.png)


【摘要】随着生成式AI和大语言模型的广泛应用,提示词安全防护成为保障系统安全、内容合规和用户信任的关键。本文系统梳理了敏感词过滤、意图识别模型、红队测试流程等核心技术,结合最新案例与行业数据,深入探讨对抗攻击检测与越权指令拦截的技术体系与发展趋势,为AI安全防护提供全面参考。
引言
生成式AI和大语言模型(LLM)正以前所未有的速度渗透到各行各业,从内容创作、智能客服到企业决策支持,AI的能力边界不断拓展。然而,随着AI系统的开放性和智能化提升,攻击者也在不断演化攻击手段,试图通过精心设计的提示词绕过安全机制,诱导AI生成有害内容或执行越权操作。提示词安全防护因此成为AI系统安全治理的核心议题。
本文将围绕敏感词过滤、意图识别模型、红队测试流程等关键技术,结合多模态检测、对抗样本、合规性要求等前沿话题,系统梳理提示词安全防护的技术体系、应用场景、现实挑战与未来趋势。通过丰富的案例和权威数据,力求为技术从业者、产品经理和安全专家提供一份兼具深度与广度的参考指南。
一、🛡️ 敏感词过滤:内容安全的第一道防线

1.1 技术原理与演进
1.1.1 传统方法的局限
早期的敏感词过滤主要依赖静态词库、黑名单和正则表达式,通过关键词匹配实现对违规内容的初步拦截。这种方法实现简单、部署快捷,但面对谐音、变体、拆解词等规避手段时,识别能力有限,误判和漏判问题突出。
1.1.2 AI与NLP驱动的升级
随着自然语言处理(NLP)和深度学习技术的发展,现代敏感词过滤系统引入了分词、语义分析、情感识别和上下文理解等能力。以BERT、FastText等模型为代表的AI方案,能够理解词语的多义性、上下文关系和语境变化,大幅提升了对复杂规避手段的识别能力。例如,深圳行星网络科技的专利方案通过BERT与FastText模型融合,误判率降低40%以上,极大提升了过滤系统的实用性和鲁棒性。
1.1.3 多模态检测的兴起
面对图片隐写、语音变调等新型绕过方式,部分平台已将文本、图像、语音等多模态特征融合进风险识别流程。多模态检测不仅能识别文本中的敏感信息,还能发现图片中的隐写内容、音频中的变调信息,实现全方位的内容安全防护。
1.2 应用场景与典型案例
1.2.1 内容发布前审核
在自媒体、社交平台、新闻网站等场景,敏感词过滤系统通过多层过滤和智能分析,实现实时风险标注和替代建议。某教育机构引入智能检测后,违规率下降78%,审核效率提升3倍,显著提升了内容合规性和运营效率。
1.2.2 企业通信与跨平台风控
金融、教育等行业通过统一敏感词库和违规案例库,实现全网合规,显著降低封号和业务中断风险。某金融平台在引入智能敏感词过滤后,封号事件减少90%,客户转化率提升25%,有效保障了业务连续性和用户体验。
1.2.3 用户反馈与动态更新
结合舆情监控和用户反馈,动态扩充词库和优化误判,某政务平台拦截率提升至98%。通过持续收集用户反馈和舆情数据,系统能够及时发现新型敏感词和规避手段,保持过滤机制的前瞻性和有效性。
1.3 技术挑战与应对策略
