.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】Token经济学将AI从抽象概念转变为可度量的生产要素。通过分析C/B端消耗模式与技术迭代,揭示了成本下降与需求暴增如何共同驱动AI商业化落地的正向飞轮,标志着AI产业正迈向成熟的工业化时代。
引言
去年五月,当大模型厂商纷纷卷入价格战的漩涡,Tokens无疑是科技圈出镜率最高的英文单词。
简单来说,Tokens是大语言模型(LLM)用来切割和处理自然语言文本的基本单位,我们可以直观地将其理解为“字”或“词”。
这个概念的重要性,远不止于一个技术术语。就像工业时代用“千瓦时”度量电力的消耗,互联网时代用“GB”度量数据的流量,AI时代则用“Token”来度量模型的工作量。一个Token,可以是一个词,也可以是一个词的片段,在中文语境里,它可能是一个字或一个词语。
Tokens的调用量,本质上反映了模型在进行推理(Inference)过程中的计算量。而计算量的高低,直接揭示了模型在实际应用中的能力、成本、速度和可行性。
所以,从Tokens的角度去跟踪AI应用的落地进展,是一个非常深刻且切中要害的视角。
它意味着我们将AI从一种近乎“黑箱魔法”或纯粹的技术概念,拉回到了一个可度量、可分析、可商业化的实际生产要素层面。我们不再仅仅关注AI“能做什么”,而是开始量化地分析它“做了多少”、“效率多高”、“成本多少”以及最终“价值多大”。
这篇文章将深入探讨Token经济学背后的逻辑,从模型厂商的定价策略,到C端和B端应用的Tokens消耗模式,再到技术迭代如何解锁新的应用需求,最终揭示一个正在加速转动的AI商业化正向飞轮。
一、📈 Token经济学的本质与底层逻辑
%20拷贝.jpg)
要理解AI产业的现在与未来,首先必须弄懂Token经济学的基本盘。它不是一个虚无缥缈的理论,而是支撑整个AI商业大厦的钢筋水泥。
1.1 Token:新时代的“度电”与“比特”
如果把AI大模型想象成一个巨大的“知识电厂”,那么Token就是它源源不断发出的“度电”。用户的每一个提示词(Prompt),都像是“合上电闸”的指令,启动了这座电厂的运转。而广大的AI应用开发者,则像是各式各样的“家电制造商”,他们设计出千姿百态的应用,来消耗这些“电力”,从而为用户创造价值。
这个比喻非常贴切。它形象地说明了Token在AI产业中扮演的双重角色。
技术层面,它是计算单元。模型处理的Token越多,意味着其内部的神经网络计算越复杂,消耗的算力资源也越多。
商业层面,它是计价单位。模型厂商正是基于Token的消耗量来向用户收费,构建起自己的商业模式。
这种设计,让AI的能力第一次变得可以被精确度量。它不再是模糊的“智能”或“强大”,而是可以被计入成本、核算收益的生产要素。
1.2 算力、营收与商业模式的强绑定
模型厂商以Tokens为主要定价单位,其底层逻辑清晰而直接,那就是模型调用时消耗的Tokens数量与相应的算力投入存在强关联性。算力,尤其是高端GPU的投入,是模型厂商最大的成本支出。将这部分成本通过Token消耗传导给用户,是最直接的商业闭环。
更深一层,算力投入链接了营收与Tokens调用量。这意味着,模型厂商的营收增长与其Tokens调用量的增长,呈现出显著的同步趋势。
一个极具说服力的例子来自OpenAI。
数据清晰地显示,Tokens调用量的爆炸式增长,直接推动了OpenAI营收的飞跃。这背后隐藏的结论是,谁消耗的Tokens更多,谁就是基础模型厂商的主流商业模式和核心收入来源。
因此,分析Token的消耗图景,就等于是在绘制AI产业的商业地图。
二、🗺️ 万亿级Token的消耗图景
