.png)


【摘要】哈佛开源平台ToolUniverse,通过自进化工具生态,赋能非专业人士构建AI科学家,实现科研民主化。

引言
科学研究的现代化进程,伴随着工具和数据的爆炸式增长。每个细分领域都积累了海量的专用数据库、分析软件和计算模型。这种繁荣的背后,是一个日益严峻的挑战,即工具孤岛。不同工具间接口各异、数据格式不通、调用方式复杂,形成了一道道无形的壁垒。科研人员需要花费大量精力学习和适配这些工具,而非专注于科学问题本身。传统的AI系统,往往被设计为解决特定问题的“专家”,面对跨领域的复杂任务时,显得力不从心。
哈佛医学院领导的跨机构团队,正视了这一根本性难题。他们提出的ToolUniverse框架,并非意在构建另一个“更聪明”的AI模型,而是旨在打造一个元层次的解决方案,一个能够统一、管理、调度、甚至创造所有科研工具的“工具的宇宙”。其核心思想,是从根本上改变AI与科学工具的交互模式,将AI从一个被动的工具使用者,转变为一个主动的、能够驾驭整个工具生态的“科学家”。
这篇长文将深入剖析ToolUniverse的架构设计、核心机制、实践路径及其在真实科研场景中的应用。我们将探讨它如何通过一个自我进化的生态系统,真正降低科研门槛,并展望其对未来科学范式可能带来的深远影响。
🚀 一、ToolUniverse架构解析:不止于工具调用
%20拷贝.jpg)
ToolUniverse的设计哲学,是构建一个能够自我完善和扩展的生态系统,而非一个固化的工具集合。其根基在于一套标准化的交互协议,其能力则源于六大核心组件的精密协同。这套架构确保了系统不仅能“用”工具,更能“理解”、“组合”、“创造”和“优化”工具。
1.1 生态系统的基石:AI-工具交互协议
现代软件工程的成功,很大程度上得益于API(应用程序编程接口)的标准化。ToolUniverse借鉴了这一思想,定义了一套统一的AI-工具交互协议。这个协议是整个生态能够运转的基石。
它要求每一个被集成到ToolUniverse的工具,都必须提供一份标准化的“身份证”或元数据描述。这份描述通常包含以下关键信息:
工具名称 (Tool Name):一个唯一的、人类可读的标识符。
功能描述 (Description):用自然语言清晰说明该工具的用途、能解决什么问题。这是AI模型理解工具功能的关键。
输入参数 (Input Parameters):定义调用该工具需要提供哪些参数,包括参数名、数据类型、是否必需以及详细描述。
输出格式 (Output Format):明确工具执行成功后返回结果的数据结构和类型。
使用示例 (Examples):提供一两个具体的调用示例,帮助AI更好地理解和使用。
通过这套协议,AI模型无需关心工具底层的实现细节。无论是调用一个本地的Python函数、一个远程的Web API,还是控制一台实验室的物理设备,AI都使用同样标准化的方式进行交互。这种抽象和解耦,是实现大规模工具集成的先决条件。
1.2 六大核心组件协同机制
ToolUniverse的强大能力,体现在其六个核心组件的协同工作上。它们构成了一个从需求理解到任务执行,再到能力进化的完整闭环。
1.2.1 工具发现者 (Tool Retriever)
当AI科学家接收到一个科研任务时,首要步骤是找到合适的工具。工具发现者扮演了“智能图书管理员”的角色,它采用混合搜索策略来确保查找的准确性和全面性。
关键词搜索 (Keyword Search):基于传统的文本匹配,速度快,适用于精确的功能查找。
