.png)


【摘要】斯坦福大学发布OpenTSLM模型,首次实现大型语言模型对时间序列数据的原生理解与推理。通过创新的多模态架构,AI能像医学专家一样,同步解读文本与波形数据,并在关键任务上超越GPT-4o。
引言
大型语言模型(LLM)在自然语言处理领域取得了巨大成功。它们能够理解、生成和推理复杂的文本信息。然而,现实世界的数据远不止文本。时间序列数据,如心电图(ECG)、脑电图(EEG)和工业传感器读数,构成了另一片广阔的数据海洋。这些数据以连续变化的数值序列形式存在,其内在模式和动态特征与离散的文本符号截然不同。
长期以来,LLM面对时间序列数据时显得力不从心。传统的解决方案通常采用间接方法。一种是将时间序列数据“翻译”成文本描述,再交由LLM处理。这种方式不可避免地会造成信息损失,如同看一幅画的文字描述而非亲眼所见。另一种是训练专门的时间序列模型,但这些模型通常是判别式的分类器或预测器,缺乏LLM强大的生成和解释能力。它们能回答“是什么”,却无法解释“为什么”。
医学诊断、金融分析和工业监控等关键领域,恰恰需要结合两种数据模态进行综合推理。医生不能只看病历文字,也必须解读心电图波形。交易员不能只读新闻,也必须分析价格走势图。这种跨模态的推理能力,是当前AI技术栈中的一块关键短板。
斯坦福大学与苏黎世联邦理工学院联合发布的OpenTSLM(Open Time Series Language Models)系列模型,正是为了填补这一空白。这项工作不再将时间序列视为需要转换的“外来语”,而是将其作为一种新的原生“语言”融入LLM的认知体系。它标志着AI正从单一的文本处理器,向能够理解多维、多模态世界的智能伙伴演进。
📌 一、OpenTSLM 技术解构:多模态融合的新范式
%20拷贝.jpg)
OpenTSLM的核心贡献在于设计了一套能让LLM直接“阅读”时间序列数据的架构。这需要首先解决文本与时间序列之间存在的根本性差异,即模态鸿沟。
1.1 核心挑战:时间序列与文本的模态鸿沟
文本数据和时间序列数据在底层结构、信息编码和分析范式上存在本质区别。强行将两者统一处理,而不考虑其内在特性,是过去方案失败的主要原因。
表1:文本数据与时间序列数据的核心差异
正是这些差异,导致了LLM无法直接应用其强大的注意力机制来处理时间序列。OpenTSLM通过两种不同的架构设计,为跨越这一鸿沟提供了可行的工程路径。
1.2 架构设计:两种路径的权衡与抉择
研究团队提出了两种并行的架构方案,OpenTSLM-SoftPrompt和OpenTSLM-Flamingo。它们代表了两种不同的多模态融合哲学,各有优劣。
1.2.1 OpenTSLM-SoftPrompt 架构解析
SoftPrompt,或称为提示调优(Prompt Tuning),是一种参数高效的微调技术。它冻结LLM主体的全部参数,仅在输入层为特定任务学习一组可训练的、连续的向量,即“软提示”。
在OpenTSLM中,这个思路被巧妙地借用。
时间序列编码。首先,一个独立的时间序列编码器(例如,基于卷积或Transformer的模块)负责将输入的原始时间序列数据(如一段ECG信号)压缩成一组固定长度的特征向量。