那么,这些海量的、以万亿为单位计算的Tokens,究竟被谁消耗了?目前来看,消耗的主力军分为C端(消费者)和B端(企业)两大阵营。
2.1 C端消耗:流量巨头与原生应用的双轮驱动
C端用户基数庞大,是Tokens消耗的天然土壤。其消耗模式主要由三股力量驱动。
2.1.1 大流量池的AI改造
将AI功能嵌入到已经拥有庞大用户基础的成熟产品中,是目前最高效、最直接的Tokens消耗方式。这些产品本身就是巨大的流量入口,任何微小的功能迭代都可能带来天文数字的调用量。
这种模式的逻辑非常清晰,即利用存量用户优势,通过AI功能提升产品体验和用户粘性,从而在后台产生巨量的Token消耗。百度之于搜索,美图秀秀之于图像,都是在沿着这条路径进行AI化改造。
2.1.2 原生聊天助手的基石作用
以ChatGPT为代表的原生聊天助手,是AI时代的开创者,至今仍是C端Token消耗的基石。它们凭借先发优势和强大的模型能力,积累了规模惊人的忠实用户。
截至2025年7月,ChatGPT的APP与网页端合计月活用户达到了10.15亿。这个庞大的用户群体,通过日常的问答、创作、编程等活动,持续不断地为OpenAI贡献着重要的Tokens调用量。
2.1.3 新兴AI应用的商业化探索
除了上述两种模式,在图像、视频、陪伴、教育等垂直赛道,也涌现出一批极具潜力的新兴AI原生应用。它们从零开始,却凭借创新的产品体验快速吸引用户,并展现出强大的商业化能力。
字节跳动在这一领域的布局尤为引人注目,其产品矩阵覆盖了多个维度。
这些应用,特别是涉及多模态生成的场景,其单次操作的Token消耗量相当可观。例如,在Canva这类应用中接入文生图或文生视频模型,根据Gemini、Kimi等模型的折算口径,仅仅是生成一张图片,其消耗的Tokens量就在1024到1290之间。这还未计算用户为了获得满意结果而进行的多次尝试和修改。
2.2 B端消耗:企业级市场的全面渗透
如果说C端消耗的特点是“广”,那么B端消耗的特点就是“深”。企业级AI应用正以前所未有的速度渗透到各行各业的生产流程中,成为模型厂商越来越重要的收入支柱。
2.2.1 高渗透率的行业广度
生成式AI早已不是科技公司的专属玩具。Google发布的“全球601个领先企业AI应用案例”显示,AI已经深入到生产的毛细血管中。其应用范围覆盖了:
汽车与物流
商业与专用服务
金融服务
医疗与生命科学
酒店与旅游
制作、工业与电子
媒体、营销与游戏
零售
科技与通信
公共部门与非盈利组织
这11大行业的广泛采纳,意味着AI正在从一个“效率工具”转变为一个“生产力平台”。
2.2.2 高收入占比的商业深度
B端市场不仅广,而且“多金”。企业客户通常有更强的付费意愿和更高的客单价,这使得B端业务在模型厂商的营收结构中占据了举足轻重的地位。
这些数据强有力地证明,B端市场是AI商业化的主战场。根据数据,2025年上半年,仅中国企业级市场的日均总Token消耗量就达到了10.2万亿,其中阿里通义、字节豆包、DeepSeek三家合计占比超过40%。
三、⚙️ 技术迭代:解锁需求的“乘数效应”
%20拷贝.jpg)
观察Token消耗量,我们发现一个有趣的现象,其增长速度远远超过了用户数量的增长。越来越多的Tokens调用量,并非因为更大参数的大模型,而是源于技术迭代解锁了新的应用需求,带来了“乘数效应”。
用一句话概括就是,技术让原本做不到、做不好的事情,现在变得可能和可靠了。
3.1 从“能用”到“敢用”的质变
早期的AI应用,用户常常抱怨其“不准、不全、不落地”。而新一代的大模型,如GPT-5和Grok-4,其核心升级方向正是为了解决这些痛点。
