.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】本文深度剖析大语言模型排行榜的评测逻辑、数据来源、商业博弈与用户选择策略,结合主流榜单与行业现象,帮助读者理性理解排行榜背后的权威性与局限性,科学选择最适合自身需求的AI模型。
引言
人工智能的浪潮席卷全球,尤其是大语言模型(LLM)的迭代与竞赛,已成为科技行业最受瞩目的焦点之一。每一次新模型的发布、每一次榜单的刷新,都牵动着无数开发者、企业决策者和普通用户的神经。社交媒体和技术论坛上,关于“XX模型刷新多项基准测试记录”或“国产模型登顶中文评测榜首”的讨论层出不穷。这些热议背后,既有技术突破的欣喜,也有对评测标准、榜单权威性和商业逻辑的深刻疑问。
AI模型的“登顶”究竟意味着什么?排行榜的权威性和公正性如何保障?为何同一模型在不同榜单上的排名差异巨大?这些问题不仅困扰着普通用户,也成为行业专家和研究者反复探讨的核心议题。理解排行榜背后的“游戏规则”,不仅是洞察AI领域竞争格局的关键,更是每一位AI从业者和用户做出理性选择的前提。
本文将以详实的数据,系统梳理大语言模型排行榜的评测方法、主流数据、商业逻辑与用户选择策略,帮助读者在纷繁复杂的榜单中,找到属于自己的“私人冠军”。
一、📊 排行榜类型与评测逻辑
%20拷贝.jpg)
1.1 客观基准测试:AI的“高考”与硬实力较量
1.1.1 评测原理与代表性指标
客观基准测试是当前大语言模型评估体系的基石。其核心思想是通过一系列标准化、可复现的题目,量化模型在知识推理、数学、编程等领域的能力。这种方法类似于人类的高考,强调“硬实力”的横向对比。
常见的客观基准测试包括:
AAII指数(Artificial Analysis Intelligence Index):综合多项能力单项评测结果,覆盖知识推理、数学、编程等领域,成为衡量AI模型智能水平的重要指标(数据来源:Artificial Analysis Intelligence Index, 2025)。
MMLU-Pro:聚焦多领域、多学科的专业知识广度与深度推理能力。
GPQA Diamond、Humanity's Last Exam:分别考察模型的跨学科问题解决能力与人类知识极限。
LiveCodeBench、SciCode:关注模型的编程鲁棒性、边界处理能力及科学原理理解。
AIME、MATH-500:衡量高级数学推理与解题能力。
1.1.2 优势与局限
优势:
高效、可复现,便于不同模型间的横向对比。
能量化模型在各领域的能力,适合大规模评测与排名。
局限:
易受数据污染影响,部分模型可能通过“刷分”优化特定测试集表现,实际应用未必理想。
难以评估创造力、情感、幽默等“软实力”。
某些测试题目与真实应用场景存在脱节。
1.1.3 典型榜单与数据示例
下表为2025年主流AAII指数排行榜前十名(数据来源:Artificial Analysis Intelligence Index, 2025):
1.2 人类偏好竞技场:用户体验的真实投票
1.2.1 评测原理与代表性平台
与客观基准测试不同,人类偏好竞技场强调“软实力”与用户体验。其核心机制是通过众包平台,让真实用户对模型的回答进行匿名对比和投票,采用Elo评分系统动态排名,反映模型在实际应用中的表现。
LMSys Chatbot Arena:目前累计投票数已超千万,成为业界公认的用户偏好评测金标准(数据来源:Chatbot Arena, 2025)。
用户在平台上对比两个模型的回答,选择更符合自己需求的答案,最终形成排行榜。
1.2.2 优势与局限
优势:
贴近实际应用,难以作弊,能反映用户真实需求和体验。
能捕捉模型在创造力、表达力、情感等方面的表现。
局限:
多为单轮对话,难以覆盖复杂多轮任务。
主观性强,投票者群体有限,难以保证绝对公正。
用户评判时更关注答案表述,可能忽视内容真实性。
1.2.3 典型榜单与数据示例
下表为2025年Chatbot Arena排行榜前十名(数据来源:Chatbot Arena, 2025):
1.3 榜单差异的根源与融合视角
1.3.1 评测方法、数据集与权重分配
不同榜单在评测方法、数据集选择、权重分配等方面存在显著差异。例如,AAII指数更侧重知识推理与数学能力,而Chatbot Arena则更关注用户体验和表达能力。这导致同一模型在不同榜单上的排名可能出现较大差异。
1.3.2 榜单的互补性
AAII等基准测试代表“模型能做什么”,Chatbot Arena等偏好竞技场代表“用户更喜欢谁”。两者互为补充,反映了模型的不同侧面。理性用户应结合多种榜单和实际体验,综合评估模型的综合实力与适用性。
二、💡 主流排行榜数据与模型表现
2.1 基准测试排行榜:硬实力的较量
2.1.1 榜单解读与趋势
从AAII指数等基准测试榜单来看,OpenAI、Google、Anthropic等国际巨头依然占据主导地位。GPT-4、Gemini 1.5 Pro、Claude 3 Opus等模型在知识推理、数学、编程等领域表现突出。与此同时,国产模型如Qwen-2、Yi-34B、Mixtral 8x22B等在中文场景和开源生态中展现出强劲的追赶势头。
2.1.2 细分领域表现
知识推理:GPT-4、Claude 3 Opus在MMLU-Pro、GPQA Diamond等测试中表现优异,展现出深厚的专业知识储备与推理能力。
编程能力:Claude 3系列、Gemini 1.5 Pro在LiveCodeBench、SciCode等编程测试中得分领先,适合开发者和技术团队使用。
数学推理:AIME、MATH-500等测试中,GPT-4、Gemini 1.5 Pro、Qwen-2等模型展现出强大的数学解题能力。
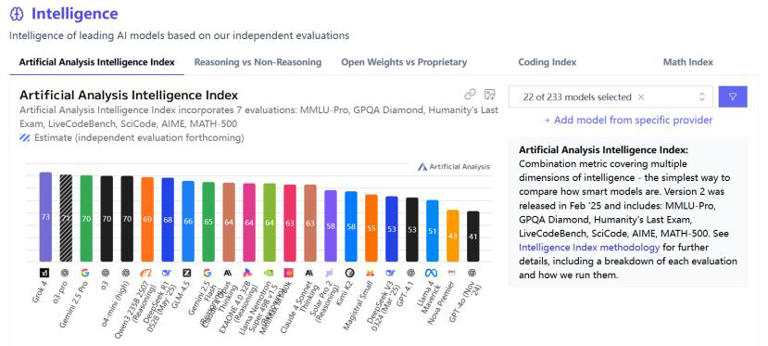
2.2 人类偏好竞技场:用户体验的真实反馈
2.2.1 榜单解读与趋势
Chatbot Arena等人类偏好竞技场榜单显示,Google的gemini-2.5-pro、OpenAI的o3-2025-04-16、chatgpt-4o-latest-20250326等模型在用户体验和表达能力方面获得高度认可。xAI的grok系列、Anthropic的claude-opus-4等新兴模型也在部分场景下表现突出,获得大量用户投票支持。
2.2.2 用户投票与Elo评分机制
Chatbot Arena采用Elo评分系统,动态反映模型在用户对比投票中的胜率。累计投票数已超千万,成为业界公认的用户偏好评测金标准(数据来源:Chatbot Arena, 2025)。
2.2.3 榜单数据可视化
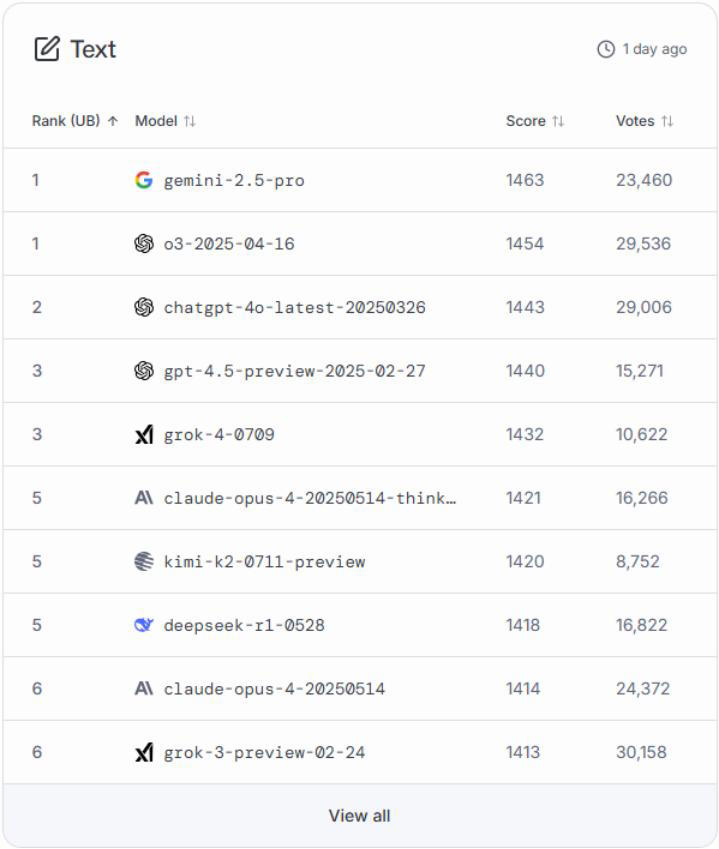
2.3 榜单差异的现实意义
2.3.1 不同榜单的排名差异
由于评测方法、数据集、权重分配等差异,同一模型在不同榜单上的排名可能存在显著差异。例如,国产模型如Yi-Large、Qwen、DeepSeek R1等在中文场景和开源生态中表现突出,部分榜单甚至与GPT-4o并列第一(数据来源:AIbase模型广场, 2025)。
2.3.2 榜单的参考价值
榜单本身并非绝对权威,更多是为用户提供参考。理性用户应结合自身需求、实际应用场景和多维度数据,科学选择最适合自己的AI模型。
三、💼 排行榜背后的商业逻辑
%20拷贝.jpg)
3.1 厂商策略与产品定位
3.1.1 技术优势与市场定位