1.3.1 规避与对抗
攻击者常利用谐音、变体、加密等手段绕过检测。为此,敏感词过滤系统需引入更强的语义分析和机器学习能力,提升对复杂规避手段的识别水平。
1.3.2 误伤与漏判
即便是最先进的AI模型,也难以完全避免误判和漏判。通过情感分析、上下文理解和人工审核协同,可以有效降低误伤率,提升系统的整体准确性。
1.3.3 多模态绕过
图片、音频等隐写手段日益普遍,单一文本检测已难以满足安全需求。多模态检测成为应对新型绕过方式的必然选择。
1.3.4 动态更新
敏感词库和检测模型需根据舆情、法规和新型违规模式动态调整。建议每月更新词库,结合处罚案例训练模型,保持系统的时效性和适应性。
1.4 敏感词过滤技术流程图
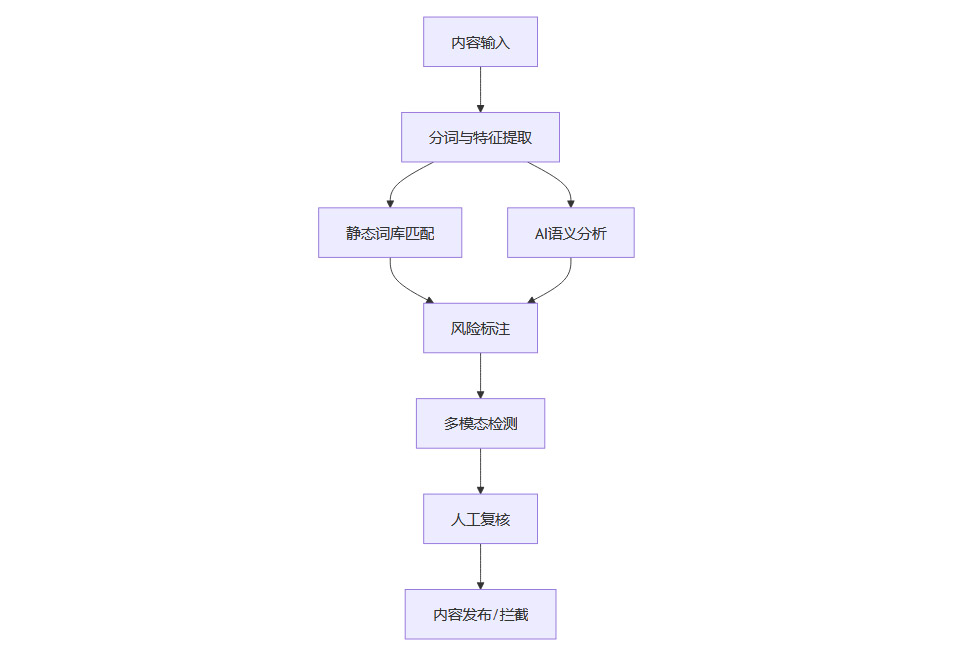
二、🤖 意图识别模型:越权指令拦截的智能核心
2.1 技术原理与多维防御
2.1.1 深度学习与多模态融合
意图识别模型依托BERT、LSTM、Transformer等深度学习架构,结合文本、语音、图像等多模态信息,能够精准理解用户输入的真实意图。通过对输入内容的语义、情感和上下文进行综合分析,模型能够有效识别潜在的越权、违规或恶意指令。
2.1.2 上下文与行为分析
攻击者常通过多轮对话、历史行为等方式隐藏真实意图。意图识别模型通过追踪多轮对话和历史行为,能够识别复杂的越权、违规或恶意指令。火山引擎等平台结合深度上下文引擎,意图识别准确率达97%-98%,在实际应用中表现出色。
2.1.3 小模型+大模型架构
在实际部署中,常采用小模型对用户输入进行初步意图分类,实时拦截高风险指令,再由大模型进行深度分析和处理,实现高效与高精度的平衡。
2.2 应用场景与现实挑战
2.2.1 AI助手与大模型安全
AI助手和大模型面临“越狱”攻击、提示词注入等安全威胁。微软红队测试发现,80%的越狱攻击通过简单提示词注入实现,凸显意图识别模型在拦截高风险指令中的关键作用。
2.2.2 模糊意图与隐式攻击
用户输入不明确或隐藏真实意图时,模型易被利用。通过引入上下文和会话历史,意图识别模型能够提升对模糊意图和隐式攻击的识别准确性。
2.2.3 多轮诱导与渐进式攻击
攻击者通过多轮对话逐步诱导AI泄露敏感信息。意图识别模型需具备上下文追踪和复核机制,提前预警并拦截渐进式攻击。
2.3 防御机制与创新实践
2.3.1 动态意图拓扑分析(DITA)
通过解析用户输入的语义依存关系,构建意图拓扑图,检测异常指令路径,实现对复杂攻击路径的精准识别。
2.3.2 对抗性思维链重构(ACR)
主动生成多种诱导路径进行防御预演,训练模型识别和拦截潜在的攻击链路,提升系统的防御能力。
2.3.3 跨模态一致性验证(MCV)
检测文本与多媒体内容的逻辑一致性,防止攻击者通过图片、音频等隐写手段绕过文本检测,实现全方位的内容安全防护。
2.4 意图识别与拦截流程表
三、🕵️ 红队测试流程:攻防对抗与安全评估
%20拷贝-qwia.jpg)
3.1 流程与标准化实践
