【摘要】RAG数据集质量决定大模型问答系统的效果。文章系统梳理了从数据标准、文档解析、多模态处理、数据清洗、结构化、分块到质量评估的全流程,强调实操细节与工程落地,配合表格和流程图,帮助产品经理和技术团队高效打造高质量RAG知识库。
引言
RAG(检索增强生成)技术正成为大模型智能问答系统的核心。无论是企业知识库、智能客服,还是行业垂直应用,RAG都在连接外部知识与大模型推理之间扮演着关键角色。数据集的质量直接决定了RAG系统的召回率、准确率和用户体验。数据构建流程涉及文档解析、内容切分、数据清洗、结构化、分块、向量化和质量评估等多个环节。每一步都需要精细打磨,才能让大模型真正“知其然,知其所以然”。这篇文章以产品经理视角,结合工程实践,梳理打造高质量RAG数据集的完整路径。内容覆盖标准制定、文档解析、多模态处理、数据清洗、结构化、分块与向量化、质量评估等环节,配合表格和流程图,帮助团队少走弯路,快速落地。
一、数据集标准制定:业务驱动与数据质量并重
%20拷贝.jpg)
1.1 明确数据标准,保障内容完整性与准确性
RAG知识库的核心是数据。数据标准决定了后续所有工作的基础。内容完整、准确、结构清晰、元数据齐全,是高质量RAG数据集的四大基石。
维度 | 说明 | 影响 |
|---|
内容完整性 | 覆盖所有业务关键信息,不能遗漏 | 避免AI“答非所问”或“一问三不知” |
内容准确性 | 严格把控数据源权威性和时效性,杜绝错误信息 | 防止错误被模型放大,影响用户体验和企业信誉 |
关系完整性 | 保留文档结构(目录、章节、表格、图片等),还原内容间逻辑关系 | 让模型理解内容血缘,提升检索和生成的相关性 |
元数据完整性 | 每个数据块补充来源、时间、标签、权限等元数据 | 提升检索相关性和系统安全性,支持权限控制和内容筛选 |
内容完整性要求知识库覆盖所有业务关键信息。缺失内容会让AI无法作答或答非所问。内容准确性是底线,错误数据会被模型“自信”地放大,带来指数级风险。关系完整性让模型能理解内容之间的逻辑,避免“盲人摸象”。元数据完整性则是让模型能高效筛选和理解内容的“隐形目录”。
1.2 数据与场景匹配,动态更新与安全合规
数据要和业务场景强相关。只保留有用的数据,定期增量更新,避免知识库“过时”。敏感信息要脱敏,权限分级,确保合规和安全。
需求 | 说明 |
|---|
业务相关性 | 只保留与目标业务强相关的数据 |
动态更新 | 定期增量更新,保证知识库时效性 |
安全合规 | 敏感信息脱敏,权限分级,确保数据合规与安全 |
二、文档解析:多格式、多模态的高效处理
2.1 结构化/半结构化/非结构化文档解析
不同文档格式解析方式不同。Word、HTML、Markdown等结构化文档解析相对简单。PDF、图片、音视频等非结构化或多模态内容处理难度更高。
