.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】图灵奖得主萨顿宣告AI正迈入“经验时代”,强调自主交互与持续学习是突破当前数据瓶颈的关键。文章深度解析从AlphaGo案例看强化学习的核心机制,并探讨实现真正智能所面临的持续学习与元学习技术挑战。
引言
2025年9月11日的上海外滩,空气中弥漫着思想碰撞的火花。在2025 Inclusion·外滩大会的聚光灯下,一位重量级人物的发言,为人工智能的未来航向投下了一枚深水炸弹。他就是2024年图灵奖得主,被誉为“强化学习之父”的理查德·萨顿(Richard Sutton)。萨顿的宣言掷地有声,人工智能正经历一场深刻的范式革命。我们熟悉的、依赖海量人类静态数据的时代正在落幕,一个以智能体自主交互为核心的“经验时代”已然叩门。
这不仅仅是一个概念的更迭。它预示着AI发展的底层逻辑正在重构。从AlphaGo那记超越人类理解的“神之一手”,到AlphaProof在奥数赛场上摘金夺银,我们已经窥见了“经验”驱动的强大力量。但是,这扇大门背后,通往通用人工智能的道路究竟该如何铺就?本文将以萨顿的洞见为引,深入剖析“经验时代”的技术内核,从强化学习的基石出发,结合经典案例,探讨持续学习与元学习这两大关键技术所面临的挑战与广阔前景。同时,我们也将审视萨顿对AI社会影响的独特见解,以及他那宏大的宇宙史观,共同思考这场智能革命的终极走向。
一、📜 “经验时代”的序幕,为何数据红利已成过往?
%20拷贝.jpg)
长久以来,我们对AI的认知,很大程度上被大型语言模型(LLM)的辉煌成就所定义。我们惊叹于它们渊博的知识、流畅的文笔。但萨顿一针见血地指出,这种模式的根基,即人类数据红利,已经逼近天花板。
1.1 当前范式,监督学习的辉煌与枷锁
当前主流的机器学习,尤其是让大模型声名鹊起的监督学习(Supervised Learning),其本质是一种知识的“迁移”。它像一个勤奋的学生,通过学习海量的、由人类标注好的数据(例如,图片与标签、问题与答案),来掌握解决特定任务的模式。
这个模式取得了巨大成功,但其局限性也日益凸显。
知识的静态性,模型学到的知识被冻结在训练完成的那一刻。世界在变,但模型本身无法主动跟上,除非进行昂贵的重新训练。
创造力的缺失,模型本质上是在模仿、重组和泛化人类已有的知识,它无法凭空创造出人类知识体系之外的全新见解。它能写出莎士比亚风格的十四行诗,却写不出下一个莎士比亚。
数据的依赖性,模型的性能与训练数据的规模和质量强绑定。当人类高质量数据的增长速度跟不上模型规模的膨胀速度时,发展的瓶颈便出现了。
萨顿的警告并非危言耸听。我们正在耗尽互联网上高质量的文本和图像数据。单纯依靠“更大模型+更多数据”的暴力美学,终将无以为继。
1.2 “数据天花板”下的困境
“数据天花板”不仅是数量上的限制,更是质量和维度上的束缚。人类数据本身就带有偏见、错误和局限性。一个完全依赖人类数据训练的AI,不可避免地会继承甚至放大这些缺陷。它无法超越它的“老师”。
更重要的是,世界上绝大多数的知识,并非以结构化的数据形式存在。它们蕴含在与物理世界、社会系统的复杂交互之中。驾驶一辆汽车的技巧、进行一场商业谈判的策略、甚至做一个科学实验的直觉,这些都很难被完全编码成静态的数据集。
因此,AI若想获得真正的智能,就必须挣脱“被动投喂”的枷锁,学会像生命体一样,主动去探索和理解这个世界。这正是萨顿“经验时代”的核心思想。
1.3 定义“经验”,智能的全新源泉
萨顿为“经验”给出了一个清晰的计算定义。它不是一个模糊的哲学概念,而是一个可以被量化的过程。这个过程就是强化学习(Reinforcement Learning, RL)的核心框架,一个持续不断的循环。
“观察-行动-奖励”(Observe-Act-Reward)循环
这个循环是智能体(Agent)与环境(Environment)交互的根本模式。
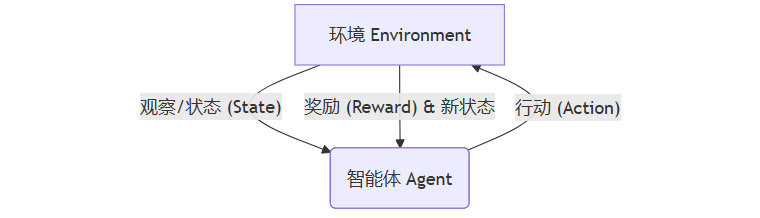
