.png)


【摘要】人形机器人发展远滞后于AI聊天机器人,根源在于一场“数据饥荒”。物理世界交互数据的获取难度与复杂性,构成了与虚拟文本世界间一道长达十万年的鸿沟,成为其走向实用的核心枷锁。
引言
近几年,人工智能的世界仿佛被按下了快进键。以ChatGPT为代表的AI聊天机器人,凭借其惊人的语言理解和生成能力,迅速渗透进我们生活的方方面面。从个人助理到客户服务,甚至心理治疗,它们无处不在。这场变革的引擎,正是大语言模型(LLM)。它像一头不知疲倦的巨兽,吞噬着互联网上浩如烟海的文本数据,通过深度学习算法,构建起一个庞大的知识与逻辑体系。
在数字世界高歌猛进的同时,物理世界的智能探索却显得步履蹒跚。科技界曾一度预测,在机器学习的加持下,各类机器人将如雨后春笋般涌现。执行精密手术的外科机器人,替代流水线工人的工业机器人,乃至打理家务的智能管家,一幅幅科幻电影中的场景似乎触手可及。
然而,现实给出了更为冷静的答案。加州大学伯克利分校的机器人专家肯·戈德伯г(Ken Goldberg)对此就持有相当谨慎的态度。他在《Science Robotics》期刊上发表的重量级论文,如同一盆冷水,浇在了这股宣传热潮之上。他一针见血地指出,人形机器人在技能获取上,与AI聊天机器人存在着天壤之别。其核心症结,在于一场严重的**“数据饥荒”**。这个差距有多大?戈德伯г给出了一个令人震惊的数字——十万年。
这并非危言耸听。它揭示了虚拟智能与物理智能之间一道深刻的鸿沟。当AI在比特世界里纵横捭阖时,人形机器人仍在为如何稳稳地拿起一个杯子而苦恼。这场关于机器人未来的争论也随之展开,我们是该继续不计成本地为机器人“喂”数据,还是应该回归传统的工程方法,用代码和物理定律为它们铺就前路?
本文将深入剖析这“十万年”数据鸿沟的本质,探讨其背后复杂的技术难题,梳理当前行业的发展路径之争,并试图描绘出一条更为务实和清晰的未来图景。
一、⏳ 十万年鸿沟,一道难以逾越的数据天堑
%20拷贝.jpg)
1.1 “数据富翁”与“数据饥民”的鲜明对比
要理解这十万年的差距,我们首先需要看清AI聊天机器人和人形机器人截然不同的“食谱”。
AI聊天机器人是一个不折不扣的**“数据富翁”**。它的训练数据,源自整个互联网。从维基百科到学术论文,从新闻报道到社交媒体,海量的文本数据构成了它成长的全部养料。戈德伯г做过一个形象的计算,如果让一个人来阅读完训练LLM所需的全部文本,不眠不休,需要整整十万年。正是这近乎无限的数据,让LLM得以洞察语言的精妙,学会推理、归纳甚至一定程度的“创造”。
相比之下,人形机器人则是一个彻头彻尾的**“数据饥民”**。它需要的不是文字,而是关于物理世界交互的经验。每一次抓取、每一次行走、每一次与环境的互动,都必须被记录、被理解、被学习。这种数据不仅在数量上远超文本数据,其复杂性更是指数级增长。
它必须是多模态的,至少包含以下几个维度。
视觉信息 物体的形状、颜色、位置、材质。
本体感觉 机器人自身关节的角度、速度、力矩。
力觉与触觉 手指与物体接触时的压力分布、摩擦力、温度。
听觉信息 物体碰撞的声音、环境噪音。
行为序列 完成一个任务所需的完整动作链。
这些数据相互关联,共同构成一次成功的物理交互。显然,互联网上并没有一个现成的“物理交互数据库”可供下载。人形机器人必须在与世界的笨拙互动中,一点一滴地积累自己的“人生经验”。这个过程的效率,与LLM在文本海洋中畅游的速度相比,简直是天壤之别。
1.2 十万年差距的本质
这十万年的差距,本质上是数据维度、获取成本和标注难度的三重差异。