GPT-5 将更强的推理能力(通过引入test-time compute)、多模态、更长上下文和更严格的安全控制置于产品默认层面。
Grok-4 的核心升级则是将原生工具调用、多代理协同推理和超长上下文等能力,整合成一个可商用的产品。
这些技术迭代的目标非常明确,即增强AI在更复杂、更具备“生产力”的关键场景下的实用性和准确性,从而加速AI应用的真正落地。
这种增强直接导致了单次任务Token消耗量的倍增。举一个客服场景的例子。
过去,一次简单的问答服务可能只消耗200 Tokens。
现在,一个升级后的客服流程,其背后的大模型推理过程可能扩展为:
客户意图澄清(约150-200 Tokens)
内部知识库检索与整合(约150-200 Tokens)
答案逻辑校验与事实核查(约150-200 Tokens)
最终答案生成与润色(约150-200 Tokens)
这样一个完整的、更可靠的服务流程,最终消耗的Tokens量达到了600至800 Tokens,是原来的3到4倍。类似的消耗倍增案例,在各种AI应用场景中都能找到。
3.2 四大技术趋势的价值重塑
随着技术趋势的不断推进,大量原本因效果不佳而被搁置的需求将被重新解锁。当AI的准确率和可控性跨过那条关键的“可行性线”后,用户,特别是对生产力有刚需的B端企业,将从犹豫观望转向批量采购。
这个过程主要由四大技术趋势驱动,它们分别重塑了AI应用的价值。
3.2.1 推理增强:把“能用”变成“敢用”
更强的逻辑推理和事实遵循能力,让企业敢于将AI用于核心业务流程,而不仅仅是边缘的辅助工作。
3.2.2 多模态融合:把“单点工具”变成“端到端工作流”
模型不再局限于处理文本,而是能够理解和生成图像、音频、视频。这使得AI可以覆盖一个完整的、从创意到成品的工作流,而不是仅仅作为某个环节的工具。
3.2.3 Agent化演进:把“对话”变成“可审计的业务系统”
AI Agent能够自主理解任务、规划步骤、调用工具并执行。这意味着AI从一个被动的问答机器,演变为一个可以独立完成复杂任务、并且其行为过程可追溯、可审计的业务伙伴。
3.2.4 长上下文革命:把“项目级任务”放进模型
上下文窗口的急剧扩大(从几千Token到上百万Token),使得模型可以一次性处理整本书、一份完整的财报或者一个复杂的项目代码库。这让AI能够处理过去无法想象的、宏大而复杂的任务。
这四大趋势共同作用的结果是双向增强,一方面,存量AI应用场景的解决方案变得更好、更可靠;另一方面,对应的Tokens调用量也实现了倍数级的增长。
四、🎡 AI飞轮:成本与需求的共舞
%20拷贝.jpg)
逻辑上,技术升级导致Token消耗量倍增,似乎意味着使用成本会急剧上升。但现实却恰恰相反。一个驱动AI产业爆发的核心机制——AI飞轮——已经成型,它的两个关键齿轮分别是“成本直线下降”和“需求加速增长”。
4.1 价格战:“百万Token买不了钵钵鸡”
自2024年起,大模型市场掀起了一场堪称惨烈的价格战。国内外厂商争相降价,其幅度之大令人咋舌。这句“一百万Tokens的钱,都买不了钵钵鸡”的调侃,生动地描绘了当时的市场状况。
这场价格战极大地降低了开发者和企业使用AI的门槛,使得许多原本因成本过高而无法启动的项目变得可行。
4.2 成本优化的幕后英雄
价格战的底气,并不仅仅是厂商为了抢占市场的“烧钱”行为,其背后是实实在在的技术进步和成本优化。模型厂商在看不见的地方,做了大量工作来压低“每度电”的成本。
这些优化可以分为软件和硬件两个层面。
软件层面(算法优化)
压缩单次推理计算量:通过稀疏化(只激活模型的一部分)、量化(降低计算精度)、投机解码(用小模型预测,大模型验证)等技术,减少每次调用所需的计算。