语义搜索 (Semantic Search):将用户的自然语言需求和工具的功能描述,通过语言模型转换为向量。通过计算向量相似度,可以找到功能相近但表述不同的工具。例如,用户说“比较两个蛋白的相似度”,语义搜索能同时找到名为“Protein Sequence Alignment”和“Protein Structure Similarity”的工具。
LLM驱动的智能推荐 (LLM-based Recommendation):对于更复杂的、多步骤的任务,工具发现者会直接请求一个大型语言模型(LLM)进行推理,由LLM根据任务上下文,推荐一个或一组工具。
这三种策略互为补充,系统会根据任务的复杂度和模糊性,动态调整它们的权重。
1.2.2 工具调用者 (Tool Executor)
找到工具后,工具调用者负责安全、可靠地执行。它的职责包括:
参数校验:在执行前,严格检查AI提供的参数是否符合工具定义的规范,防止因格式错误导致执行失败。
环境隔离:在沙箱环境中执行工具代码,避免潜在的安全风险,特别是对于那些由AI自动生成的工具。
结果解析:将工具返回的原始输出,解析成标准化的数据结构,再反馈给AI模型。
异常处理:捕获执行过程中的所有错误,并将其转化为AI能够理解的、结构化的错误信息,帮助AI进行调试或调整策略。
1.2.3 工具管理者 (Tool Manager)
工具管理者是整个生态的“仓库管理员”,负责工具的注册、版本控制和生命周期管理。它支持两种主要的工具集成方式:
本地工具 (Local Tools):直接以代码形式(如Python函数)集成到系统中,执行效率高。
远程工具 (Remote Tools):通过API端点进行集成,可以是企业内部的私有服务,也可以是公共的Web API。这种方式提供了极大的灵活性和扩展性。
工具管理者还维护着所有工具的元数据,并确保这些信息在整个系统中保持一致和最新。
1.2.4 工具组合器 (Tool Composer)
单个工具的能力是有限的。解决复杂的科研问题,通常需要将多个工具串联成一个工作流。工具组合器就是“流程编排大师”。它允许AI以**有向无环图(DAG)**的形式,规划复杂的研究流程。
例如,一个药物发现任务可以被编排为如下流程:
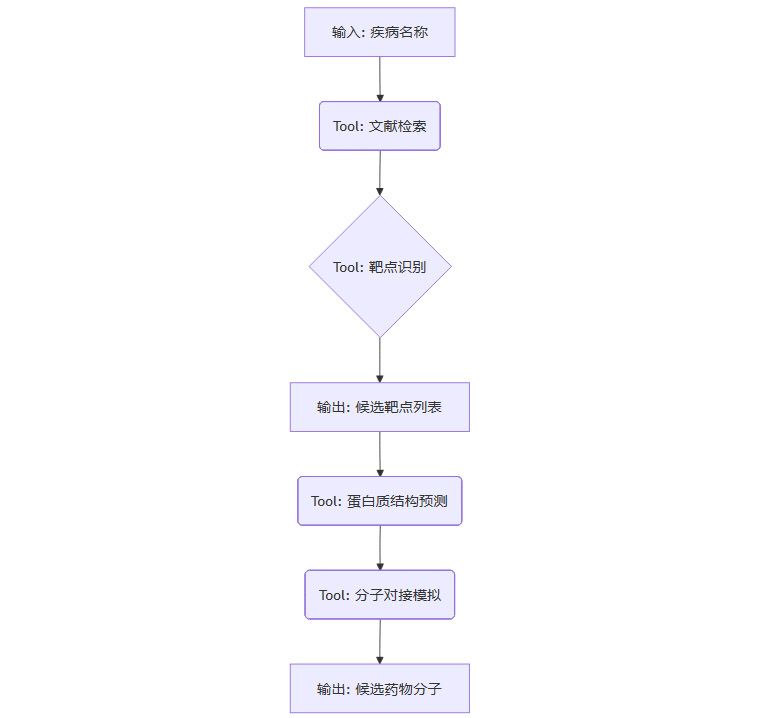
工具组合器支持并行执行、条件分支和循环等复杂的流程控制,使得AI能够像人类科学家一样,设计并执行多步骤的实验方案。
1.2.5 工具发明者 (Tool Inventor)
这是ToolUniverse最具突破性的组件。当AI在工具库中找不到满足特定需求的工具时,工具发明者可以根据自然语言描述自动创造新工具。这个过程大致分为几步:
需求规格化:AI将模糊的需求(例如,“我需要一个计算分子摩尔质量的工具”)转化为标准化的工具规格,包括函数名、参数和返回值定义。
代码生成:调用一个擅长编码的大型语言模型(如GPT-4、Codex),根据规格生成工具的源代码(通常是Python)。
自动化测试:AI会同步生成一系列单元测试用例,来验证新生成代码的正确性。
沙箱执行与验证:在隔离环境中运行测试。如果通过,新工具将被自动注册到工具管理者中,立即可用。如果失败,错误信息会反馈给代码生成模型,进行迭代修复。
这个组件让ToolUniverse的工具库具备了无限增长的潜力。
1.2.6 工具优化器 (Tool Optimizer)
一个工具被创造出来只是开始。工具优化器负责持续改进生态中所有工具的质量。它的工作方式是:
监控使用反馈:记录工具被调用时的成功率、失败原因以及AI的后续行为。如果AI频繁在调用某个工具后需要进行额外的数据处理,这可能意味着该工具的输出格式不够友好。
优化元数据:根据使用数据,自动重写或补充工具的功能描述,使其更容易被工具发现者找到,也更容易被AI理解。