文档类型 | 解析方式与工具 | 处理难点与要点 |
|---|
Word/HTML/Markdown | 用结构化标签直接解析,python-docx等工具提取文本和图片 | 保留层级和语义,输出富文本HTML,便于后续处理 |
PDF | PyMuPDF、pdfplumber、Unstructured、MinerU、LlamaParse等 | 缺乏固有语义结构,需重建段落、标题、列表,修复跨页断句等问题 |
图片 | OCR(PaddleOCR、Tesseract等)、多模态视觉模型(Qwen-VL、GPT-4V) | 图片转文本,复杂图片生成语义摘要 |
表格 | 专用解析器(Camelot、Tabula等)、结构化提取与摘要双重索引 | 结构化提取,提升检索准确性 |
公式 | LatexOCR等工具 | 公式转为可识别格式 |
2.1.1 Word文档解析流程
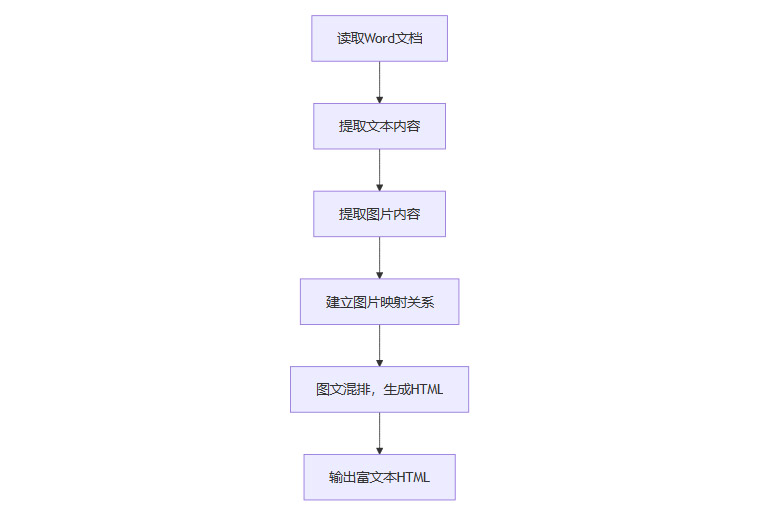
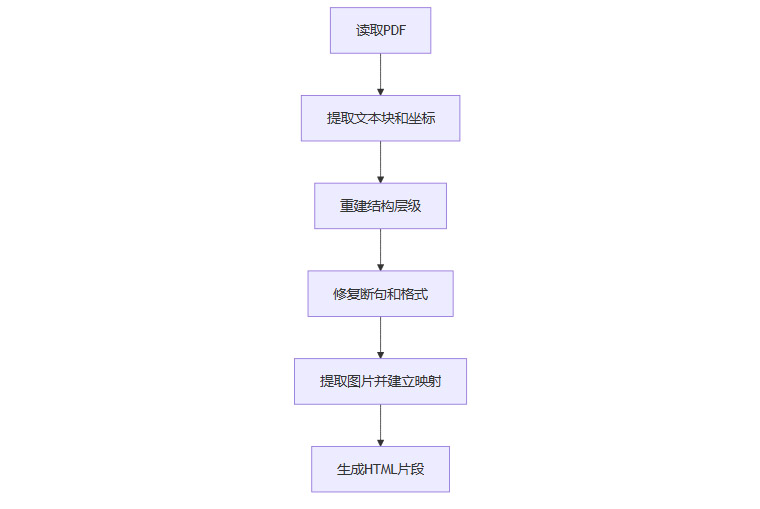
2.1.2 PDF文档解析流程
2.2 多模态数据处理
音频、视频、图片、表格、公式等多模态内容,需结合ASR、OCR、视觉模型等多种技术手段处理。
多模态类型 | 处理流程 | 工具与方法 |
|---|
音频 | ASR转写为文本,按时间切块,保留时间戳和原音频路径 | Whisper、讯飞ASR等 |
视频 | 抽取音轨ASR,关键帧截图,OCR提取画面要点,时间戳绑定 | FFMPEG、PaddleOCR、镜头切换检测等 |
图片 | OCR转文本,复杂图片用视觉模型生成摘要 | PaddleOCR、Qwen-VL、GPT-4V |
表格 | 结构化提取,摘要双重索引 | Camelot、Tabula、结构化摘要脚本 |
公式 | LatexOCR等工具转为可识别格式 | LatexOCR |
2.2.1 音频/视频处理流程
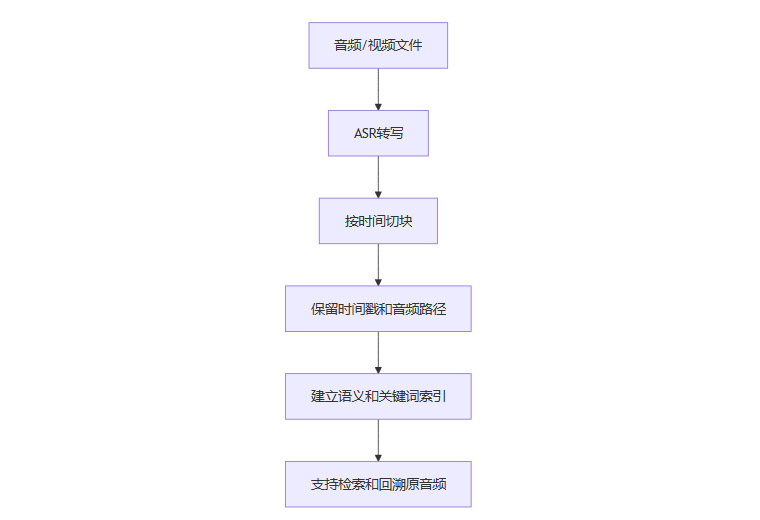
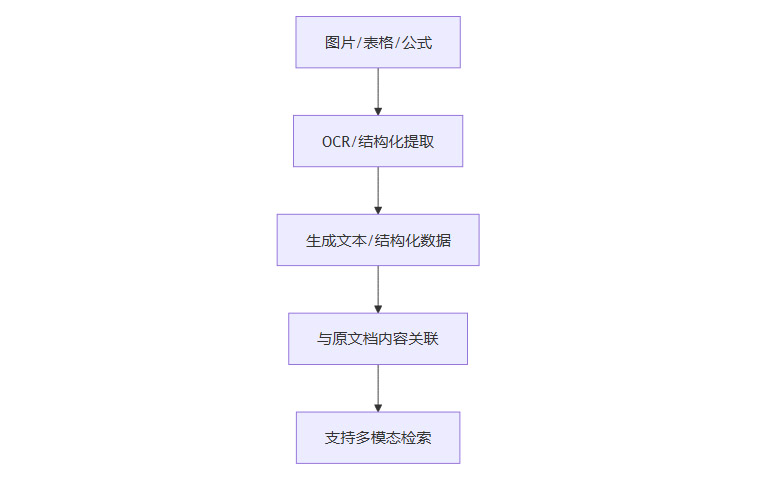
2.2.2 图片/表格/公式处理流程
三、数据清洗与结构化:打造高质量RAG数据集的关键
%20拷贝.jpg)
3.1 标准化清洗流程
数据清洗是RAG数据集构建的核心环节。清洗流程要标准化、自动化,确保数据高质量、结构化、语义清晰。
步骤 | 说明 | 工具与方法 |
|---|
格式清理 | 去除HTML/XML标签、LaTeX命令、页眉页脚、水印、乱码等噪声,统一编码和标点 | BeautifulSoup、正则表达式、Pandas |
冗余过滤 | 去除重复、广告、免责声明、无意义短段落,保留核心内容 | 哈希去重、向量相似度去重 |