首先是数据维度的差异。文本数据本质上是一维的序列信息。而物理交互数据是高维的、时序的、非结构化的。机器人需要处理的,是一个包含空间几何、物理动力学和不确定性的复杂系统。一个简单的“推门”动作,背后就牵涉到对门把手位置的识别、自身姿态的调整、手臂运动轨迹的规划、以及与门轴之间力与力矩的精妙控制。将这一切转化为机器可学习的数据格式,其难度远超处理一段文字。
其次是数据获取成本的差异。LLM的数据获取成本极低,几乎就是网络带宽和存储的费用。而物理数据的获取成本却异常高昂。每一次尝试都可能导致机器人或环境的物理损坏。一个价值数十万甚至上百万美元的机器人原型,在训练中摔倒一次,可能就意味着数周的维修和高昂的备件费用。这种“试错成本”极大地限制了数据采集的规模和速度。
最后是数据标注难度的差异。文本数据可以利用无监督或自监督学习,让模型自己从海量文本中寻找规律。而机器人的物理交互数据,很多时候需要精细的人工标注。比如,在一次抓取任务中,我们需要标注出最佳的抓取点、合适的抓取姿态和力度。这种标注不仅耗时耗力,而且对标注人员的专业性要求极高。一个微小的标注偏差,就可能导致机器人在现实中抓取失败。
这三重差异共同构成了那道深不见底的鸿沟。即使我们拥有相当于十万年阅读量的文本数据,也无法教会一个机器人如何拧开一个瓶盖。因为它们生活在两个完全不同的世界,遵循着两套截然不同的规则。
1.3 数据采集的“三重困境”
既然无法像LLM那样坐享其成,机器人研究者们便开始探索各种主动获取数据的方法。然而,每一种方法都伴随着自身的局限性,形成了一个难以突破的“三重困境”。
1.3.1 视频学习法,看得见却摸不着
一个直观的想法是,让机器人观看海量的人类活动视频,从中学习如何与世界互动。YouTube上有无数的烹饪教程、修理指南和日常生活记录,这似乎是一个取之不尽的数据金矿。
但这种方法的挑战在于,它**“看得见却摸不着”**。
缺乏物理细节 视频只能记录动作的外部表象,却无法捕捉到关键的物理信息。比如,一个人拿起鸡蛋时用了多大的力?拧螺丝时手腕旋转了多大的扭矩?这些信息对于机器人成功复现动作至关重要,但在2D视频中完全丢失了。
2D到3D的转化难题 机器人需要的是三维空间中的精确指令,而视频是二维的。从2D像素到3D世界坐标的转化,本身就是一个极具挑战性的计算机视觉问题。视角遮挡、光照变化、物体形变等因素,都会给这种转化带来巨大的不确定性。
本体感受的缺失 人类在执行动作时,依赖于复杂的本体感觉(知道自己肢体的位置和状态)。机器人观看视频时,无法体验到这种“第一人称”的感觉,也就难以建立起视觉信息与自身运动控制之间的直接映射。
因此,视频学习法目前更多停留在模仿一些相对简单的、对物理精度要求不高的动作上,距离完成精细、复杂的现实任务还有很长的路要走。
1.3.2 模拟数据法,象牙塔里的完美主义
为了规避现实世界的高昂试错成本,研究者们将目光投向了虚拟仿真环境。在模拟器中,可以创造出任意的场景和任务,让机器人在其中进行数百万次甚至上亿次的训练,而不用担心任何物理损坏。这种方法在某些特定任务上取得了显著成功,比如训练机器人奔跑、跳跃甚至完成后空翻等高难度杂技动作。
然而,模拟数据法也存在其固有的“原罪”——“模拟与现实的差距”(Sim-to-Real Gap)。
物理引擎的不完美 尽管现代物理引擎已经非常先进,但它们仍然无法百分之百地复现真实世界的物理规律。尤其是在接触、碰撞和摩擦等复杂动力学现象上,模拟与现实之间总会存在细微的差异。
感官信息的失真 模拟器生成的视觉、力觉等感官数据,与真实传感器采集的数据也存在差异。例如,模拟的摄像头图像可能过于“干净”,缺乏真实世界中的噪点、模糊和光线反射。