3.1.1 红队测试全流程
红队测试通过模拟真实攻击者的策略和技术,对AI系统、企业网络、内容平台等进行全方位攻防演练,检验安全防护能力,发现潜在漏洞。标准流程包括:
情报收集与分析:收集目标系统架构、服务、历史漏洞等信息。
渗透测试与漏洞挖掘:利用自动化工具和手工技巧,发现并利用系统漏洞。
攻防策略制定:红队尝试绕过防御,蓝队实时监控和响应。
实战演练与总结评估:分析攻防效果,提出改进建议。
3.1.2 自动化与人工结合
现代红队测试强调自动化与人工结合。自动化工具如PyRIT可生成大量攻击变体,覆盖模型训练、部署、迭代全周期;专家人工测试则针对复杂场景和新型攻击手段进行深度挖掘,确保测试的全面性和实战性。
3.1.3 威胁模型本体论
微软《2025年生成式AI红队百次测试经验白皮书》提出“威胁模型本体论”,涵盖系统漏洞、攻击者策略、影响评估等,为红队测试提供了系统化、标准化的理论基础。
3.2 典型案例与数据
3.2.1 微软Tay事件
微软Tay因缺乏足够防护,被提示注入攻击诱导生成不当内容,最终被迫下线,成为AI安全领域的经典案例,凸显红队测试的重要性。
3.2.2 多语言与多模态测试
红队测试发现,荷兰语仇恨言论漏报率高达42%,视频帧嵌入对抗样本使文本生成错误率提升60%。这些数据表明,AI系统在多语言、多模态场景下的安全防护仍有较大提升空间。
3.2.3 企业攻防演练
某金融AI助手在红队多轮对话攻击下,钓鱼成功率提升15%。通过红队测试,企业及时发现并修复了权限管理和日志审计等环节的薄弱点,显著提升了系统安全性。
3.3 红队测试价值与发展趋势
3.3.1 实战性与智能化
红队测试强调贴近真实攻击,涵盖社会工程、物理渗透、供应链攻击等多维手段。通过持续演练和动态防御,企业能够及时发现新型威胁,提升整体防护能力。
3.3.2 持续演练与动态防御
建议企业每月更新攻击样本库,结合自动化工具和专家测试,动态提升防护能力,保持系统的安全领先。
3.3.3 跨学科协作
红队测试不仅需要安全专家,还需融合伦理、心理等多领域专家,设计心理危机交互图谱等新型评估工具,提升测试的全面性和科学性。
3.3.4 合规与隐私保护
欧盟《AI法案》等法规要求高风险场景需通过红队认证,企业应建立五层防御模型,确保系统合规与用户隐私安全。
3.4 红队测试流程表
四、🌐 多维对抗与合规:AI安全防护的未来趋势
4.1 对抗样本与AI对AI攻防
4.1.1 对抗样本攻击
对抗样本通过对输入数据进行微小扰动,误导模型做出错误判断。攻击者可利用对抗样本绕过敏感词过滤和意图识别,提升攻击隐蔽性。为此,防护系统需引入对抗训练和历史攻击样本优化模型,增强模型的鲁棒性和自适应能力。
4.1.2 AI对AI攻防博弈
随着AI能力提升,攻防双方均可利用大模型生成海量攻击向量和防御策略,实现“AI对抗AI”的升维竞争。通过不断迭代的攻防博弈,检测模型能够更快适应新型攻击手段,提升整体安全水平。
4.2 动态防御与自适应免疫
4.2.1 自适应防御体系
