.png)
%20%E6%8B%B7%E8%B4%9D-eurt.jpg)

【摘要】系统阐述AlphaOS数据底座的设计蓝图。它聚焦于点时一致的数据源规范与工业级数据中台处理流程,为构建可信赖、高性能的智能量化投研平台提供坚实的数据基石。
引言
在量化投资的世界里,算法与模型固然是利剑,但数据才是铸剑的玄铁。任何精妙的策略,一旦建立在质量可疑、逻辑混乱的数据之上,都无异于沙上建塔。业界普遍面临的挑战,如回测与实盘的巨大鸿沟、策略的快速衰减,其根源往往可以追溯到数据治理的缺失。一个策略的Alpha,其上限早已由其所消费的数据质量所决定。
因此,构建一个现代化的智能投研平台,首要任务并非追逐最新的AI模型,而是回归本源,打造一个工业级的、可信赖的数据底座。本白皮书将详细解构AlphaOS的数据底座设计。我们不谈论空泛的概念,而是深入到数据源的验收规范、数据中台的分层处理、点时一致性的实现细节以及面向智能体的服务契约中去。这不仅是一份技术蓝图,更是一套旨在从源头确保Alpha质量的工程哲学。
一、📜 数据契约:定义机构级量化投资的数据源规范
%20拷贝-dgsm.jpg)
数据接入是所有工作的起点。我们必须像签订一份法律合同一样,与数据建立一套严格的“契约”,明确其范围、质量标准和治理原则。这份契约是保证上游“水源”纯净的第一道防线。
1.1 数据矩阵:全景式的覆盖范围
一个机构级的平台需要一个立体、多维的数据矩阵,以支撑从宏观配置到微观择时的各类策略。
1.2 治理基石:不可妥协的四大原则
这四大原则是数据契约的基石,任何数据的接入与处理都必须无条件遵守。
1.2.1 点时一致性 (Point-in-Time Consistency)
这是数据治理的灵魂。量化研究的本质是复现历史,而复现的前提是在历史的任何一个时间点,我们只能看到当时已经发生且可以被市场观测到的信息。为了实现这一点,系统必须采用双时间戳模型。
事件时间 (Event Time)。数据所描述的业务事件实际发生的时间。例如,一份财报的“报告期截止日”。
可见时间 (Visible Time)。该数据在市场上首次可被获取的时间。例如,财报的“公告发布时间”。
所有的数据查询和回测,都必须基于“可见时间”进行切片,从而从根本上杜绝前视偏差(Look-ahead Bias)。
1.2.2 生存偏差控制 (Survivorship Bias Control)
一个常见的错误是研究样本只包含当前存活的标的。这会导致策略表现被严重高估。数据底座必须完整保留所有历史标的的信息,包括那些已经退市、被并购、重组或更名的公司。同样,指数成分股也必须进行历史版本化管理,确保在任何历史时点都能获取到当时真实的成分列表和权重。
1.2.3 公司行为一致性 (Corporate Action Consistency)
分红、送转、配股等公司行为会改变证券的价格和数量。如果处理不当,会产生虚假的收益或亏损。数据底座必须建立一个统一、标准化的公司行为处理引擎。该引擎负责生成精准的前复权因子和后复权因子,并提供详细的对账规则,确保所有历史价格序列的可比性。
1.2.4 数据合规与可追溯性 (Compliance & Traceability)
尤其对于成本高昂的另类数据,合规是生命线。系统必须为每一条数据记录其合法来源、授权使用范围、地理限制和有效期限。同时,每一次数据访问都应被记录审计,形成完整的数据血缘图谱 (Data Lineage),确保整个投研流程全程可追溯、可审计。
