通用大模型的巨大成功,是建立在整个互联网这个相对理想化的、海量的、连通的数据集之上。而企业AI转型的普遍失败,则往往始于内部那无数个各自为政、质量堪忧的数据孤岛。
对于绝大多数企业而言,AI转型真正的阿喀琉斯之踵,那个泥泞、琐碎、却又无论如何都绕不开的战场,恰恰是我们最不愿提及,也最难解决的——数据。
🧭 一、企业AI的阿喀琉斯之踵:通用大模型的肥沃土壤 vs. 企业的数据孤岛
%20拷贝.jpg)
要理解企业在AI转型中面临的困境,我们必须先回答一个根本问题,为什么像OpenAI、Google这样的大模型能够取得如此巨大的成功?
答案其实很简单,它们生长于一片相对肥沃的数据大陆。它们赖以生存和学习的,是整个公开互联网经过数十年积累、相对标准化的海量文本、图片和代码数据。这片大陆虽然广袤无垠,但其底层是相互连通的,数据格式也相对统一,例如网页、文本文件、图片等。这为训练一个具备通用知识的“大脑”,提供了近乎完美的土壤。
然而,当我们把视线从广阔的互联网拉回到企业内部时,眼前的景象截然不同。我们面对的,不再是连通的大陆,而是一片由无数“数据孤岛”和“数据沼泽”组成的破碎群岛。
企业的核心数据,那些真正蕴含着商业价值的专有知识,往往像一盘散沙,被深埋在各个角落。
财务部那套陈旧的ERP系统里。
销售部那些格式混乱的CRM Excel表里。
运营部各自为政的活动后台里。
客服部门堆积如山的聊天记录和通话录音里。
这些数据,不仅在物理存储上是分割的,在格式、标准和语义上更是五花八门。它们是企业最宝贵的资产,却也是AI模型最难啃的硬骨头。权威机构如Gartner和IDC的调研报告反复指出,数据准备不足和数据孤岛是导致企业AI项目失败的首要原因。这直接导致模型训练数据匮乏、推理效率低下,最终使得项目的投资回报率(ROI)远不及预期。
因此,企业AI转型的第一个,也是最致命的悖论就此出现。我们拥有了最强大的通用大脑,却无法为它提供它最需要的、干净且互通的专有数据。
不从根本上解决这个矛盾,任何AI转型的尝试,都无异于在流沙之上建造摩天大楼,其最终的结局早已注定。
⚖️ 二、企业数据的三宗罪:孤岛、污染与壁垒
如果说企业的数据是一座亟待挖掘的宝藏,那么这座宝藏之上,往往压着沉重的三座大山。它们就是数据孤岛、数据污染和数据壁垒。任何AI转型的雄心壮志,在它们面前,都可能被无情地碾得粉碎。
2.1 第一罪:孤岛 —— 我的客户不是你的客户
数据孤岛是企业数字化进程中最古老,也最顽固的敌人。它的本质,是组织内部的部门墙在数据层面的直接投射。
2.1.1 数据分散难找,散落在信息的“百慕大三角”
企业的数据往往没有一个统一的入口。当需要一份完整的数据时,它可能同时存在于多个地方。
销售与客户的微信聊天记录,存储在销售人员的个人手机里。
售后工程师的现场服务笔记,保存在本地的Word文档中。
市场部某次活动的报名表,是某位员工个人电脑里的一个Excel文件。
核心的客户交易数据,则躺在云端的CRM或某个SaaS系统里。
想象一下,当一个重要客户打来电话投诉时,你几乎不可能在短时间内拼凑出他的完整画像,包括他的购买历史、服务记录、最近的市场活动参与情况以及过往的每一次沟通。寻找和拼凑数据的成本,正在成为企业内部最大的隐性成本。
2.1.2 数据不互通,致命的部门墙与系统墙
这是最致命的一环。由于部门壁垒和技术栈的碎片化,各个系统之间的数据无法自由流动,导致企业始终在用“碎片”去理解“整体”。
市场部耗费巨资获取的销售线索,一旦进入销售环节,其后续的转化情况便成了黑盒,导致市场部无法有效优化广告投放策略。
销售部在毫不知情的情况下,给一位刚刚投诉过产品质量的客户,打去了热情洋溢的增购推销电话,结果可想而知。
客服部在接听客户来电时,对客户的购买历史、产品偏好和会员等级一无所知,无法提供任何个性化的服务。