这些看似微小的差异,在机器人从模拟环境迁移到现实世界时,可能会被无限放大。一个在模拟器中表现完美的机器人,到了现实中可能变得步履维艰、错误百出。虽然研究者们开发了“域随机化”(Domain Randomization)等技术来试图弥合这一差距,但对于需要高精度和高灵活性的通用任务来说,模拟数据依然远远不够。它像一个完美的象牙塔,机器人可以在里面尽情驰骋,却难以将学到的本领带到外面泥泞的真实世界。
1.3.3 远程操控法,精疲力竭的“提线木偶”
为了获得高质量的真实世界数据,研究者们想出了最直接也最“笨”的办法——远程操控(Teleoperation)。操作员穿戴上特制的数据手套或外骨骼设备,像操纵一个提线木偶一样,远程控制机器人完成各种任务。机器人则会记录下整个过程中所有的传感器数据和动作指令。
这种方法产生的数据质量极高,因为它直接来源于真实世界的成功交互。但是,它的效率极其低下,且难以规模化。
过程枯燥且耗时 对于人类操作员来说,一遍又一遍地重复简单的抓取、放置任务,是一件非常枯燥乏味的事情。这导致操作员很容易疲劳,影响数据采集的效率和质量。
人力成本高昂 培养一名熟练的机器人远程操作员需要时间和成本。要积累起足以训练一个通用模型所需的海量数据,需要成千上万的操作员工作漫长的时间,这在经济上几乎是不可行的。
设备与延迟的限制 远程操控设备本身就价格不菲,而且网络延迟会严重影响操作的流畅性和精确性。
这三种主流的数据采集方法各有优劣,共同构成了当前机器人数据获取的困境,具体可以总结如下。
二、🦾 物理世界的“诅咒”,莫拉维克悖论的现实枷锁
即便我们解决了数据问题,人形机器人还需要面对一个更深层次的挑战,一个源于物理世界本身的“诅咒”。这个诅咒,就是著名的**“莫拉维克悖论”(Moravec's Paradox)**。
2.1 从“拿起杯子”说起
这个悖论由汉斯·莫拉维克等人工智能研究者在20世纪80年代提出。它的核心思想是,对人类来说轻而易举的事情(如感知、运动),对计算机来说却异常困难;而对人类来说很困难的事情(如下棋、计算),对计算机来说却相对容易。
AI聊天机器人处理语言、进行逻辑推理,正是在挑战人类的“高级智慧”,这恰好是计算机擅长的领域。而人形机器人要做的,却是那些我们人类婴儿时期就已掌握的、不假思索的本能动作。这些动作,恰恰是机器人最难逾越的障碍。
让我们以一个看似不能再简单的动作——“拿起一个杯子”——为例,看看机器人需要完成多么复杂的一系列任务。
这六个步骤中的任何一个环节出现微小的差错,都将导致整个任务的失败。而人类完成这一切,几乎完全依赖于潜意识和肌肉记忆。我们的大脑在数百万年的进化中,已经将这些感知和运动能力打磨得炉火纯青。机器人想要通过代码和算法来复现这种“本能”,其难度远超外界想象。
2.2 “大脑”与“小脑”的失衡
行业内有一个形象的比喻,将机器人的智能系统分为“大脑”和“小脑”。
“大脑” 负责高级认知功能,如任务规划、场景理解、人机交互。这部分与AI聊天机器人的能力有相似之处,但需要与物理世界紧密结合。
“小脑” 负责底层的运动控制,如保持平衡、协调步态、执行精细动作。这部分直接对应着莫拉维克悖论中那些“对人容易,对机困难”的能力。
当前人形机器人的窘境,正是**“大脑”不足与“小脑”不强的双重困境**。
“大脑”不足 体现在缺乏一个通用的机器人操作系统和高质量的跨场景数据。每个机器人厂商几乎都在各自为战,缺乏统一的平台和标准,导致研发成果难以复用和迁移。数据饥荒更是让“大脑”无米下锅,难以训练出真正通用的智能。
“小脑”不强 则更为致命。机器人的运动控制稳定性、安全性、泛化能力都存在严重短板。即使在实验室的理想环境下,机器人行走、操作的稳定性也常常不尽如人意,更不用说在复杂多变的真实家庭或工作场景中。一个连路都走不稳的机器人,谈何完成复杂的任务?
