.png)


【摘要】本文系统梳理了大模型驱动下AIOps在IT运维领域的最新进展,涵盖智能监控、告警优化、自动修复、资源调度等核心技术与行业实践,深入探讨其技术架构、落地挑战与未来趋势,旨在为企业智能化运维转型提供详实参考。
引言
在数字化浪潮席卷全球的今天,IT基础设施的复杂性与规模正以前所未有的速度增长。云计算、大数据、人工智能等新兴技术的广泛应用,推动着企业业务模式和技术架构的深刻变革。与此同时,运维体系也在经历着从传统人工、规则驱动向智能化AIOps(Artificial Intelligence for IT Operations)的转型。尤其是大模型(如GPT、BERT、LLM等)在生产环境中的落地应用,正成为智能运维的核心引擎。AIOps通过融合大模型、机器学习、深度学习与自动化技术,实现了对复杂IT系统的智能监控、告警优化、自动修复和资源调度,极大提升了运维效率与系统稳定性。本文将围绕大模型驱动下AIOps的最新进展,系统梳理其核心应用、技术架构、行业实践与未来趋势,力求为企业智能化运维转型提供全面、深入的参考。
一、背景与发展趋势
%20拷贝-qvuy.jpg)
1.1 数字化转型下的运维挑战
随着企业数字化进程的加速,IT系统的规模和复杂度不断提升。多云、混合云、微服务、容器化等新技术的引入,使得运维对象从单一服务器扩展到成千上万的节点、服务和应用。传统的人工巡检、静态规则和经验驱动的运维方式,已难以应对海量数据、复杂依赖和动态变化带来的挑战。主要表现为:
告警泛滥与误报:系统产生的告警数量呈指数级增长,人工筛查效率低下,误报、漏报频发。
故障定位困难:多源异构数据导致根因分析复杂,平均修复时间(MTTR)居高不下。
资源利用率低:静态资源分配难以适应业务波动,导致资源浪费或性能瓶颈。
运维人力压力大:重复性、机械性工作占据大量时间,创新与优化空间受限。
1.2 AIOps的兴起与演进
AIOps应运而生,通过引入人工智能、机器学习和自动化技术,赋能IT运维体系。其核心目标是:
实现对海量、多源、异构运维数据的智能分析与处理;
自动化异常检测、告警优化、根因定位与自愈修复;
动态资源调度与优化,提升系统弹性与稳定性。
近年来,随着大模型(如GPT、BERT、LLM等)在自然语言处理、时序分析、知识推理等领域的突破,AIOps的智能化水平实现了质的飞跃。大模型具备强大的语义理解、模式识别和知识推理能力,能够深度挖掘运维数据中的隐含规律,推动运维从“人盯监控”向“智能自治”转型。
1.3 大模型驱动AIOps的技术趋势
当前,大模型驱动下的AIOps呈现出以下发展趋势:
多模态数据融合:整合日志、指标、拓扑、链路追踪等多源数据,实现系统状态的全面感知与异常检测。
智能告警与根因分析:基于NLP和深度学习技术,自动归类、降噪、聚合告警,精准定位故障根因。
自动修复与智能自愈:结合知识库与自动化脚本,实现无人值守的自愈闭环。
资源优化与智能调度:基于业务负载预测与实时监控,动态调整资源分配,提升资源利用率。
可观测性与可解释性:强调全链路可观测性和AI决策的可解释性,增强运维团队对系统状态和AI行为的理解与信任。
二、核心应用与技术进展
2.1 智能监控与多模态数据融合
2.1.1 多模态数据融合分析
AIOps平台通过整合日志、性能指标、拓扑、链路追踪等多源数据,实现对系统状态的全方位监控和异常检测。以Nightingale(夜莺监控)和ELK集群为例,借助大模型分析,能够在10秒内定位如GC阻塞等复杂问题,极大提升了故障排查效率。
多模态数据融合的核心优势在于:
全面感知:覆盖系统运行的各个维度,避免“盲区”。
关联分析:通过大模型对不同数据源的语义理解,实现跨域异常关联与因果推理。
实时响应:高效的数据处理与分析能力,支持秒级异常检测与定位。
2.1.2 预测性维护
基于时序分析(如LSTM模型),大模型能够提前数小时至48小时预测硬件故障或资源瓶颈,自动触发资源扩容、服务重启等自愈操作。例如,华为云iOps平台通过预测性维护,实现了停机时间减少50%的显著成效。