提升GPU利用率:通过连续批处理(Paging)、编译器融合(如TensorRT-LLM)等技术,让昂贵的GPU芯片尽可能地“忙起来”,减少空闲等待时间。
硬件层面(设施创新)
换用更便宜的云/芯片:寻找租金更低的云服务商,或者采用国产替代芯片、为AI推理任务专门设计的ASIC芯片。
硬件架构创新:例如,通过优化KV Cache(一种用于存储上下文信息的内存)的管理机制,可以显著减少推理时对显存的占用,从而在同等硬件上运行更大的模型或服务更多的用户。
这些复杂的幕后工作,共同促成了Token平均定价的大幅下降。
4.3 “模型分层”的精细化运营
除了普降,模型厂商还采取了更精细化的“模型分层+价格分层”策略。它们不再试图用一个“万能模型”解决所有问题,而是推出一个模型矩阵,以满足不同场景、不同预算的需求。
轻量级/低成本选项:OpenAI的GPT-5-mini/nano,Google的Gemini 2.5 Flash(主打极速低价),Anthropic的Claude 3.5 Haiku(主打高性价比)。
中高端/高性能选项:GPT-5、Claude 3.5 Sonnet等。
这种多样化的策略,让中小预算的客户也能轻松接入AI能力,进一步扩大了潜在的市场规模。
4.4 飞轮效应的形成与加速
至此,一个强大而清晰的AI正向飞轮已经完全展现在我们面前。
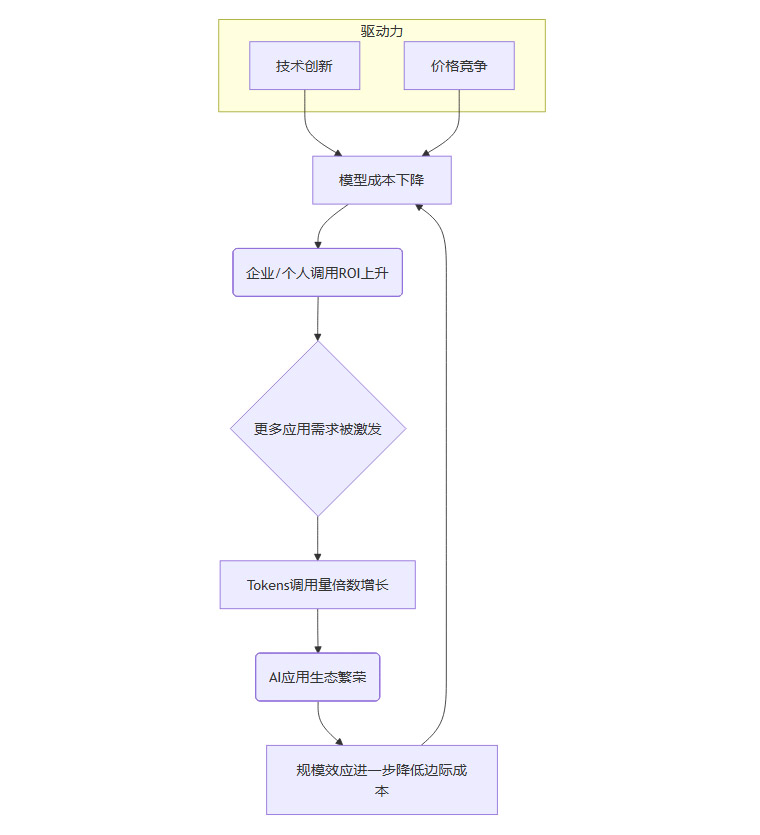
这个飞轮的运转逻辑是:
在技术创新和市场竞争的双重驱动下,模型使用成本持续下降。
成本下降直接导致企业和个人开发者使用AI的投资回报率(ROI)随之上升。
高ROI吸引了大量原本持观望态度的用户,他们开始从“看看”转向“采购”,更多、更深层次的应用需求被激发和解锁。
这反过来促进了Tokens调用量的倍数级增长。
海量的调用和繁荣的应用生态,带来了巨大的规模效应,这又会进一步摊薄模型厂商的研发和算力成本,为下一轮的降价和技术投入创造了空间。
商业化落地的强劲趋势已经显现。例如,谷歌的Gemini和字节的豆包大模型,其2025年由Token调用带来的月度收入,有望从千万美元/百万人民币的级别,跃升至亿美元/千万至亿人民币的级别。这正是飞轮加速转动的最好证明。
结尾
如果说AI大模型是这个时代的“知识电厂”,那么Token经济学就是它的“电网调度系统”和“电费账单”。从Tokens的角度去跟踪AI的落地进展,就相当于电力公司和社会在共同跟踪几个核心问题:
全社会总用电量(AI应用的总规模)增长了多少?
哪种家电(哪种AI应用)最耗电(消耗Token最多)?
发电技术是否进步了(模型效率)?每度电的成本是否下降?
新的高能效家电(高效的AI应用)是否被开发出来?
从这个视角出发,我们看到AI行业正在走向成熟、务实和工业化。它摒弃了早期对参数规模和技术炫技的过度关注,转而聚焦于一个更根本的问题,即如何以可承受的成本,可靠地利用AI能力来解决实际问题并创造商业价值。
这标志着AI不再是实验室里的昂贵玩具,而是真正成为了驱动下一代技术和商业创新的基础效用(Utility)。作为这个时代的从业者、投资者或观察者,理解Token经济学,就如同在互联网时代理解带宽成本一样,至关重要。它为我们提供了一个量化和洞察AI产业发展的关键视角,帮助我们看清成本结构、技术趋势和商业机会,并最终把握住这个时代的脉搏。
未来,谁能更高效地管理Token的消耗、优化其成本、并基于此激发新的应用需求,谁就能在这个由成本与需求共舞的飞轮上,占据最有利的位置。
📢💻 【省心锐评】
Token不再是成本,而是撬动价值的杠杆。飞轮已转,关键看谁能把“电”用出“花”,将算力高效转化为不可逾越的商业壁垒。

评论