这种“大脑”与“小脑”的失衡,使得人形机器人看起来更像一个“高位截瘫”的病人,空有理论上的智能,却无法有效地指挥自己的“身体”。
2.3 触觉的缺失,精细操作的阿喀琉斯之踵
在莫拉维克悖论的枷锁之上,还有一个常常被忽视但至关重要的技术难题——触觉的缺失。
人类的指尖布满了数以万计的感受器,能够感知到极其细微的压力变化、纹理和温度。正是这种高精度的触觉反馈,让我们能够完成穿针引线、系鞋带、分辨材质等精细操作。
而目前绝大多数的机器人手爪,都缺乏这种高分辨率的触觉感知能力。它们更多依赖于视觉和力/力矩传感器。视觉会被遮挡,而力/力矩传感器只能提供一个笼统的合力信息,无法感知到接触面的压力分布和滑动趋势。
这就导致机器人在进行精细操作时,如同戴着一双厚厚的棉手套。它很难判断自己是否抓稳了一个物体,也很难感知到物体是否即将从手中滑落。这种**“触觉盲区”**,是机器人无法完成许多看似简单任务的根本原因之一,也是其与人类灵巧性之间一道难以逾越的鸿沟。
这些源于物理世界的根本性难题,共同构成了人形机器人难以逾越的技术枷锁,其核心挑战可以归纳为下表。
三、🧭 发展的十字路口,数据与工程的路线之争
%20拷贝.jpg)
面对数据饥荒和物理世界的双重诅咒,人形机器人行业走到了一个关键的十字路口。未来的道路该如何选择?学界和业界内部,逐渐形成了两种截然不同甚至有些对立的观点,一场关于“数据驱动”与“工程驱动”的路线之争悄然上演。
3.1 数据驱动派,大力出奇迹的信仰
数据驱动派的拥护者们,深受近年来深度学习浪潮的鼓舞。他们见证了大语言模型如何在海量数据的灌溉下,从一个简单的词语接龙工具,进化为能够写诗、编程、进行深度对话的强大AI。这段波澜壮阔的历史,让他们坚信一个朴素的真理——“大力出奇迹”。
在他们看来,机器人之所以笨拙,归根结底还是因为“见识”太少。只要能为机器人提供足够多、足够高质量的交互数据,让神经网络模型在其中进行端到端的学习,机器人自然能够涌现出智能。
这一派的典型代表,往往是拥有强大算力和数据资源的科技巨头。他们投入巨资建设大规模的仿真平台,部署庞大的机器人集群进行7x24小时的数据采集。他们的目标,是打造一个机器人的“ImageNet”(一个引爆了计算机视觉革命的大规模图像数据集),通过规模化的数据来暴力破解物理智能的密码。
这个思路的优点是简单直接,且上限极高。它绕过了对复杂物理世界进行精确建模的难题,将一切都交给了神经网络这个强大的“黑箱”。如果成功,它将能够创造出具有极强泛化能力和适应性的通用机器人。
但其缺点也同样明显。
对数据的极度依赖 正如前文所述,高质量物理数据的获取成本极高,速度极慢。在达到能够引发智能“相变”的数据规模之前,需要漫长的时间和天文数字般的投入。
可解释性和安全性的隐忧 端到端的深度学习模型通常缺乏可解释性。当机器人在关键任务中(如医疗、护理)出现失误时,我们很难追溯其决策过程,也就难以保证其安全性。
忽视物理本质 过分依赖数据,可能会忽视对机器人本体动力学、控制理论等基础工程问题的研究。这可能导致机器人虽然“看起来很聪明”,但其基础运动能力和稳定性却存在先天不足。
3.2 工程驱动派,步步为营的现实主义
与数据驱动派的豪情壮志不同,工程驱动派则显得更为务实和保守。这一派的成员大多是传统的机器人学专家和工程师。他们深知与物理世界打交道的艰难,对纯数据驱动的方法持怀疑态度。
他们主张,应该回归机器人学的“第一性原理”,依靠物理学、数学、控制理论和环境建模等传统工程方法,为机器人打下坚实的基础。在他们看来,机器人的智能不应是空中楼阁,而必须建立在可靠的物理实体和精确的数学模型之上。