预测性维护的关键技术包括:
时序数据建模:利用LSTM、Transformer等模型对指标数据进行趋势预测与异常检测。
风险评估与预警:结合历史故障案例与实时监控数据,动态评估系统健康状况,提前发出预警。
自动化响应:与自动化运维平台联动,自动执行扩容、重启等自愈操作,降低人工干预。
2.1.3 异常检测自动化
采用Isolation Forest、Transformer等算法,AIOps平台能够实时检测日志和指标中的异常模式,自动标记异常点并生成告警,显著降低误报率。通过深度学习动态调整告警触发条件,替代静态规则,精准识别关键错误。
异常检测自动化的实现路径:
多算法融合:结合无监督学习、深度学习与统计方法,提升异常检测的准确性与鲁棒性。
动态阈值优化:根据历史数据与实时波动,动态调整告警阈值,减少误报与漏报。
语义增强:利用大模型对日志、指标的语义理解,提升异常检测的智能化水平。
2.2 智能告警与根因分析
2.2.1 告警聚合与降噪
大模型结合NLP和深度学习技术,对海量告警进行语义理解、归类、降噪和聚合,自动识别核心异常,减少告警风暴和误报。例如,腾讯云实践中告警误报率降低70%,Nightingale通过FlashDuty减少70%无效告警。
告警聚合与降噪的核心机制:
语义归类:大模型对告警内容进行语义分析,将同源、同因的告警自动归并。
关联聚合:基于拓扑和依赖关系,自动聚合相关告警,突出核心异常。
降噪过滤:通过历史数据与模型学习,自动过滤无效或重复告警,提升告警信噪比。
2.2.2 智能告警分派与人性化描述
系统可根据告警严重性和业务影响动态调整通知策略,并将技术性告警转化为可读性更强的建议,提升运维决策效率。例如,系统自动将“CPU利用率异常”转化为“建议检查XX服务负载,可能存在流量突增”。
智能告警分派的实现要点:
动态分派:根据告警级别、影响范围和运维人员技能,自动分派告警任务。
人性化描述:大模型自动生成易于理解的告警说明和处理建议,降低沟通成本。
多渠道通知:支持邮件、短信、IM、工单等多渠道告警推送,确保信息及时传达。
2.2.3 多模态交互告警
结合AR眼镜与知识库,现场运维人员可实时获取设备故障识别和维修指南。例如,夏甸金矿应用后,故障排查时间缩短50%。AR+大模型的创新应用,极大提升了现场运维的效率与准确性。
多模态交互告警的应用场景:
现场辅助:AR眼镜实时显示设备状态、故障信息和维修步骤,提升操作效率。
知识库联动:大模型自动检索相关知识库内容,提供个性化维修建议。
远程协作:支持远程专家与现场人员的实时协作,提升复杂故障的处理能力。
2.2.4 动态阈值优化
通过深度学习动态调整告警触发条件,替代静态规则,精准识别关键错误。动态阈值优化能够适应业务波动和系统变化,提升告警的准确性与及时性。
动态阈值优化的技术路径:
历史数据建模:分析历史指标数据,建立动态阈值模型。
实时自适应:根据实时数据波动,自动调整阈值,避免因业务高峰或异常波动导致的误报。
多维度融合:结合多维指标与业务特征,提升阈值调整的智能化水平。
2.3 自动修复与智能自愈
2.3.1 闭环修复系统
大模型根据故障上下文自动生成修复指令并执行,如自动扩容GPU节点、降级模型版本、重启容器等,实现无人值守的自愈闭环。阿里云平台内置200+修复脚本,支持API调用和配置更新。
闭环修复系统的关键能力:
故障上下文感知:大模型自动分析故障发生的上下文信息,精准生成修复方案。
自动化执行:通过API、脚本等方式自动执行修复操作,减少人工干预。
结果验证与反馈:修复后自动验证系统状态,确保问题彻底解决,并将结果反馈至知识库,持续优化修复策略。
2.3.2 知识驱动修复策略
结合历史案例库和知识图谱,自动匹配最优解决方案。例如,某AI公司通过容器OOM事件与GPU显存曲线的关联,3分钟内完成容器重启。
知识驱动修复的实现机制:
案例库建设:积累历史故障与修复案例,形成知识库。