二、⚙️ 数据精炼厂:AlphaOS数据中台的架构与处理蓝图
如果说数据源是“原油”,那么数据中台就是一座精密的“炼油厂”。它的任务是将驳杂的原始数据,通过一系列标准化的流程,加工成可供上层智能体和策略直接使用的高质量“成品油”——即因子和特征。
2.1 分层治理架构:从原始到可用的净化之路
数据中台采用严格的分层架构,每一层都有明确的职责,确保数据在流动过程中逐步被净化和增值。
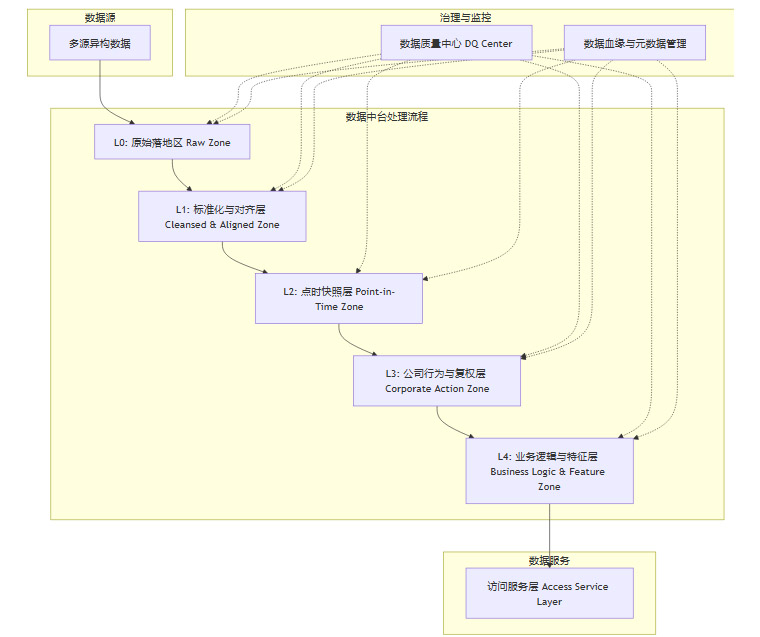
L0 - 原始落地区 (Raw Zone)。此层是数据的“保险库”。所有外部数据以其最原始的形态、原封不动地存储于此。它不做任何处理,仅用于数据审计和灾难恢复。
L1 - 标准化与对齐层 (Cleansed & Aligned Zone)。此层是数据的“清洗车间”。在这里,我们会进行格式统一、时区转换、币种和单位标准化、实体ID映射(如将不同数据源的公司ID统一映射到内部主数据ID)等基础工作。
L2 - 点时快照层 (Point-in-Time Zone)。这是数据中台技术含量最高的核心。基于双时间戳模型,此层将L1的流式数据转换为一系列不可变的历史快照。任何对历史数据的修改,都会生成一个新的版本,而非覆盖旧版本。
L3 - 公司行为与复权层 (Corporate Action Zone)。此层是“财务工程部”。它消费L2的PIT数据和公司行为事件表,运行复权引擎,生成精准的前后复权价格序列和复权因子。
L4 - 业务逻辑与特征层 (Business Logic & Feature Zone)。此层是“特征工厂”。研究员和数据科学家在此定义和计算衍生指标,如财务比率(PE-TTM)、技术指标(MACD)以及更复杂的Alpha因子。计算结果将写入下一节要详述的因子中间库。
2.2 核心能力模块:支撑自动化生产线的关键组件
2.2.1 数据采集与编排引擎
负责自动化、高可靠地从多源接入数据。它支持批处理和流处理一体化,具备断点续传、失败重试、数据回补和幂等写入等工业级特性,确保数据注入的稳定性和完整性。
2.2.2 数据质量中心 (DQC)
这是平台的“质检部门”。研究员可以定义数据质量规则(如某字段非空、取值范围、环比波动阈值)。DQC会自动执行这些规则,对不合格数据进行隔离、打标,并触发告警,形成一个主动式的质量监控闭环。
2.2.3 因子中间库 (Feature Store)
这是连接数据工程与策略研究的核心枢纽,是上层应用的主要数据消费入口。
统一资产管理。将因子(特征)作为一等公民进行管理。每个因子都有明确的定义、版本号、负责人和计算逻辑。这避免了不同研究员重复造轮子或使用不同口径的因子。
四维索引结构。所有因子数据采用
[实体, 时间, 特征, 版本]四维索引,能够高效支持横截面分析(特定时间点所有实体的某个特征)和时间序列分析(特定实体某个特征的历史序列)。线上线下一致性。Feature Store提供统一的API,确保策略在回测(线下)和实盘(线上)环境中获取到的因子数据是完全一致的,这是解决回测与实盘脱节问题的关键。
性能优化。内置热、温、冷数据分层存储和缓存机制,为高频访问场景提供毫秒级的查询性能。
三、🔌 服务契约:面向智能体与应用的数据消费接口