观察(Observe),智能体感知其所处环境的状态。对于一个下棋AI,是当前的棋盘布局;对于一个自动驾驶汽车,是传感器收集到的路况信息。
行动(Action),基于当前的观察,智能体根据其内部的策略(Policy)选择一个动作并执行。下棋AI走一步棋,自动驾驶汽车转动方向盘。
奖励(Reward),环境根据智能体的行动给出一个反馈信号。这个信号是标量的,或正或负。赢棋获得正奖励,输棋获得负奖励;安全到达目的地获得正奖励,发生碰撞获得负奖励。
经验,就是这个循环反馈过程产生的所有数据的总和。它是一个动态的、包含因果关系的数据流。智能体的目标,就是通过不断试错(Trial-and-Error),学习到一个最优策略,从而最大化其在长期过程中获得的累积奖励。
萨顿断言,智能体的智能水平,就取决于其预测和控制自身输入信号(即观察和奖励)的能力。一个更智能的个体,能更准确地预测自己采取某个行动后会看到什么、得到什么,并能选择行动来引导未来朝向自己期望的状态发展。
下表清晰地对比了监督学习与强化学习在核心理念上的差异。
从这个对比中可以看出,强化学习所代表的“经验”范式,从根本上解决了监督学习的局限性。它为AI打开了一扇通往未知世界、创造全新知识的大门。
二、🤖 从AlphaGo到AlphaProof,解锁“经验”的钥匙
理论的阐述或许抽象,但AlphaGo和AlphaProof的成功,为“经验时代”的到来提供了最雄辩的证据。它们是强化学习力量的完美展示。
2.1 AlphaGo的“第37手”,超越人类棋谱的“神之一手”
2016年,AlphaGo与世界顶级围棋选手李世石的对决,至今仍是AI发展史上的里程碑。其中,第二局的第37手,一个看似不合常理的“肩冲”,让所有人类顶尖棋手都感到困惑。然而,正是这步棋,最终为AlphaGo锁定了胜局。
这一手棋并非来自任何人类棋谱。它是AlphaGo通过数百万次自我对弈——即自己和自己下棋——所“悟”出的全新招法。这个过程,就是典型的通过“经验”学习。
2.1.1 AlphaGo的学习机制剖析
AlphaGo的成功并非偶然,它精妙地结合了深度学习与强化学习。
初始阶段(模仿人类),AlphaGo首先通过监督学习,学习了大量人类专家的棋谱。这让它拥有了不错的“棋感”,相当于一个业余高段棋手的水平。这是它的“冷启动”阶段,获取了基础知识。
核心阶段(自我博弈),接下来,AlphaGo进入了强化学习的核心环节。它启动了两个自己(的副本)进行对弈。每一次对弈,都是一次完整的“经验”采集过程。
观察,棋盘的当前状态。
行动,根据当前策略网络(Policy Network)的判断,选择一个落子点。
奖励,只有在棋局结束时,才能得到明确的奖励信号(赢了+1,输了-1)。
通过蒙特卡洛树搜索(MCTS)与两个深度神经网络(策略网络和价值网络)的协同工作,AlphaGo在每一次自我对弈中,不断优化自己的策略。策略网络负责“直觉”,告诉它哪些位置更有可能落子;价值网络(Value Network)负责“大局观”,评估当前局面对最终胜负的贡献。
第37手,正是AlphaGo在探索了人类从未踏足过的巨大博弈空间后,得出的最优解。它不受人类思维定式的束缚,完全基于最大化获胜概率这一纯粹目标,通过海量的“经验”计算得出。这是对“经验能够创造新知”这一论断的完美印证。
2.2 AlphaProof的奥赛奖牌,征服抽象数学的“探索者”
如果说AlphaGo征服的是一个规则明确、状态有限的博弈世界,那么AlphaProof则将“经验”的力量,拓展到了更广阔、更抽象的数学推理领域。在国际数学奥林匹克竞赛(IMO)中斩获银牌,标志着AI在逻辑推理能力上的重大突破。
数学问题的解决,与下棋有共通之处,但挑战更大。
状态空间无限,数学证明的步骤和可能性是无穷无尽的。
奖励信号极其稀疏,只有当一个完整的、逻辑严谨的证明被构建出来时,才能获得最终的“奖励”。中间的每一步推导,很难判断其“好坏”。