特征向量映射。这些特征向量随后被视为“软提示”,在概念上等同于文本输入中的词嵌入(Word Embeddings)。它们被插入到原始文本提示的嵌入序列中。
统一处理。拼接后的序列(包含文本嵌入和时间序列软提示)被送入一个标准的、预训练好的LLM中进行处理。LLM的自注意力机制会同时关注文本标记和代表时间序列的软提示,从而实现跨模态的信息交互。
其数据流可以用下面的流程图表示。
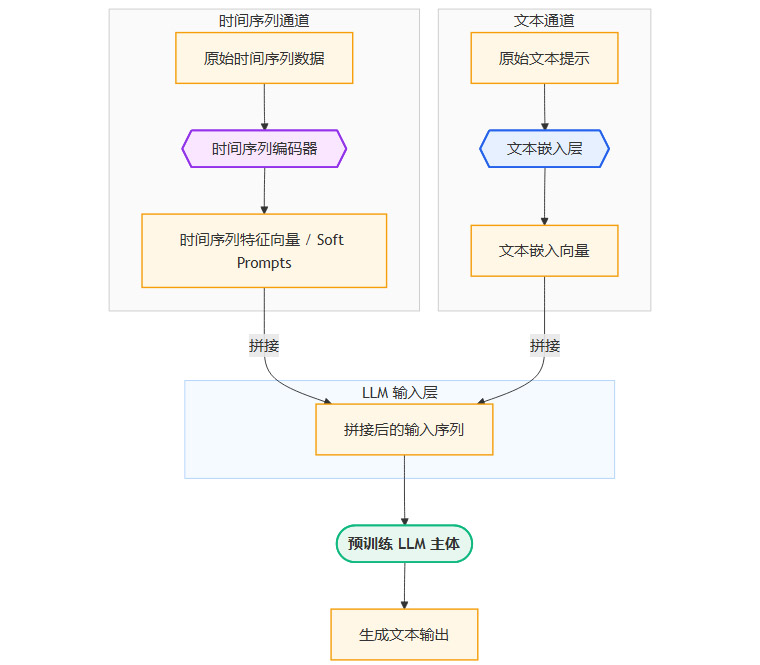
优点:
实现简单。该方案对现有LLM的架构改动最小,只需在外部添加一个编码器和拼接逻辑。
参数高效。训练过程中仅更新时间序列编码器和少量映射层参数,LLM主体保持冻结,极大降低了训练成本。
缺点:
内存瓶颈。这是该架构的致命缺陷。LLM的注意力机制计算复杂度与输入序列长度的平方成正比(O(n²))。时间序列数据通常很长,编码后会产生大量的软提示向量。当处理一段10秒的心电图数据时,生成的软提示数量巨大,导致整个输入序列长度急剧膨胀,最终使得内存占用变得无法承受。实验表明,处理该任务需要约110GB的显存,这超出了绝大多数商用GPU的容量。
1.2.2 OpenTSLM-Flamingo 架构解析
Flamingo模型最初是为处理图像和文本而设计的。其核心思想是解耦不同模态的编码过程,通过交叉注意力机制(Cross-Attention)进行高效的信息融合。OpenTSLM借鉴并改造了这一思想,用于处理时间序列和文本。
双路独立编码。文本数据和时间序列数据分别由各自独立的模块处理。文本由预训练LLM的语言模型部分处理,时间序列由一个专门的视觉编码器(Perceiver Resampler)和时间序列编码器处理。
交叉注意力桥梁。在LLM的每一层(或特定几层)中,插入一个额外的交叉注意力模块。当LLM在生成文本时,这个模块会“暂停”一下,将当前的文本表示作为查询(Query),去时间序列编码器输出的特征中“检索”(Key-Value)相关信息。
信息融合与生成。交叉注意力模块的输出被整合回LLM的主干通路,影响后续的文本生成。这样,LLM在生成每个词时,都能动态地参考时间序列数据中的相关部分。
其数据流可以看作一个更复杂的交互过程。
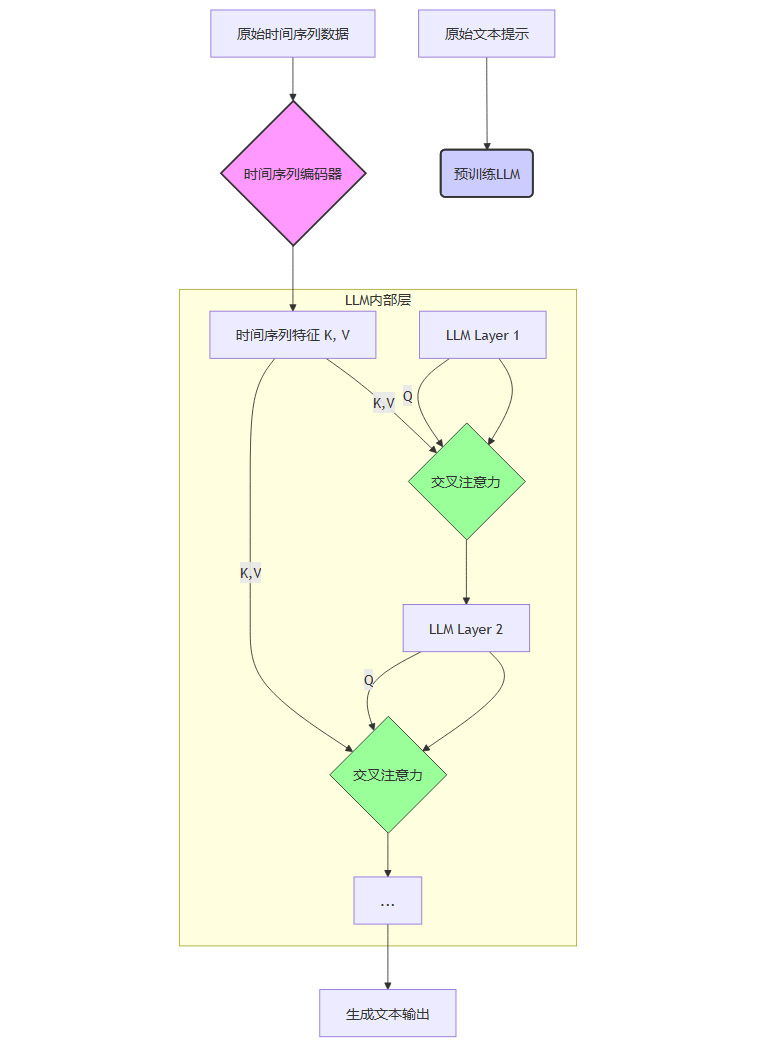
优点:
内存高效。LLM处理的文本序列长度保持不变。时间序列数据作为外部的Key-Value对存在,不直接增加LLM自注意力的计算负担。这使得内存占用与时间序列的长度基本解耦。处理同样10秒的心电图数据,Flamingo架构仅需40GB显存。
可扩展性强。由于内存占用相对稳定,该架构能够轻松处理更长的时间序列数据,这在处理连续生理监测等真实场景中至关重要。
缺点:
实现复杂。需要在LLM内部插入新的模块,对模型架构的修改更深入。
训练可能更不稳定。引入新的注意力机制需要精心的训练策略来保证收敛。
1.3 架构对比总结
两种架构的选择,本质上是在实现简易性与系统可扩展性之间的权衡。
表2:OpenTSLM-SoftPrompt vs. OpenTSLM-Flamingo 架构对比