数据孤岛,直接导致了企业的“认知分裂”。AI即便拥有通天的本事,也如同一个被蒙住了双眼、绑住了手脚的巨人,空有一身力气却无处施展。
一个典型的场景足以说明问题。销售团队信心满满地对AI说“请帮我分析一下‘高价值客户’的行为模式”。AI转身去问财务部的ERP系统“这些客户的历史回款周期和信用评级是怎样的?”系统冷冷地回答“权限不足,无法访问”。AI又去问客服部的工单系统“这些客户最近的投诉记录和满意度如何?”系统同样回答“数据尚未打通,无法提供”。
最终,AI能够分析的,只有销售团队自己那份片面的、充满了各种销售“黑话”和不规范记录的CRM数据。基于这样残缺的情报,AI给出的任何洞察和建议,都无异于盲人摸象。为了从根本上打破这种困境,数据中台应运而生。它通过统一的数据采集、治理、分层建模和标准化的服务API,其核心使命就是破除孤岛、促进共享,并复用数据资产。
2.2 第二罪:污染 —— “垃圾进,垃圾出”的铁律
假设我们历经千辛万苦,奇迹般地打通了所有孤岛,将数据汇集到了一起。我们往往会绝望地发现,我们得到的不是一座金山,而是一个巨大的数据垃圾场。
2.2.1 大量的数据负债,而非数据资产
汇集起来的数据,往往无法直接使用。它们充斥着各种各样的问题。
不完整。关键字段大量缺失,例如客户信息里没有行业分类,订单记录里没有渠道来源。
不一致。同一个实体在不同系统中有不同的表达。例如,同一个客户,在A系统里记录为“深圳”,在B系统里却是“深圳市”;销售A习惯用“李总”来称呼客户,销售B则记录为“李明先生”。
不规范。数据格式随意。例如,市场部收集的用户手机号,有的带国家码“+86”,有的不带;不同时期的产品订单,金额字段有的含税,有的不含税。
非结构化。大量的会议纪要、通话录音、产品手册、邮件内容,像“数据暗物质”一样沉睡在各个角落,蕴含巨大价值,却难以被机器直接理解和处理。
清洗、标注和结构化这些“脏数据”所需要的人力与时间投入,足以拖垮任何一个最初充满激情的AI项目。这些被污染的数据,对于AI模型来说是致命的毒药。企业投入数百万,雇佣最顶尖的算法工程师,用这些劣质的养料去训练模型,最终得到的,也只会是一个看起来很智能的“人工智障”。
“垃圾进,垃圾出”(Garbage In, Garbage Out),这是AI世界里最冰冷无情的一条铁律。要将这些“数据负债”转变为真正的“数据资产”,唯一的出路就是进行系统性的数据治理。这包括建立统一的数据标准、严格的数据质量监控、清晰的数据血缘追溯、完善的元数据管理、规范的数据生命周期以及精细化的权限控制,形成一个完整的全链条建设。
2.3 第三罪:壁垒 —— 看不见的数据红线
最后,即便我们拥有了干净、互通的数据,我们还会遇到一堵堵看不见的墙——那就是数据壁垒。
这些壁垒共同构成了一个复杂的数据迷宫。AI在其中每前进一步,都可能触碰到一条高压红线。解决这些壁垒,需要制度、流程与技术的协同作战,在合规的框架内,实现数据的“可管、可控、可用”。
⚙️ 三、破局思路:从“造完美数据湖”转向“数据飞轮”
%20拷贝.jpg)
面对数据的“三宗罪”,许多企业的第一反应是启动一个宏大的数据工程,试图构建一个“完美的数据湖”,将所有数据一网打尽。这种思路往往会陷入“大而全”的陷阱,项目周期长、见效慢,最终因为业务部门失去耐心而不了了之。
我们需要的是一种更敏捷、更务实的策略。放弃追求一步到位的完美数据湖,转而追求能快速产生业务价值的数据流。这个策略的核心,就是启动数据飞轮。
其核心思想是,以业务价值为驱动,从小场景切入,快速打通一个最小的数据闭环,让AI产生实际价值,然后用这个价值反哺数据的整合与治理,形成一个持续增强的正向循环。
下面是数据飞轮的四步循环。
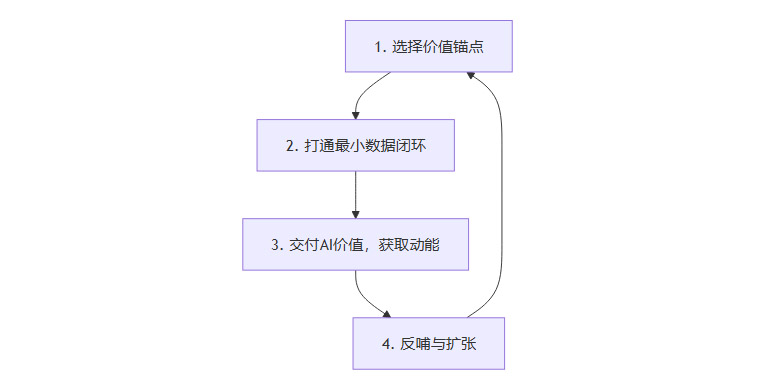