%20拷贝-adnt.jpg)
数据处理得再好,如果消费不便,价值也无法体现。数据底座必须提供一套清晰、高效、安全的服务契约。
3.1 面向AI与智能体的接口
数据代理智能体 (Data Agent)。这是一个专门的智能体,作为所有其他AI智能体访问数据的唯一网关。它封装了复杂的查询逻辑,并强制执行权限和合规检查。其他智能体只需用自然语言或结构化查询(如“获取A公司过去三年的PIT市盈率序列”)提出需求,由Data Agent负责完成。
文档证据链服务。对于基于文本分析的决策,系统提供证据链定位服务。例如,当一个舆情智能体发出预警时,可以一键追溯到引发预警的原始公告或新闻的PDF文件及具体段落。
3.2 面向回测与优化的接口
快照选择器 (Snapshot Selector)。回测任务必须明确声明其所使用的数据版本锁。回测引擎通过快照选择器,可以精确地“穿越”回历史上的任何一个时间点,获取当时全市场所有数据的完整、一致的快照。
回测一致性校验。平台提供工具,自动比对回测日志中的数据使用情况与生产环境的参数,确保回测环境的“洁净”。
3.3 面向看板与报表的接口
提供标准化的API,用于驱动各类监控和报告应用。
数据质量面板。实时展示各数据源的完整性、延迟、异常率等关键质量指标。
SLA看板。监控数据服务的查询延迟、可用性等性能指标。
公司行为对账报告。定期生成报告,供风控和运营人员核对公司行为处理的准确性。
四、🛡️ 治理与韧性:数据质量、SLA与风险管理
%20拷贝-ntzf.jpg)
一个工业级的系统,不仅要跑得快,更要跑得稳。
4.1 可量化的治理指标
数据治理不能停留在口号上,必须通过可量化的指标来衡量和驱动。
4.2 风险管理与应急机制
必须预先设计好应对各种“黑天鹅”事件的预案。
异常隔离与降级。一旦监控到上游数据源出现严重污染,自动化流程会立即切断该数据源的注入,并可选择性地将系统降级到备用数据源或使用最近一个“健康”版本的数据。
紧急修复与重算。对于公司行为处理错误等关键问题,平台支持“手工更正+自动化重算”流程。更正记录会被严格审计,并触发下游所有依赖数据的批量重算。
事后复盘机制。每一次数据事故都必须有详细的事故时间线报告(Post-mortem),分析根本原因、评估影响范围,并最终落实到对流程或质量规则的改进上,形成闭环。
结论
构建AlphaOS的数据底座,是一项复杂但回报巨大的基础工程。其核心设计哲学可以总结为以下几点。
治理左移。将数据质量和合规的校验,尽可能地前置到数据接入和处理的早期阶段。
一致性优先。在设计上,点时一致性和线上线下一致性的优先级高于一切。性能问题可以通过缓存、预计算等工程手段解决,但一致性问题是架构的根本。
数据与方法双版本化。不仅数据本身有版本,计算数据的方法(如因子算法)同样需要版本化管理,确保任何历史研究结果都具备100%的可复现性。
一切皆服务。将数据能力通过清晰的API和服务进行封装,实现“一处计算、多处复用”,避免重复建设和不一致性。
这个数据底座,最终交付的不仅仅是数据,更是一种确定性。它用工程化的严谨,为上层充满不确定性的策略研究,提供了一个最坚实、最可信赖的出发点。
📢💻 【省心锐评】
数据治理不是量化投研的成本中心,而是Alpha的生产车间。这份蓝图的核心,就是将数据从一种不稳定的“原材料”,转变为可度量、可信赖、标准化的“工业制成品”。

评论