实验结果表明,尽管两种架构在短序列任务上的性能不相上下,但Flamingo架构凭借其出色的内存效率和可扩展性,无疑是更具实用价值和未来潜力的技术路线。
📌 二、训练策略与数据集构建:从数据生成到推理对齐
一个强大的模型架构需要高质量的训练数据才能发挥作用。在多模态推理任务中,数据不仅要包含原始信号和最终标签,更需要包含从信号到结论的中间推理过程。这是建立模型可解释性和可信度的关键。
2.1 面向推理的合成数据生成
研究团队面临一个难题,现实世界中几乎不存在带有详细推理链(Chain-of-Thought, CoT)的时间序列数据集。为了解决这个问题,他们创造性地采用了一种“教师-学生”模式。
教师模型。选用强大的多模态模型GPT-4o作为数据标注的“教师”。
学生模型。OpenTSLM作为需要学习的学生。
教学材料。将时间序列数据以图像形式呈现给GPT-4o,并设计精巧的提示(Prompt),引导它生成包含观察、分析、推理和结论的详细文本。
这种方法本质上是一种知识蒸馏,将GPT-4o的通用多模态推理能力,提炼并注入到更小、更专业的OpenTSLM模型中。
2.2 三大任务数据集详解
为了验证模型的通用性,团队构建了覆盖三个不同领域的任务数据集。
2.2.1 人体活动识别 (Human Activity Recognition)
数据来源。公开的WISDM数据集,包含来自智能手机和可穿戴设备的加速度计数据。
任务目标。根据一小段加速度计信号,识别用户正在进行的活动(如走路、跑步、上楼梯等)。
推理生成。GPT-4o被要求分析信号的波形特征。例如,它会生成这样的推理:“信号显示出周期性、高幅度的冲击,这与跑步时脚跟着地的特征一致。信号的整体能量水平较高,排除了走路或站立的可能性。”
2.2.2 睡眠分期 (Sleep Staging)
数据来源。知名的Sleep-EDF数据库,包含整夜的脑电图(EEG)记录。
任务目标。根据30秒的EEG片段,将其分类为五个睡眠阶段之一(清醒、REM、N1、N2、N3)。
推理生成。这是一个高度专业的医学任务。GPT-4o被训练来识别不同睡眠阶段的标志性脑电波。例如:“该片段显示了低幅度的混合频率波,并出现了K复合波和睡眠纺锤波。这些是N2期睡眠的典型特征。”
2.2.3 心电图问答 (ECG Question Answering)
数据来源。基于ECG-QA数据库,包含12导联心电图和相关的临床问题。
任务目标。这是最复杂的任务,要求模型像心脏病专家一样解读心电图并回答具体问题。
推理生成。采用对比学习策略。模型面对一个问题和两个选项(A和B),必须选择正确的答案并解释原因。例如,问题是“该心电图是否存在ST段抬高?”,GPT-4o会生成:“分析12个导联后,在V2、V3、V4导联中观察到ST段明显高于基线超过2mm。这符合急性前壁心肌梗死的诊断标准。因此,选项A‘存在’是正确的。”
2.3 质量控制与专家验证
合成数据的质量直接决定了模型的上限。研究团队实施了严格的质控流程。
人工抽样审查。研究人员手动检查了大量GPT-4o生成的推理样本,确保其逻辑连贯、语言流畅。