结构恢复 | 还原标题层级、合并被错误拆分的段落、表格和列表结构化 | Markdown转化、结构化脚本 |
语义修复 | 修正OCR错误、统一术语、保证语义连贯 | 术语表、自动校对脚本 |
分块准备 | 按标题、段落、语义边界切分,保留标题与正文关联,标记特殊块 | 分块脚本、正则表达式 |
3.1.1 数据清洗流程图

3.2 元数据与标签补全
每个数据块都要补充元数据。元数据包括来源、时间、标签、权限等,便于后续检索过滤和权限控制。
元数据类型 | 说明 |
|---|
来源 | 原始文档路径、文件名、URL等 |
时间 | 创建时间、更新时间、文档生效时间等 |
标签 | 主题、业务线、文档类型、语义标签等 |
权限 | 访问权限、敏感级别、用户分组等 |
3.3 问答对(QA Pair)优化(可选)
对于FAQ、客服等场景,可以将数据整理为问答对形式,提升检索和生成的精准度。
优化方式 | 说明 |
|---|
问答对整理 | 将业务文档转为标准问答对格式,便于检索和生成 |
多轮对话 | 支持多轮问答,提升复杂场景下的问答能力 |
四、分块与向量化:兼顾语义完整性与检索效率
4.1 分块策略
分块是RAG系统的关键。分块要结合结构和语义,避免信息丢失或检索噪声。块太大,检索不准;块太小,语义断裂。
分块方式 | 说明 | 优缺点 |
|---|
按结构分块 | 按章节、标题、段落切分 | 结构清晰,便于定位,但有时语义跨度大 |
按语义分块 | 按主题、问答对、语义边界切分 | 语义完整,检索相关性高,但实现难度大 |
重叠分块 | 相邻块保留部分重叠(如10%-20%) | 防止语义断裂,提升检索准确性 |
4.2 分块与向量化流程
4.3 向量化与索引
选择适配业务的嵌入模型(如BERT、领域微调模型),将文本块转为向量,结合元数据建立高效索引。常用向量数据库有Milvus、Faiss、Chroma等。
步骤 | 说明 | 工具与方法 |
|---|
嵌入模型选择 | 选择适配业务的嵌入模型,支持多语言、多领域 | BERT、ERNIE、领域微调模型 |
向量化 | 将文本块转为向量 | HuggingFace Transformers、OpenAI Embedding API等 |
建立索引 | 结合元数据建立高效索引,支持混合检索 | Milvus、Faiss、Chroma等 |
五、质量评估与持续优化
%20拷贝.jpg)
5.1 人工与自动化结合
结合人工抽检和自动化工具,评估数据准确性、完整性、时效性。自动化工具可覆盖大部分常规问题,人工抽检聚焦难点和边界场景。
评估维度 | 说明 | 方法 |
|---|
准确性 | 数据内容是否真实、无误 | 自动化校验、人工抽检 |
完整性 | 是否覆盖所有业务关键信息 | 业务专家审核、覆盖率统计 |
时效性 | 数据是否及时更新 | 定期更新、增量同步 |