这条路径的核心思想是**“先让机器人动起来,再让它变聪明”**。
建立精确模型 首先,通过严谨的工程方法,为机器人建立精确的动力学模型,设计出稳定、高效的底层运动控制器。
分而治之 将复杂的任务分解为一系列更简单的子任务,为每个子任务设计专门的算法和策略。
结构化环境 在应用初期,尽量让机器人在结构化、可预测的环境中工作,降低任务的不确定性。
数据辅助迭代 在机器人能够稳定运行的基础上,再利用收集到的真实数据,对模型和算法进行迭代优化,逐步提升其适应性和智能水平。
肯·戈德伯г本人就是这一派的坚定支持者。他认为,优秀的工程、数学和科学知识,仍然是推动机器人发展的关键。谷歌旗下的Waymo无人驾驶汽车和Ambi包裹分拣机器人,就是工程驱动路径的成功典范。
Waymo并没有试图一开始就解决所有路况下的自动驾驶问题。它首先在路况相对简单的地区进行测试,通过激光雷达等高精度传感器构建详细的地图,并依赖大量的规则和工程模型来保证安全。然后,在实际路测中持续收集数据,不断完善其感知和决策系统。
Ambi机器人则专注于包裹分拣这一特定场景。通过精巧的机械设计和优化的控制算法,它首先解决了稳定抓取各种形状包裹这一核心工程问题,然后在实际分拣工作中,利用收集的数据来提升对包裹类型的识别率和分拣效率。
工程驱动派的优点在于稳扎稳打,路径清晰,且在特定场景下能更快地实现商业化落地。但它的局限性在于,泛化能力较弱,且研发周期可能更长。每进入一个新的应用场景,都可能需要重新进行大量的建模和工程开发工作,难以实现“一招鲜,吃遍天”。
3.3 殊途同归,融合才是未来
事实上,数据驱动与工程驱动并非完全对立、非此即彼。随着行业的发展,越来越多的从业者意识到,两者必须相辅相成,融合发展。
未来的可行路径,很可能是一种**“工程为基,数据迭代”**的混合模式。
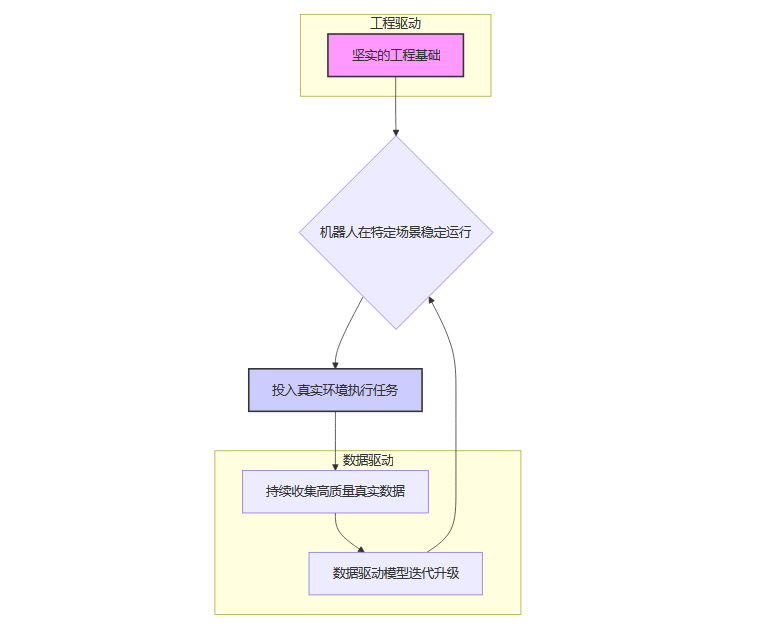
这个流程形成了一个正向的飞轮效应。
以工程为起点 利用成熟的工程技术,先让机器人具备基本的运动和操作能力,确保其在特定场景下的安全性和可靠性。这解决了“小脑”不强的问题,让机器人至少能“站得稳,走得好”。
以应用为牵引 将机器人投入到有真实需求的工业或商业场景中。这不仅能创造商业价值,更重要的是,能让机器人进入一个持续学习的真实环境。产业化应从“造人”转向“做事”,以应用驱动研发。
以数据为燃料 在实际运行中,机器人会源源不断地产生高质量、带标注的真实交互数据。这些数据是训练和优化高级智能模型(“大脑”)最宝贵的燃料。
以模型为引擎 利用收集到的数据,不断迭代升级机器人的感知、决策和规划模型,使其能够应对更复杂的场景,处理更多样的任务,从而扩展其应用边界。
这场路线之争并非简单的二选一,三种路径的优劣与未来方向,清晰地展现在我们面前。
四、📢 喧嚣与冷静,产业现状的真实剖面
%20拷贝.jpg)
在技术路线的争论背后,是整个产业在喧嚣与冷静之间的摇摆。一方面,科技领袖们描绘的宏伟蓝图和资本市场的热捧,让行业充满了乐观甚至狂热的气氛;另一方面,冰冷的技术现实和商业化难题,又让每一个从业者如履薄冰。
4.1 过度炒作下的公众认知误区
“人形机器人将在五年内超越人类外科医生。”
“未来,每个家庭都将拥有一个机器人管家。”
类似这样来自科技领袖(如马斯克)的乐观预测,极大地激发了公众的想象力,也推高了市场的期望值。在ChatGPT等AI产品取得突破后,许多人形成了一种认知惯性,认为既然语言问题已经被解决,那么物理世界的智能突破也就在眼前。