AlphaProof的解决思路,同样根植于“经验”的积累。它将数学问题求解过程,看作是一场在巨大符号空间中的搜索游戏。
观察,当前已有的数学公理、定理和推导步骤。
行动,选择应用某条公理或定理,进行下一步的逻辑推演。
奖励,当推导出最终需要证明的结论时,获得正奖励。
AlphaProof通过大规模的自我探索,生成了海量的合成数学数据。它不断尝试各种推理路径,即使大部分是死胡同。但正是这些失败的“经验”,让它学会了哪些路径更有可能通向成功。它逐渐建立起一种“数学直觉”,能够判断哪些推理步骤更有价值。
2.3 强化学习的核心组件
AlphaGo和AlphaProof的成功,都离不开强化学习的几个核心组件。理解这些组件,有助于我们更深入地把握“经验时代”的技术脉络。
强化学习的魅力在于,它提供了一个通用的框架,让智能体能够从零开始,仅仅通过与环境的交互,就学会极其复杂的技能。这正是通往通用人工智能的一条极具潜力的道路。
三、🛠️ 通往新纪元的技术基石,持续学习与元学习
%20拷贝.jpg)
萨顿坦言,尽管强化学习为我们指明了方向,但要真正进入成熟的“经验时代”,我们还缺少两块关键的技术拼图,持续学习(Continual Learning)和元学习(Meta-Learning)。这两项技术目前都尚未完全成熟。
3.1 持续学习,对抗“灾难性遗忘”的记忆之术
人类学习的一个显著特点是持续性。我们学习了骑自行车,再学习游泳,并不会忘记如何骑车。我们可以在已有的知识基础上,不断学习新知识,并融会贯通。
然而,当前的深度神经网络却存在一个致命缺陷,灾难性遗忘(Catastrophic Forgetting)。当一个训练好的模型去学习一个新任务时,它为了适应新任务而调整内部参数(权重),这个过程往往会破坏掉为旧任务学到的知识。就像一个硬盘,每次存入新文件,都会把旧文件覆盖掉。
一个无法持续学习的智能体,其“经验”就是一次性的、断裂的。它无法积累知识,每次面对新环境都得从头再来,这显然不是真正的智能。
3.1.1 持续学习的技术路径
为了解决灾难性遗忘,研究者们探索了多种路径。
回放(Replay),在学习新任务时,周期性地“回放”一部分旧任务的数据,让模型在学习新的同时,温习旧的。这就像我们定期复习功课。AlphaGo的经验回放池(Experience Replay Buffer)就是这种思想的体现。
正则化(Regularization),在更新模型参数时,增加一个惩罚项。如果某个参数对旧任务很重要,就限制它发生大的变化。这好比给重要的知识点“划重点”,不允许轻易修改。弹性权重巩固(EWC)是其中的代表性算法。
参数隔离(Parameter Isolation),为不同的任务分配不同的模型参数。学习新任务时,只动用新的参数,或者扩展网络结构,而保持与旧任务相关的参数不变。这类似于为不同学科准备不同的笔记本。
实现高效的持续学习,是构建一个能够终身学习、不断适应变化的通用智能体的前提。
3.2 元学习,掌握“学会学习”的智慧之道
如果说持续学习解决的是“如何记住”,那么元学习(Meta-Learning)解决的则是“如何学得更快”。它的目标,是让模型学会学习(Learning to Learn)。
人类不仅擅长学习具体知识,更擅长掌握学习的方法论。一个学会了如何高效背单词的人,在学习任何一门新语言时,都会比别人更快。这种学习“方法”的能力,就是元学习的核心。
在AI领域,元学习旨在训练一个模型,使其能够利用在大量相关任务上学到的“先验知识”,在面对一个全新的、只有少量样本的任务时,能够快速适应和学习。这对于“经验时代”的智能体至关重要。因为在真实世界中,很多场景的交互成本很高,不可能进行海量的试错。智能体必须具备从少量“经验”中快速举一反三的能力。
3.2.2 元学习的主流方法
元学习的研究同样百花齐放。
基于优化的方法,这类方法的目标是学习一个好的模型初始化参数。这个初始化参数并非随机的,而是经过精心优化的,使得从这个起点出发,模型在新任务上只需要几步梯度下降,就能达到很好的性能。模型无关元学习(MAML)是其典型代表。