结构与元数据 | 结构是否清晰,元数据是否齐全 | 自动化脚本、人工核查 |
5.2 动态更新与反馈机制
定期更新数据,结合用户反馈持续优化知识库内容和结构。建立数据更新、反馈收集、问题修复的闭环机制。
机制 | 说明 |
|---|
定期更新 | 定时同步新数据,淘汰过时内容 |
用户反馈 | 收集用户检索和问答反馈,发现问题及时修复 |
闭环优化 | 数据更新、反馈收集、问题修复形成闭环,持续提升数据质量 |
六、工具与工程实践推荐
6.1 文档解析工具
工具 | 适用场景 | 特点 |
|---|
MinerU | 多格式文档解析,支持结构化和多模态 | 工业级,支持大规模处理 |
LlamaParse | PDF、Word等文档解析,结构还原能力强 | 结构化还原,支持多语言 |
Unstructured | 非结构化文档解析,支持多种格式 | 灵活,适合复杂文档 |
PyMuPDF | PDF解析,支持文本、图片、表格提取 | 轻量级,易用 |
pdfplumber | PDF文本和表格提取 | 表格处理能力强 |
6.2 数据清洗工具
工具 | 适用场景 | 特点 |
|---|
BeautifulSoup | HTML/XML标签清理 | 解析灵活,易用 |
正则表达式 | 格式清理、分块、去噪 | 高效,适合批量处理 |
Pandas | 数据处理、去重、结构化 | 数据分析能力强 |
6.3 向量数据库
工具 | 适用场景 | 特点 |
|---|
Milvus | 大规模向量检索与混合索引 | 分布式,性能高 |
Faiss | 向量检索 | 高效,适合本地部署 |
Chroma | 轻量级向量数据库 | 易用,适合中小规模场景 |
6.4 多模态处理工具
工具 | 适用场景 | 特点 |
|---|
CLIP | 图片与文本向量化 | 多模态检索能力强 |
Qwen-VL | 视觉大模型,图片理解与摘要 | 复杂图片语义提取 |
PaddleOCR | 图片文字识别 | 中文识别能力强 |
GPT-4V | 多模态理解与生成 | 支持图片、文本、语音等多模态 |
结论
RAG数据集的质量决定了大模型问答系统的上限。高质量RAG数据集的打造,需要业务驱动的数据标准、精细化的文档解析、多模态内容的结构化处理、严格的数据清洗与分块策略,以及科学的质量评估和持续优化机制。每一步都要落到实处,才能让知识库召回率和准确率大幅提升。产品经理和技术团队要紧密协作,结合自动化工具与人工审核,持续优化数据流程。最终,才能建立起逻辑清晰、输出直击答案的RAG知识库,为大模型应用落地提供坚实的数据基础。
📢💻 【省心锐评】
RAG的上限,不在模型,在数据。别再迷信花哨的框架了,把文档解析和数据清洗这些“脏活累活”干到极致,你的AI应用才能真正脱胎换骨。

.png)


评论