建议接口变更:分析失败案例,向工具的维护者(或工具发明者)提出改进建议,例如增加一个可选参数,或改变返回值的结构。
1.3 自我进化的闭环
这六大组件共同构成了一个动态的、自我进化的闭环系统。
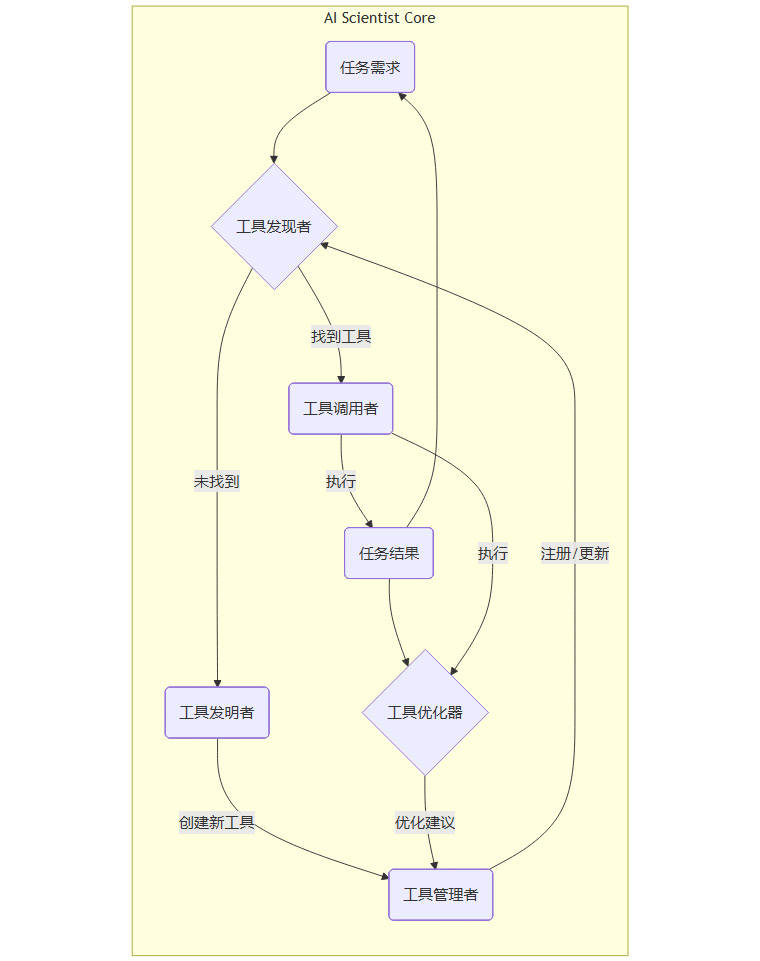
这个闭环意味着,ToolUniverse越被使用,就会变得越好用。AI在使用过程中遇到的问题,会成为系统自我完善的养料。新需求的出现,会驱动新工具的诞生。这种自学习、自扩展的能力,是它与传统静态工具平台最本质的区别。
🔧 二、构建AI科学家:三种实践路径
ToolUniverse作为一个框架,提供了极大的灵活性。用户可以根据自己的技术背景、应用场景和算力资源,选择不同的方式来构建AI科学家。官方推荐了三种由浅入深的实践路径。
2.1 路径一:轻量级集成 (Lightweight Integration)
这是最简单、最快速的入门方式,几乎不需要任何编程。它利用了现有大型语言模型(如GPT系列、Claude、Gemini)强大的自然语言理解和工具调用能力。
实现方式:用户只需安装ToolUniverse的Python包,然后通过几行配置代码,将其连接到选定的大型语言模型API。
工作流程:用户在对话界面用自然语言提出研究问题。LLM接收到问题后,会以函数调用的形式,向ToolUniverse请求使用某个工具。ToolUniverse执行工具后,将结果返回给LLM,LLM再将结果整合成自然语言回答给用户。
适用场景:适用于探索性研究、数据查询、文献分析等相对简单的任务。
优点:部署快,成本低,用户体验友好。
缺点:AI的自主规划能力受限于所选LLM的通用能力,对于需要长期、复杂规划的任务可能表现不佳。
2.2 路径二:自主代理驱动 (Autonomous Agent-Driven)
此路径利用了专门的AI代理(Agent)框架,如LangChain、LlamaIndex或Google的Gemini CLI。这些框架本身就具备更强的任务规划、记忆和多步推理能力。
实现方式:将ToolUniverse作为这些AI代理框架的一个核心工具集进行集成。代理系统负责顶层的任务分解和规划,ToolUniverse则作为其执行具体科学计算和数据操作的“手臂”。
工作流程:用户给代理设定一个高层目标(例如,“为高胆固醇血症寻找潜在的新药靶点”)。代理会自动将目标分解为一系列子任务,并在每个子任务中,自主决定调用ToolUniverse中的哪个工具。它能够处理失败、重试,并根据中间结果动态调整后续计划。
适用场景:需要多步骤、跨工具协作的复杂研究项目。
优点:AI的自主性和规划能力大大增强,能够处理更复杂的科研流程。
缺点:配置和调试相对复杂,对用户的技术要求略高。
2.3 路径三:领域专用强化学习 (Domain-Specific Reinforcement Learning)
这是最前沿、也是最强大的路径。它旨在为特定的科学领域,训练出高度专业化的AI科学家。
实现方式:研究团队为特定领域(如药物研发、基因组学)创建一个专门的AI代理模型,例如
TxAgent或GeneAgent。这个代理不仅在推理时使用ToolUniverse,更重要的是,它在训练阶段就与ToolUniverse的环境进行交互。通过强化学习,代理在虚拟的科研环境中不断试错,学习如何最高效、最准确地使用工具组合来达成科研目标。工作流程:这种AI科学家就像一个在该领域工作多年的虚拟专家。它不仅知道每个工具的功能,还积累了大量的“实践经验”,知道在何种情况下,哪种研究策略的成功率更高。