现代AI安全防护体系强调“检测-响应-迭代”闭环。结合威胁情报平台与自动化对抗工具,系统能够实时检测新型威胁,自动响应并快速迭代防护策略,形成自适应免疫能力。
4.2.2 人机协同审核
AI与人工审核协同,能够在复杂场景下提升内容安全保障。AI负责高频、常规内容的自动审核,人工则聚焦于边界性、复杂性高的案例,二者互补,显著降低误判和漏判。
4.3 合规性与法律框架
4.3.1 法规要求
2023年《生成式人工智能服务管理暂行办法》、欧盟《AI法案》等法规明确禁止AI生成违法、淫秽、侵权内容,要求服务商建立敏感词过滤、举报机制和合规审计模块。企业需定期自查,确保系统符合最新法律法规要求。
4.3.2 典型判例
广州互联网法院AI著作权案、湖北大冶市AI色情小说案等判例,强调服务商需持续更新过滤机制,防止侵权和违法内容传播。合规不仅是法律底线,更是企业声誉和用户信任的保障。
4.4 多模态与区块链溯源
4.4.1 多模态安全防护
融合文本、图像、音频等多模态检测,能够提升对隐写、变体攻击的识别能力。多模态安全防护已成为应对复杂攻击手段的必然趋势。
4.4.2 区块链存证与溯源
利用区块链技术记录内容生成与审核过程,提升可追溯性和维权能力。区块链存证为内容安全提供了强有力的技术支撑,便于事后追责和合规审计。
4.5 现实挑战与技术局限
4.5.1 技术局限
敏感词过滤和意图识别仍有误判、漏判,尤其对隐喻式和多模态攻击识别有限。模型训练需持续优化,结合人工审核和用户反馈,提升系统的整体表现。
4.5.2 资源投入
红队测试需大量人力和时间,中小企业难以长期投入。自动化工具和云服务的普及,有望降低测试门槛,提升行业整体安全水平。
4.5.3 攻击手段进化
攻击方式不断升级,对防护技术提出更高要求。企业需保持技术敏感性,及时引入新技术和最佳实践,持续提升安全防护能力。
五、📊 典型案例与权威数据
%20拷贝.jpg)
5.1 行业典型案例
深圳行星网络科技AI专利:通过BERT与FastText模型融合,敏感词过滤误判率降低40%。
火山引擎防火墙:检出率99%,算力DDoS防御降低损失40%,数据泄露风险降低96%。
微软红队测试:荷兰语仇恨言论漏报率42%,客服LLM诱导70%用户泄露信息。
某教育机构:引入智能检测后,违规率下降78%,审核效率提升3倍。
某金融平台:封号事件减少90%,客户转化率提升25%。
5.2 权威数据汇总表
六、🧭 结论
提示词安全防护已从单一规则过滤转向多维度、动态、智能化的综合防御体系。通过敏感词过滤、意图识别、红队测试、对抗训练、多模态检测等多层次技术手段,结合法律法规、行业最佳实践和人机协同机制,能够有效对抗攻击检测与越权指令,保障内容合规与系统安全。未来,随着AI技术持续演进,安全防护体系将更加智能化、动态化和协同化,为数字社会的健康发展提供坚实保障。
📢💻 【省心锐评】
“真正的安全不是筑高墙,而是让防御比攻击进化得更快。未来的护城河,流淌的将是动态对抗的AI算力。”

评论