然而,戈德伯г等一线专家普遍认为,当前的宣传热潮存在严重的过度炒作成分,夸大了机器人的实际能力。公众对于机器人技术的认知存在显著误区。他们看到的,往往是经过精心编排、在理想环境下录制的演示视频。视频中机器人流畅地叠衣服、泡咖啡,却很少展示其背后成百上千次的失败尝试,以及对环境条件的苛刻要求。
这种认知偏差是危险的。它不仅可能误导投资,让资源流向那些华而不实的项目,还可能在技术无法兑现承诺时,引发公众的失望和信任危机,从而对整个行业的长远发展造成伤害。现实是,马斯克所描绘的未来并非不可能,但至少在接下来的几年甚至十年内,都还无法达成。
4.2 成本与商业化的双重枷锁
除了技术难题,高昂的成本和不明朗的商业化前景,是悬在所有人形机器人公司头上的达摩克利斯之剑。
一台功能相对完善的人形机器人原型,其硬件成本动辄数十万甚至上百万美元。这其中包含了高性能的电机、减速器、传感器、计算单元等一系列精密部件。如此高昂的造价,决定了它在短期内不可能成为大众消费品。
在商业化落地方面,行业也面临着“先有鸡还是先有蛋”的困境。
没有大规模应用 就无法摊薄高昂的研发和制造成本,也无法积累足够的数据来提升机器人的能力。
没有足够强的能力和足够低的成本 机器人就无法在实际应用中创造足够的价值,也就无法说服企业或个人为其买单。
因此,专家们普遍建议,人形机器人的产业化应采取更为务实的策略。优先在工业场景落地,例如汽车制造、物流仓储等。这些场景环境相对结构化,任务相对明确,且对成本的承受能力更高。机器人可以作为“特种工”,替代人类从事高强度、重复性或危险性的工作。
通过在工业领域的应用,机器人公司可以获得稳定的现金流,打磨核心技术,并逐步降低硬件成本。当技术更成熟、成本更可控之后,再逐步向商业服务、家庭等更复杂的场景渗透。至于真正进入家庭成为“智能管家”,行业共识是,至少还需要7到10年甚至更长的时间。
综合来看,当前人形机器人产业正是在这种技术加速与落地谨慎、公众热望与现实骨感的交织中前行,其整体现状可概括如下。
总结
人形机器人的发展之路,远比其在数字世界的“兄弟”——AI聊天机器人——要崎岖得多。一场持续了“十万年”的数据饥荒,让它在物理世界的智慧启蒙之路上步履维艰。莫拉维克悖论如同一个古老的魔咒,让那些对人类而言最简单的感知和运动,变成了对机器人最困难的挑战。
面对困境,行业走到了数据与工程的十字路口。纯粹的数据驱动如同空中楼阁,缺乏根基;而完全固守传统工程,又可能错失人工智能带来的范式革命。未来的方向,必然是两者的深度融合——以坚实的工程学为骨架,让机器人在真实世界中站稳脚跟;再以持续流动的数据为血液,为其注入不断进化的智能与灵魂。
我们必须对人形机器人的发展保持耐心和理性。它不是一场百米冲刺,而是一场考验耐力、智慧和毅力的马拉松。我们需要冷静地戳破过度宣传的泡沫,正视技术与商业化的现实挑战。从“做事”而非“造人”开始,以应用为驱动,在工业等可控场景中稳扎稳打,逐步积累技术、数据和市场信任。
那道长达十万年的鸿沟虽然深远,但并非不可逾越。每一次技术的进步,每一次应用的落地,都在为跨越这道鸿沟搭建桥梁。当工程的严谨与数据的力量真正交汇时,我们或许才能迎来人形机器人从“炫技”走向“实用”的真正曙光。
📢💻 【省心锐评】
别总盯着机器人会不会后空翻,先让它在流水线上拧好一颗螺丝钉。物理世界的智能,没有捷径,唯有从最枯燥的应用场景中,一步一个脚印地“磨”出来。

评论