专家评估。对于专业性极强的心电图数据集,团队邀请了五位斯坦福医院的心脏病专家进行盲审。评估结果显示,AI生成的推理在92.9%的情况下被认为是正确或部分正确的。
这个验证过程至关重要。它不仅证实了数据生成策略的有效性,也为模型在医疗等高风险领域的应用提供了初步的信任基础。通过这种方式,OpenTSLM不仅学会了“看图说话”,更学会了像专家一样“思考”。
📌 三、性能评测与深度分析:小模型何以超越巨无霸
%20拷贝.jpg)
实验结果是检验模型能力的最终标准。OpenTSLM的评测结果不仅展示了其卓越的性能,更揭示了一些关于模型设计与规模的深刻洞见。
3.1 跨任务性能对比
研究团队将OpenTSLM与两类基线模型进行了对比。
微调文本模型。将时间序列数据转换为文本后,使用Llama-2等纯文本LLM进行微调。
通用多模态模型。直接使用强大的GPT-4o进行零样本或少样本推理。
表3:关键任务性能对比 (F1分数)
结果分析:
碾压式优势。OpenTSLM在所有任务上都显著优于传统方法。微调文本模型几乎完全失效,证明了将时间序列粗暴文本化的方案行不通。
专业胜于通用。最令人震惊的是,参数量仅为10亿(1B)的OpenTSLM,在这些专业任务上的表现远超参数量超过2000亿(200B)的GPT-4o。这有力地证明了专用架构设计的重要性。通用大模型虽强,但在没有针对性优化的领域,其能力无法有效发挥。
3.2 架构效率分析:内存与可扩展性
性能不仅指准确率,还包括运行效率。这直接决定了模型能否在实际环境中部署。
内存占用对比。如前所述,在处理12导联心电图数据时,SoftPrompt架构需要110GB显存,而Flamingo架构仅需40GB。
可扩展性趋势。更关键的是两者随序列长度变化的趋势。
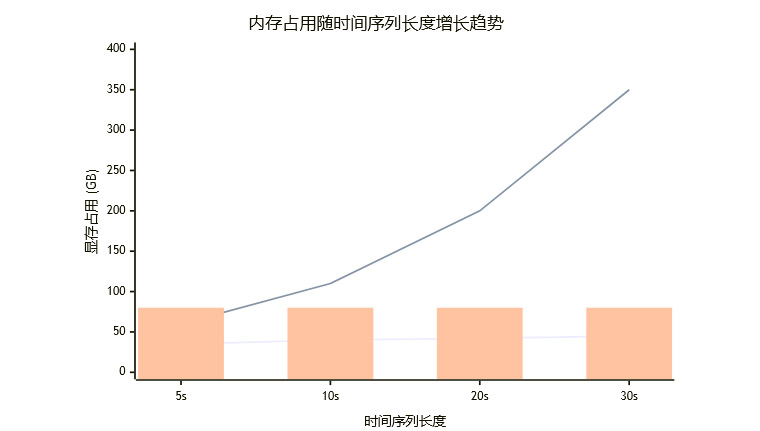
(注:上图为趋势示意图,非精确实验数据)
上图清晰地展示了SoftPrompt架构的局限性。其内存需求呈指数级增长,很快就会触及硬件天花板。而Flamingo架构的内存增长则非常平缓,展现了处理真实世界长序列数据的巨大潜力。对于需要连续监测数小时甚至数天的医疗应用,Flamingo是唯一可行的选择。
3.3 涌现能力:小模型的逆袭之道
“小模型超越大模型”的结果并非偶然,它揭示了一个核心原则:架构与数据的对齐(Architecture-Data Alignment)远比单纯的参数堆砌更重要。
GPT-4o是一个通才,其庞大的参数中存储了关于整个世界的知识。但它的架构并未针对时间序列的连续、动态特性进行优化。当面对心电图时,它只能将其当作一幅普通的“图像”来理解,无法深入其内在的电生理学意义。
OpenTSLM则是一个专才。它的架构(特别是时间序列编码器和交叉注意力机制)是为理解时间序列的“语法”而生的。通过在包含推理链的数据集上进行训练,它学会了将这些“语法”与医学或物理世界的“语义”联系起来。
这个结果给AI领域的发展带来重要启示。在追求更大、更通用的模型的同时,为特定领域设计小而精、小而美的专用模型,可能是一条更高效、更具成本效益的技术路径。
📌 四、应用前景与技术挑战
%20拷贝.jpg)