各大厂商(OpenAI、Google、Anthropic、阿里云等)会根据自身技术优势和市场定位,优化模型在特定评测中的表现。例如,OpenAI强调多模态和推理能力,Google突出超长上下文和多模态处理,Anthropic在代码和学术写作领域表现优异。
3.1.2 垂直领域深耕
部分厂商专注于特定行业场景,如百度文心一言4.0在医疗、金融等领域进行深度优化,提升模型在垂直领域的应用价值。
3.2 开源与闭源的博弈
3.2.1 开源模型的崛起
开源模型(如Llama、Qwen、DeepSeek等)凭借低成本和可定制性,受到开发者和企业青睐。开源生态的繁荣推动了AI技术的普及与创新。
3.2.2 闭源模型的优势
闭源模型在性能、服务、安全性等方面更具优势,适合对数据安全和服务质量有高要求的商业用户。厂商通过闭源策略,保障核心技术和商业利益。
3.3 成本效率与行业竞争
3.3.1 训练成本与性能优化
部分厂商通过优化训练流程和硬件资源,显著降低模型训练成本。例如,DeepSeek R1的训练成本仅为GPT-4o的1/70(数据来源:DeepSeek官方报告, 2025),为行业带来更高的性价比选择。
3.3.2 榜单“刷分”与宣传效应
厂商有时会针对特定测试集优化模型表现,形成“刷榜”现象。用户需警惕榜单背后的商业宣传,避免被表面数据误导。
四、🧭 用户理性选择建议
4.1 明确自身需求场景
4.1.1 不同用户的关注重点
程序员:关注模型的代码编写和修复能力(如Claude 3.7编程得分91.2,数据来源:Anthropic官方, 2025)。
学生/科研人员:重视文献处理和学术能力(如Kimi支持超长上下文,数据来源:Moonshot AI, 2025)。
营销/创作人员:看重文案生成和创意表达(如文心一言4.0中文表达得分高,数据来源:百度官方, 2025)。
企业用户:需综合考虑成本、稳定性、API接入便利性和数据安全等。
4.2 多维度对比与实际测试
4.2.1 利用专业对比平台
用户可利用AIbase模型广场等专业平台,进行多维度筛选和对比,结合实际场景做A/B测试,找到最适合自身需求的模型。
4.2.2 关注模型更新与社区活跃度
模型的更新频率、社区活跃度和技术支持水平,直接影响其长期可用性和生态价值。用户应关注厂商的持续投入和社区反馈。
4.2.3 权衡开源与闭源模型
结合自身预算和技术能力,权衡开源模型的可定制性与闭源模型的性能和服务优势,做出最优选择。
4.3 警惕榜单局限与“刷榜”陷阱
4.3.1 榜单仅供参考
榜单本身并非绝对权威,实际应用效果才是关键。建议用户将实际任务输入不同模型测试,谁能高效解决问题,谁就是你的“私人冠军”。
五、🌐 榜单现象的行业影响与未来展望
%20拷贝.jpg)
5.1 榜单推动技术进步与行业创新
排行榜的存在,激励厂商不断优化模型性能,推动AI技术的持续进步。榜单数据为行业提供了客观参考,促进了技术交流与创新合作。
5.2 榜单的多元化与国际化趋势
随着AI技术的全球化发展,榜单的多元化与国际化趋势愈发明显。不同地区、不同语言、不同应用场景下的榜单,为用户提供了更丰富的选择空间。
5.3 榜单与用户需求的动态互动
榜单不仅反映了技术实力,也反映了用户需求的变化。用户的反馈和选择,反过来影响厂商的产品策略和技术研发方向,形成良性循环。
结论
大语言模型排行榜是技术进步、商业策略和用户需求多重作用的产物。排行榜本身并非绝对权威,用户应以实际需求为导向,结合多维度数据和真实体验,科学选择最适合自己的AI模型。大模型是工具而非神祇,真正的“冠军”是能在你的场景下最高效解决问题的那一个。理性看待排行榜,善用榜单数据,才能在AI时代的浪潮中立于不败之地。
📢💻 【省心锐评】
“排行榜是厂商的竞技场,用户的参考系。选型如择器,称手即良品——脱离场景的排名都是海市蜃楼。”

评论