选择价值锚点。找到一个业务痛点明确、数据源相对集中、且AI能显著见效的场景。例如,销售团队普遍抱怨的“销售复盘效率低”就是一个绝佳的起点。这个场景痛点真实,且主要涉及的数据(CRM和通话录音)相对可控。
打通最小数据闭环。不需要整合全公司的数据。针对上一步选择的场景,只整合解决这个问题所必需的数据。例如,只为AI销售助手整合销售部门的通话录音和CRM中的基础客户档案信息。
交付AI价值,获取业务动能。用这些整合好的数据,快速训练或优化一个能自动总结通话要点、识别客户意向、推荐跟进策略的AI助手。当销售人员发现AI真的能帮他们节省大量写周报和复盘的时间,并且能提供有价值的跟进建议时,他们就从AI的旁观者、质疑者,变成了参与者和拥护者。这种效率和质量的提升,就是驱动飞轮转动的初始动能。
反哺与扩张。因为AI助手带来了实实在在的价值,销售团队会更有动力去提供更规范、更高质量的数据。例如,他们会自愿地为客户打上更精准的标签,完善缺失的字段,因为他们知道,这些数据能让AI助手变得更聪明,从而更好地帮助自己。这时,飞轮就获得了第一次有力的转动。数据质量和规范性在业务价值的驱动下自然提升。接下来,你可以顺势将市场部的线索数据或客服部的工单数据也纳入进来,让AI助手能够看到客户的全貌,提供更精准的洞察。飞轮就这样越转越大,越转越快,创造的价值也越来越深。
这个方法的精髓在于,它用价值驱动替代了技术驱动。你不是为了建一个漂亮的数据仓库而折腾,而是为了解决一个具体的业务问题而整合数据。每一次数据整合,都直接带来业务价值的提升,从而形成一个可持续迭代的良性闭环,避免了一上来就大而全的数据工程“空转”的尴尬局面。
🛠️ 四、架构师的解药:治理-中台-知识的组合拳
数据飞轮解决了“如何开始”的问题,但要保证飞轮能够持续、健康地转动,而不是转着转着又形成一个个新的、更大的数据孤岛,我们就必须在启动之初,就有一个清晰的终局蓝图来指引方向。这个蓝图,就是企业的智能地基。
面对数据的三宗罪,小修小补式的工具优化已然无效。我们需要的是一场自上而下的、架构级的系统性变革。这套解药,不是某个具体的AI工具,而是一套包含了顶层设计、中层建设和业务赋能的组合拳。
4.1 数据治理:顶层规则与秩序的建立
在修建任何宏伟的建筑之前,必须先有统一的法律和规章。数据治理,就是企业数据的“最高法典”,它为后续的一切数据工作,提供了最基本的秩序和标准。
数据治理通过顶层设计,系统性地解决了“标准不一、质量不稳、安全不可控”的顽疾,是后续一切数据工作能够顺利开展的基石。
4.2 数据中台:技术底座与服务化输出
如果说数据治理是法律,那么数据中台就是执行法律、建设基础设施的工程队。它的核心任务,是将分散在各个业务部门的数据,进行统一的汇集、加工、处理,并以标准化的服务,提供给上层的AI应用和业务分析。
数据中台的建设逻辑可以概括为以下三步。
数据汇集。通过各种数据集成工具,将来自ERP、CRM、小程序、App等所有渠道的多源异构数据,实时或准实时地汇入一个统一的数据湖或数据仓库中。
数据加工。按照数据治理制定的标准,对原始数据进行清洗、转换、整合,构建起分层的数据模型(如ODS、DWD、DWS、ADS),形成干净、标准、可用的主题数据。
数据服务化。将加工好的数据,封装成标准的API接口或数据服务,供AI模型、业务报表、营销系统等上层应用,安全、便捷地调用。
数据中台从技术架构上,彻底铲除了数据孤岛赖以生存的根基,让数据真正成为全公司共享的、可复用的核心资产。
以服装企业雅戈尔为例,其通过构建数据中台,成功统一了全集团的指标体系,打通了从研发、制造到销售的全链路数据。门店可以实时看到全景数据,辅助进行销售决策和库存管理。这一举措,据报道显著降低了一线员工的行政性工作量(减负60%-70%),是“治理+中台+业务场景”联动产生复利效应的典型案例。
4.3 知识图谱:语义理解与长期记忆