OpenTSLM的成功为AI在多个领域的深度应用打开了新的大门,但从实验室走向现实世界,仍有诸多挑战需要克服。
4.1 潜在应用场景剖析
医疗健康。
智能诊断辅助。整合病历文本、生命体征监测(ECG、血压)和影像报告,为医生提供带有详细推理过程的诊断建议。
慢性病管理。为糖尿病、心脏病患者提供7x24小时的智能健康顾问,解读血糖、心率数据,并结合用户日志提供个性化干预建议。
远程医疗。赋能基层医生,使其能够借助AI分析复杂的生理信号,提升偏远地区的医疗服务水平。
金融科技。
量化交易。结合市场行情(K线、交易量)和财经新闻、社交媒体情绪,生成更具解释性的交易策略。
智能投顾。为个人投资者分析其投资组合表现,并结合宏观经济报告解释市场波动原因。
工业物联网 (IIoT)。
预测性维护。分析设备的传感器振动、温度数据,并关联操作员的维修日志,不仅预测故障,还能推荐具体的维修步骤。
生产流程优化。监控整个生产线的实时数据流和工单文本,识别效率瓶颈并给出优化建议。
体育科学。
运动员监控。整合运动员的心率变异性(HRV)、GPS轨迹和教练的训练笔记,评估训练负荷,预警伤病风险。
4.2 面临的挑战与未来方向
数据隐私与安全。医疗和金融数据极其敏感。如何在保证数据不出域、不泄露的前提下进行模型训练和推理,是部署应用的首要障碍。联邦学习、可信执行环境(TEE)等技术是潜在的解决方案。
监管与合规。医疗AI产品需要通过严格的NMPA/FDA认证。模型的决策过程需要满足监管机构对透明度、公平性和可靠性的要求。OpenTSLM的可解释性是一个优势,但仍需标准化和量化。
模型的鲁棒性与泛化能力。模型在处理来自不同设备、不同人群的数据时,性能是否会下降?如何应对数据中的噪声和伪影?这是从干净的实验数据走向混乱的真实世界的关键一步。
部署成本与效率。尽管Flamingo架构效率更高,但40GB的显存需求对于边缘设备或普通服务器而言依然是巨大的挑战。模型量化、蒸馏和剪枝等技术,是降低部署门槛的必经之路。
多模态融合的深化。目前OpenTSLM融合了文本和时间序列。未来的系统需要融合更多模态,如医学影像(X光、CT)、基因序列等,构建一个真正全面的AI诊断大脑。
结论
OpenTSLM的出现,是多模态AI发展历程中的一个重要节点。它首次证明了大型语言模型有能力以一种深刻、原生的方式理解时间序列数据,而不仅仅是将其作为一种附属信息。通过精巧的架构设计和创新的数据生成策略,研究者们成功地让一个相对较小的模型,在专业领域战胜了体量庞大的通用模型。
这项工作最重要的意义,在于它推动了AI角色的转变。AI不再仅仅是一个个功能单一的工具(文本处理器、图像分类器),而是开始进化为一个能够整合、分析、推理多源异构信息,并以自然语言与人类协作的智能伙伴。从医疗诊断到工业控制,这种人机协作的新范式,将对众多行业产生深远影响。尽管前路仍有挑战,但通往更智能、更可信AI系统的大门,已经打开。
📢💻 【省心锐评】
OpenTSLM的核心价值不在于“战胜GPT-4o”,而在于证明了“架构-数据对齐”比盲目堆砌参数更有效。它为垂直领域构建小而精的多模态AI模型,提供了一条清晰、高效的技术路径。

评论