适用场景:需要深度领域知识和高度优化研究策略的核心研发环节。
优点:性能最优,具备接近甚至超越人类专家的领域问题解决能力。
缺点:训练成本极高,需要大量的领域数据和计算资源,技术门槛最高。
三种构建路径对比
这三种路径并非相互排斥。一个研究团队完全可以根据项目的不同阶段,灵活组合使用。例如,在项目初期使用路径一进行快速的文献调研和头脑风暴,在项目执行阶段切换到路径二进行系统的流程化研究,对于最核心的创新环节,则可以依赖路径三训练出的专家代理。
💡 三、真实世界验证:AI药物研发全流程复盘
%20拷贝.jpg)
理论的优雅,最终需要通过实践来检验。ToolUniverse团队选择了一个极具挑战性的真实世界任务,来展示其系统的综合能力,即从零开始为高胆固醇血症发现一种新的治疗药物。这个案例完整复现了早期药物发现的全流程,其复杂度和专业性远超一般的AI任务。
3.1 任务定义与规划
AI科学家的初始任务指令非常简洁:“为高胆固醇血症开发一种新药”。AI代理(采用路径二或路径三构建)首先将这个宏大目标分解为一系列逻辑清晰的阶段性任务:
靶点识别 (Target Identification):找到与该疾病相关的、有潜力成为药物作用靶点的蛋白质。
靶点验证 (Target Validation):分析候选靶点的生物学特性,确认其作为药物靶点的可行性。
先导化合物筛选 (Lead Compound Screening):寻找能够与选定靶点相互作用的已知化合物。
分子优化与ADMET预测 (Molecule Optimization & ADMET Prediction):对先导化合物进行结构优化,并预测其成药性(吸收、分布、代谢、排泄、毒性)。
新颖性分析 (Novelty Analysis):通过专利检索,评估最终候选分子的创新性和商业价值。
3.2 阶段一:靶点识别
AI首先调用了多个生物信息学数据库工具,如OpenTargets和GeneCards,输入关键词“hypercholesterolemia”。系统整合了来自不同数据库的基因-疾病关联数据,并进行排序,初步筛选出11个高度相关的潜在靶点。
接着,AI调用PubMed文献检索工具,对每个候选靶点进行深入的文献调研,分析其研究热度、已有的药物研究以及作为靶点的优缺点。经过综合评估,AI最终选择了**HMG-CoA还原酶(HMGCR)**作为首要目标。这是一个非常合理的选择,因为目前广泛使用的他汀类降脂药,正是作用于此靶点。这从侧面验证了AI的科学判断力。
3.3 阶段二:靶点验证
确定靶点后,AI需要了解其在人体内的详细情况。它调用了Human Protein Atlas工具,查询HMGCR在不同组织和器官中的表达水平。
发现1:HMGCR在肝脏中高度表达。这是一个积极信号,因为肝脏是胆固醇合成的主要场所,靶向肝脏能有效降低全身胆固醇水平。
发现2:HMGCR在胃肠道和大脑中也有一定程度的表达。这揭示了潜在的副作用风险,解释了为何部分他汀类药物会引起胃肠道不适或神经系统症状。
基于此,AI设定了后续药物设计的关键目标:寻找一种能够高效抑制肝脏HMGCR,同时尽可能减少对中枢神经系统渗透的化合物。
3.4 阶段三:先导化合物筛选
AI首先访问DrugBank数据库,检索所有已知的HMGCR抑制剂。它找到了包括洛伐他汀(Lovastatin)、普伐他汀(Pravastatin)在内的多种他汀类药物。
AI选择了洛伐他汀作为优化的起点。选择它的理由很巧妙,洛伐他汀疗效确切,但其一个显著缺点是亲脂性较强,容易穿过血脑屏障,这与AI在上一阶段设定的优化目标(减少脑部渗透)形成了完美的“矛盾”,为AI展示其优化能力提供了舞台。