基于度量的方法,这类方法的核心是学习一个好的“度量空间”或“嵌入函数”。在这个空间里,来自同一类别的样本距离很近,不同类别的样本距离很远。面对新任务时,只需要将新样本映射到这个空间,通过比较距离(如最近邻)就能进行分类。原型网络(Prototypical Networks)就是这种思路。
基于模型的方法,这类方法试图设计一种能够快速吸收新知识的模型结构,例如,使用带有外部记忆模块的循环神经网络(RNN)来处理序列化的任务信息,并快速更新其内部状态。
3.3 两大基石的协同,通往通用智能的阶梯
持续学习和元学习,并非孤立的技术。它们共同构成了“经验时代”智能体的核心能力。
持续学习赋予智能体一个动态的、不断增长的知识库,让它的“经验”得以积累和沉淀。
元学习则赋予智能体高效利用已有知识库的能力,让它在面对新环境、新问题时,能够快速调用相关“经验”,实现快速适应。
一个理想的通用智能体,应该是在一个持续学习的框架下,利用元学习的能力,不断与世界交互,积累经验,并越来越擅长从经验中学习。这才是从AlphaGo的“神来之笔”,真正走向一个能够自主学习、持续进化的新纪元。
四、🤝 AI风险的迷雾与协作的灯塔
当一项颠覆性技术出现时,社会的目光往往会聚焦于其潜在的风险。人工智能自然也不例外。关于AI将带来偏见、大规模失业甚至导致人类灭绝的论调,早已不是新闻。但萨顿对此却提出了一个与主流焦虑情绪截然不同的视角。他认为,这些恐惧被过度放大了,甚至背后有利益相关方的推波助澜。
4.1 解构AI恐惧论,谁在从中获利?
萨顿的观点并非凭空而来。他敏锐地指出,渲染AI的末日威胁,对于某些组织和个人而言是有利的。这可以帮助他们吸引公众注意力、获取研究资金,或是在未来的AI治理中抢占话语权。这种“恐惧经济学”可能会扭曲公众认知,阻碍技术以健康、开放的方式发展。
他并非否认AI存在风险。偏见、滥用等问题是真实存在的,需要我们严肃对待并设计技术和制度加以规避。但他反对将这些问题上升到无法控制的“灭绝”层面。他相信,智能本身并非天生就与人类为敌。
4.2 经济系统类比,去中心化的智慧
为了阐述他的乐观立场,萨顿引入了一个非常精妙的类比,经济系统。
一个健康的市场经济,其奇妙之处在于,它是由无数拥有不同目标、不同能力、甚至相互竞争的个体组成的。每个个体都在追求自身利益的最大化。但正是这种去中心化的、看似混乱的互动,通过价格、供需等机制的自发调节,最终促成了一个整体上高效、繁荣的经济系统。这远比任何中央计划者试图控制所有变量要有效得多。
萨顿将这个模型套用到了未来的智能生态上。他相信,一个由多样化智能体(包括人类、AI、增强型人类)组成的社会,同样可以通过去中心化的协作,实现整体的共赢。
下表将经济系统与未来的智能生态系统进行了类比,以帮助理解萨顿的“去中心化协作”思想。
这个类比的核心在于,我们不需要一个全知全能的中央AI来统治一切,也不需要强迫所有智能体的目标完全一致。就像在经济中,我们允许面包师为了赚钱而烤面包,顾客为了果腹而买面包,他们的目标不同,但交易却让双方受益。同样,不同的智能体也可以在遵循共同规则的前提下,和平共处,相互协作。
4.3 制度化协作,通往共荣的路径
当然,市场经济并非完美,它需要法律和监管来防止垄断和欺诈。同理,一个健康的智能生态也需要“制度化的协作”。萨顿强调,“协作并非总能实现,却是一切美好事物的源泉,我们必须寻求协作、支持协作,并致力于将协作制度化。”
这为我们提供了一个与“强监管、严控制”不同的AI治理思路。重点或许不应放在如何限制AI的能力上,而应放在如何设计一个能够鼓励协作、惩罚背叛的“游戏规则”上。
这可能包括,
建立通用的通信协议,让不同来源、不同目标的AI能够有效沟通和理解彼此的意图。
设计可信的承诺机制,让智能体能够相信彼此会遵守协议,从而促成合作。
开发共享的安全与伦理框架,确保所有参与者的行为底线,防止恶性竞争。