有了干净、互通的数据,我们还需要让AI能够理解这些数据背后复杂的商业逻辑和关系。知识图谱,就是实现这一目标的“翻译官”和“关系网”。它让AI从一个只能处理表格数据的“计算器”,升级为一个能够理解业务的“专家大脑”。
知识图谱的核心工作包括两个部分。
实体与关系抽取。从海量的非结构化和半结构化文本(如法律文书、产品手册、客服记录、公司年报)中,通过自然语言处理技术,自动抽取并识别出核心的实体(如公司、产品、人物、技术)以及它们之间的关系(如A公司投资了B公司,B公司的产品是C,C技术应用于D领域)。
构建知识网络。将这些抽取出的实体和关系,连接成一张巨大的、动态的知识网络。AI可以像人类专家一样,在这张网络上进行推理和查询,发现隐藏的关联。
在生成式AI的新范式下,知识图谱的价值被进一步放大了。它不再仅仅是一个独立的分析大脑,而是成为了大语言模型(LLM)最可靠的长期记忆系统和事实核查员。
LLM本身存在“幻觉”问题,并且其知识截止于训练日期。通过将LLM与企业自身的知识图谱相结合(例如通过GraphRAG等技术),可以实现以下效果。
事实增强。当用户提问时,系统首先在知识图谱中进行精确查询,将可靠的事实作为上下文提供给LLM,从而大大减少LLM产生幻觉的概率。
逻辑推理。知识图谱的图结构天然擅长多跳推理。例如,回答“与我们公司有竞争关系,并且最近发布了新产品的公司的CEO是谁?”这类问题,纯粹的向量检索很难完成,但知识图谱可以轻松地通过“竞争关系 -> 公司 -> 发布产品 -> CEO”这样的路径进行推理。
可解释性。基于知识图谱给出的答案,可以清晰地展示其推理路径和事实来源,这对于金融、医疗、法律等要求高可信度的领域至关重要。
微软等公司提出的GraphRAG方案,正是通过“图结构+检索”的方式,弥补了纯向量RAG(检索增强生成)只擅长“相似性”查找,不擅长“逻辑关联”推理的短板。当然,大规模的企业级知识图谱落地,在本体构建、语义层维护等方面仍然存在工程化挑战,但这无疑是释放企业专有数据价值的终极方向。
✅ 五、数据准备的三层功夫
%20拷贝.jpg)
在启动任何一个正式的AI项目之前,企业必须对自身的数据准备情况进行一次摸底自查。我们可以将其简化为“三层功夫”,这三层功夫的扎实程度,是许多AI项目“上线即失速”的真正分水岭。
这三层功夫,从下至上,层层递进。只有当数据能够被顺畅地访问,清晰地理解,并且在业务流程中不断地复用和迭代时,AI的价值才能真正被激发出来。务必将这三层准备工作前置,做扎实。
结论
AI正在以前所未有的力量,倒逼每一家企业重新审视自己的数据家底。这个过程无疑是痛苦的,因为它要求我们打破根深蒂固的部门壁垒,改变沿用多年的工作习惯,甚至重构核心的业务流程。但同时,这也是一次前所未有的机遇。
当你的企业通过启动数据飞轮,将一个个孤立的数据岛屿连接成畅通的价值江河时,AI才能真正发挥其威力。届时,数据将不再是你财报上的一项成本,而是你最核心的、无法被轻易复制的竞争力源泉。
展望未来,最顶尖的AI模型能力,会越来越像电力一样,成为一种人人皆可获取的基础设施。企业之间真正的护城河,将不再是你用了哪个模型,而是你独有的、干净的、互通的、并且能够通过数据飞轮持续产生价值的数据资产。
换言之,企业AI竞赛的本质,不是模型之争,而是数据之争。
这场深刻的变革,道阻且长。它考验的不仅是技术能力,更是企业的战略远见和组织魄力。它迫切需要那些既懂业务、又懂产品、还懂数据的跨界架构师来掌舵,系统性地推进数据治理、数据中台和知识图谱的建设,才能最终实现从AI的“试验田”到“产粮田”的跃迁。
📢💻 【省心锐评】
别再迷信模型了。AI转型的胜负手,早已从算法的军备竞赛,转移到了数据治理的持久战。谁能把自家的“数据沼泽”变成“数据金矿”,谁才能在智能时代真正掌握主动权。

评论