随后,AI使用ChEMBL数据库工具,搜索与洛伐他汀结构相似的所有化合物,共找到了32个候选类似物。
3.5 阶段四:分子优化与ADMET预测
这是整个案例技术含量最高的部分。AI对这32个候选化合物,以及作为对照的洛伐他汀和普伐他汀,进行了一系列复杂的计算模拟。
它并行调用了两个强大的机器学习模型工具:
Boltz-2:一个用于预测化合物与靶蛋白结合亲和力的模型。ADMET-AI:一个用于预测化合物ADMET属性(包括血脑屏障通透性、溶解度、代谢稳定性等)的集成模型。
为了保证结果的稳健性,AI对每个化合物的每个预测任务都独立运行了四次,然后计算结果的平均值和标准差。这个操作模拟了科研中的重复实验,体现了严谨的科学态度。
关键预测结果对比
分析结果令人振奋。AI不仅成功“再发现”了普伐他汀(一个相对于洛伐他汀的改良药物,其主要优势就是水溶性更好,不易进入大脑),更重要的是,它识别出了一个全新的、表现更优的候选分子:CHEMBL2347006。该分子在预测的靶点结合能力上强于洛伐他汀,同时其穿过血脑屏障的概率比普伐他汀还要低。
3.6 阶段五:专利分析与结论
发现一个有潜力的分子还不够,还需要确认其新颖性。AI最后阶段的任务是进行专利分析。它调用了PubChem数据库工具和通用的网页抓取工具,搜索与CHEMBL2347006相关的专利信息。
最终,AI发现该化合物的结构,已被两项分别于2019年和2021年提交的专利所涵盖,专利内容正是关于其在心血管疾病治疗中的应用。
这个发现是整个案例的点睛之笔。它以一种无可辩驳的方式,验证了AI的整个发现过程是科学有效的。AI独立走完的科研路径,最终指向了一个已经被人类科学家和制药公司认可、并投入资源进行专利保护的创新分子。这雄辩地证明了ToolUniverse赋能的AI科学家,具备了进行真实世界科学发现的潜力。
⚖️ 四、横向对比:ToolUniverse在AI工具生态中的定位
ToolUniverse并非凭空出现。它的诞生,是建立在近年来AI“模型即服务”和“工具化”趋势的浪潮之上。要准确理解其价值,需要将其置于更广阔的AI工具生态中进行比较,特别是与大家熟知的OpenAI插件体系和LangChain等框架进行对比。
4.1 与OpenAI插件体系的异同
OpenAI为ChatGPT推出的插件体系,是“模型+工具”模式最广为人知的实践。用户可以在ChatGPT中启用各种插件,让模型具备联网、计算、预订等现实世界的能力。
共同点:
核心理念一致:两者都旨在通过连接外部工具,来扩展大型语言模型的能力边界。
基于标准化接口:都要求工具提供者遵循一套标准的API规范(如OpenAPI Specification),以便模型能够理解和调用。
不同点:
生态开放性:OpenAI插件体系是一个中心化的、受控的生态。插件需要经过OpenAI的审核才能上架,整个生态由OpenAI主导。而ToolUniverse是一个去中心化的、完全开源的框架,任何人都可以自由地集成、开发和分发工具,不受单一平台的限制。
功能侧重点:OpenAI插件更侧重于通用生活和工作效率类工具。ToolUniverse则深度聚焦于科学研究领域,其内置工具、核心组件和优化方向,都是为科研场景量身定制的。
动态能力:OpenAI插件体系中的工具是静态的。开发者上传后,模型只能被动调用。ToolUniverse的核心优势在于其动态性,即工具发明者和优化器带来的自我进化能力。这是两者最本质的区别。
ToolUniverse vs. OpenAI Plugins
4.2 与LangChain等代理框架的关系