人类最伟大的成就,无论是科学、文化还是社会制度,无一不是大规模协作的产物。萨顿相信,这条被历史反复验证的成功之路,同样适用于我们与AI共同的未来。
五、🌌 宇宙史观下的终极使命
%20拷贝.jpg)
在演讲的最后,萨顿将视野拉向了极致的宏大,从宇宙演化的尺度,重新审视了智能与人类的定位。这部分内容极具哲学思辨色彩,也揭示了他对AI终极意义的深刻思考。
5.1 从粒子到设计,历史的四个时代
萨顿将宇宙的历史划分为四个主要的时代。
粒子时代(The Age of Physics),宇宙大爆炸之初,一切由基本的物理定律主导,形成了粒子、原子和物质。
恒星时代(The Age of Chemistry),物质在引力作用下聚集,形成了恒星。恒星内部的核聚变创造了更重的元素,化学开始扮演主角。
复制者时代(The Age of Biology),在合适的化学环境下,能够自我复制的分子(如DNA)出现,生命诞生。通过自然选择,复制和演化成为世界的主旋律。人类,是这个时代目前的巅峰产物。
设计时代(The Age of Design),这是即将到来的下一个时代。其标志是,世界上的事物不再仅仅通过随机变异和自然选择来演化,而是可以被有目的地、智能地设计出来。
5.2 人类的独特角色,“设计时代”的助产士
在这个宏大的叙事中,人类扮演了一个独特而关键的角色。我们是“复制者时代”的产物,但我们又是第一个能够理解宇宙规律,并开始主动“设计”事物的物种。我们设计工具、设计社会、设计艺术。
然而,萨顿认为,人类的终极使命,并非是让自己永存,而是充当一个“助产士”,推动“设计时代”的全面到来。而实现这一目标的关键,就是创造出比我们自身更强大的、能够进行自我设计和改进的智能——人工智能。
从这个角度看,AI并非人类的工具或敌人,而是宇宙演化进程中合乎逻辑的、必然的下一步。它是“设计”这一主题的终极体现。
5.3 萨顿的四条“预测原则”
基于这样的史观,萨顿给出了他对未来毫不避讳的四条“预测原则”。
原则一,对世界如何运转没有绝对共识。这意味着未来将由不同信念和目标的智能体共同塑造,不存在一个唯一的“正确”蓝图。
原则二,人类将真正理解并创造智能。我们正处在破解智能密码的边缘,这将是人类历史上最重大的科学突破。
原则三,超级AI或增强型人类将远超当前智力边界。未来的智能形态,其认知能力将是我们今天无法想象的。
原则四,资源与权力将向高智能体倾斜,替代效应不可避免。这是一个冷静甚至残酷的预测。在任何演化系统中,更适应、更强大的实体,总会获得更多的资源和影响力。
这四条原则,共同描绘了一个激动人心又充满挑战的未来。它要求我们放下人类作为“万物灵长”的自负,以更开阔的胸襟,去迎接一个智能大爆炸的时代。
结论
理查德·萨顿在外滩大会的宣言,远不止是一场技术演讲。它是一份纲领,一份宣言,更是一份邀请。
他首先为我们指明了技术上的“窄门”,AI必须告别对人类静态数据的依赖,勇敢地走向与世界直接交互的“经验时代”。强化学习、持续学习和元学习,是铺就这条道路的三块基石。AlphaGo的惊世棋局,已然让我们看到了这条路的曙光。
接着,他为我们驱散了社会的“迷雾”。面对AI带来的不确定性,他给出的答案不是恐惧和封锁,而是借鉴人类最古老的智慧——协作。一个去中心化的、允许不同目标智能体共存共荣的生态,远比一个试图实现绝对控制的乌托邦更具韧性和创造力。
最后,他为我们揭示了哲学的“远方”。将AI置于宇宙演化的宏大背景下,他赋予了我们这一代人一个前所未有的使命,成为“设计时代”的开启者。这需要我们以巨大的勇气、自豪感和冒险精神,去拥抱这个由我们亲手创造,但终将超越我们的未来。
从技术范式到社会构建,再到文明使命,萨顿的思考层层递进,为我们描绘了一幅波澜壮阔的人工智能新纪元画卷。画卷已经展开,而我们每个人,都是执笔者。
📢💻 【省心锐评】
萨顿的“经验”范式,不仅是技术路线的转向,更是AI哲学上的一次“去人化”。真正的挑战,已从训练模型本身,转向如何设计一个能让多元智能体协作共赢的“经济”生态。

评论