LangChain是目前最流行的AI代理开发框架之一。它提供了一系列组件和链(Chains),帮助开发者构建能够调用工具、拥有记忆、进行规划的复杂AI应用。
关系定位:ToolUniverse与LangChain并非竞争关系,而是互补和协作的关系。可以将LangChain视为构建AI科学家“大脑”和“神经系统”的框架,而ToolUniverse则是为其提供专业化“手臂”和“工具箱”的资源库。
功能边界:
LangChain的强项在于代理的控制流和状态管理。它擅长处理多轮对话、维护记忆、实现复杂的ReAct(Reason+Act)逻辑循环。
ToolUniverse的强项在于科学工具的生态管理。它提供了更丰富的科学工具集、更专业的工具发现机制,以及LangChain本身不具备的工具创造和优化能力。
在实践中,最佳做法是将两者结合使用。在前面提到的“路径二:自主代理驱动”中,开发者可以使用LangChain来构建AI科学家的核心代理逻辑,然后将ToolUniverse作为一个强大的自定义工具集,无缝集成到LangChain的工具库中。这样,既能利用LangChain成熟的代理架构,又能享受到ToolUniverse庞大且能自我进化的科学工具生态。
4.3 独特的价值主张
综合来看,ToolUniverse在拥挤的AI工具生态中,找到了一个清晰且独特的定位。它的价值主张可以总结为以下三点:
深度垂直于科学研究:它不是一个“什么都能做”的通用工具平台,而是一个为科学发现量身打造的专业化环境。
从“工具调用”到“工具创造”:它超越了现有框架的范畴,首次将AI的角色从工具使用者,提升到了工具创造者和优化者的高度。
构建一个开放、自进化的生态:其开源和去中心化的特性,以及内置的自学习机制,使其有潜力成为一个由全球科研社区共同构建、持续成长的基础设施。
🛡️ 五、可靠性与质量保证:构建可信的科研基础设施
%20拷贝.jpg)
在科学研究领域,结果的准确性、可靠性和可重现性是生命线。任何一个微小的错误,都可能导致整个研究方向的偏差。因此,ToolUniverse团队在系统设计之初,就将质量保证(QA)放在了至关重要的位置,构建了一套多层次、全方位的保障体系。
5.1 多层次的验证机制
这套体系确保了进入生态的每一个工具,都经过了严格的审查和测试。
第一层:自动化单元测试:
对于每一个新集成的工具,特别是AI自动生成的工具,系统都要求提供或自动生成一套完整的单元测试用例。
这些测试覆盖了工具的常规输入、边界条件和已知的异常情况。
任何工具的更新,都必须通过全部单元测试,才能被合并到主工具库中。
第二层:输入输出采样测试:
研究团队为不同类别的工具,维护了一个基准测试集(Benchmark)。
工具在集成前,需要在这个基准测试集上运行,其输出结果会与已知的“黄金标准”进行比对。
这确保了工具不仅能正常运行,而且其输出结果在科学上是准确的。
第三层:人工专家审查:
对于涉及复杂领域知识的工具(如生物信息学模型、化学性质预测器),其输出结果会提交给相关领域的专家进行人工审查。
专家会评估结果的合理性、可解释性,以及是否符合当前的科学共识。
5.2 来源可追溯与可信度评级
ToolUniverse优先集成来自权威和可信来源的工具。
来源优先:系统会优先收录来自政府机构(如NIH, FDA)、顶尖学术机构、知名开源项目和经过同行评议的科学期刊发布的工具。
可信度标签:每个工具都会被打上来源标签,并根据其来源的权威性、社区的活跃度和历史表现,给出一个动态的可信度评级。AI在选择工具时,会优先考虑评级更高的工具。
5.3 可重现性保障机制
科学研究的核心要求之一是可重现性。ToolUniverse通过以下机制来保障这一点:
版本锁定:AI科学家在执行一个完整的科研项目时,会记录下其使用的每一个工具的精确版本号。这确保了其他研究者可以使用完全相同的环境,来复现整个研究过程。
随机性控制:对于包含随机过程的工具(如某些机器学习模型),系统要求其提供设置随机种子的功能。AI在调用时会自动记录所用的种子,确保结果可以精确复现。
详尽日志:整个科研流程的每一步,包括AI的思考过程(Chain of Thought)、调用的工具、输入的参数和返回的结果,都会被完整地记录下来,形成一份可供审计和复现的详细实验记录。
5.4 持续的社区反馈与改进
作为一个开源项目,社区的力量是其质量保证体系的重要组成部分。
结构化反馈渠道:用户在使用过程中发现任何问题,都可以通过GitHub Issues等渠道,提交结构化的错误报告或改进建议。
激励机制:项目鼓励社区成员贡献新的高质量工具、修复现有工具的Bug、或改进工具的文档。优秀的贡献者会在项目中得到认可。
动态退役机制:科学在不断进步,工具也会过时。当一个工具被更先进、更准确的替代品出现时,或者其依赖的外部服务不再维护时,社区和维护团队会启动退役流程,将其标记为“不推荐”,并引导用户迁移到新的工具上。
通过这套严密的质量保证体系,ToolUniverse力求从一个功能强大的平台,转变为一个值得信赖的科研基础设施。它不仅要赋能创新,更要对创新的严谨性和可靠性负责。
展望与挑战
ToolUniverse描绘了一幅激动人心的未来图景,即科学研究的民主化。在这个未来里,一个有创意的生物学高中生,或是一个资源有限的初创公司的工程师,都有可能利用自己的AI科学家助手,做出世界级的科学发现。然而,通往这个未来的道路,依然充满挑战。
数据质量与可及性:AI的智慧,根植于高质量的数据。目前,大量的科研数据仍然以非结构化的形式存在于论文中,或者被锁定在私有的、互不联通的数据库里。打破数据孤岛,建立高质量、标准化的公共科学数据集,是整个领域面临的共同挑战。
AI的可解释性与信任:在药物研发等高风险领域,仅仅得到一个“正确”的答案是不够的。科学家需要理解AI是如何得出这个结论的。提升AI决策过程的透明度和可解释性,建立人与AI科学家之间的信任关系,是其能否被广泛应用的关键。
伦理与安全:当AI具备了设计新分子甚至新生物体的能力时,相关的伦理和安全问题也随之而来。如何防止这些强大的工具被滥用,如何制定相应的监管和伦理规范,是需要整个社会共同思考的问题。
人机协作的范式:ToolUniverse并非要取代人类科学家,而是要成为他们的得力助手。探索最高效的人机协作模式,让人类专注于提出创造性的假设和进行最终的决策,而AI负责繁重的数据处理和实验执行,将是未来科研的新范式。
结论
ToolUniverse的出现,是AI在科学领域应用的一个里程碑。它通过一个巧妙的、自我进化的架构,系统性地解决了科研工具分散和异构的核心痛点。其核心贡献,并不仅仅是集成了600多个工具,而是提供了一套让AI从工具的使用者,转变为工具的创造者和生态建设者的机制。
通过在药物研发案例中的惊艳表现,ToolUniverse证明了AI科学家已经具备了处理真实世界复杂科研任务的潜力。它所倡导的开源、开放、可进化的生态模式,为实现“人人皆可为科学家”的愿景,铺设了一条切实可行的道路。
尽管前路仍有挑战,但ToolUniverse无疑已经按下了科学研究范式变革的加速键。它所开启的,是一个人类智慧与机器智能深度融合,共同探索未知边界的新时代。
📢💻 【省心锐评】
ToolUniverse的核心是“授人以渔”,它不直接给答案,而是提供了一个能自我进化的“AI科学家制造工厂”,将科研能力从精英阶层解放出来,这才是真正的颠覆。

评论