知识图谱关联:大模型自动构建故障与修复方案的知识图谱,实现智能匹配。
持续学习优化:每次修复结果自动反馈至知识库,模型持续学习优化修复策略。
2.3.3 变更风险预测
大模型可预测系统变更(如升级)的潜在影响,并推荐验证方案,降低变更带来的风险。通过对历史变更数据的分析,模型能够提前识别高风险变更,自动生成回滚与验证计划。
变更风险预测的技术要点:
变更影响分析:大模型对变更内容、依赖关系和历史影响进行综合分析,评估风险等级。
验证方案推荐:自动生成变更验证方案,确保变更安全可控。
回滚策略制定:为高风险变更自动制定回滚方案,提升系统韧性。
2.4 资源优化与智能调度
2.4.1 弹性扩缩容与智能调度
大模型根据业务负载预测和实时监控数据,动态调整资源分配,提升资源利用率,降低能耗和成本。通过对业务高峰、低谷的精准预测,实现资源的弹性扩缩容与智能调度。
资源优化与调度的核心能力:
负载预测:基于历史业务数据与实时监控,预测未来负载变化。
动态资源分配:自动调整计算、存储、网络等资源分配,适应业务需求。
能耗优化:通过智能调度,降低资源闲置与能耗,提升绿色运维水平。
三、技术架构与关键能力
%20拷贝-txwn.jpg)
3.1 数据采集与治理
全栈数据采集和高质量数据治理是AIOps智能化的基础。需加强数据清洗、标注和隐私保护,采用分布式存储(如Ceph)提升数据可用性。
3.2 智能分析与决策
集成监督、无监督、强化学习等多种AI算法,结合知识图谱、因果推理,实现异常检测、根因定位和自动化决策。
3.2.1 算法融合
监督学习:用于已知模式的异常检测与分类。
无监督学习:发现未知异常与新型故障。
强化学习:优化资源调度与自愈策略。
知识图谱与因果推理:实现多源数据的关联分析与根因定位。
3.2.2 决策自动化
异常检测:自动识别系统异常,生成告警。
根因分析:自动定位故障根因,生成修复建议。
决策执行:自动化执行修复、扩容、降级等操作,形成闭环。
3.3 自动化执行与自愈
通过自动化脚本、API调用、工单流转等机制,实现故障的自动修复和闭环处理。
3.3.1 自动化脚本与API
内置丰富的自动化脚本库,支持常见故障的自动修复。
通过API与各类运维工具、平台集成,实现自动化操作。
3.3.2 工单流转与闭环管理
自动生成工单,分派至相关人员或系统。
故障处理全流程可追溯,支持自动化闭环管理。
3.4 可观测性与可解释性
AIOps平台强调全链路可观测性和模型可解释性,提升运维团队对系统状态和AI决策的理解与信任。
3.4.1 全链路可观测性
覆盖应用、服务、基础设施全链路的监控与追踪。
支持多维度、多层级的数据可视化与分析。
3.4.2 模型可解释性
提供模型决策过程的可视化与解释,增强用户信任。
支持模型输出的溯源与验证,保障决策透明。
四、行业落地与实践案例
4.1 华为云:大小模型协同的智能运维
华为云构建了大小模型协同的运维系统,整合故障预测、根因定位等模块,实现了人效提升40%。通过多模态数据融合与大模型驱动的智能分析,华为云能够实现秒级故障定位与自动修复,极大提升了运维效率与系统稳定性。
4.2 夜莺监控(Nightingale):专项监控与告警优化
Nightingale平台新增大模型专项监控模板,实现GPU显存泄漏检测准确率提升40%。通过FlashDuty模块,告警误报率降低70%,有效缓解了告警风暴问题。平台支持多模态数据融合与动态阈值优化,提升了异常检测与告警管理的智能化水平。
4.3 中兴通讯:通信大模型驱动的运维智能体
中兴通讯基于通信大模型构建了运维智能体,实现了网络性能异常的自愈闭环。系统能够自动检测网络异常、定位根因并执行修复操作,显著提升了网络运维的自动化与智能化水平。
4.4 金融、电商、能源等行业的广泛应用
金融、电商、能源等行业已广泛部署AIOps,实现了故障预测准确率提升、MTTR大幅缩短、资源利用率优化。例如,某电商平台通过AIOps实现了秒级故障定位和自动修复,某能源企业利用大模型实现设备工况的精准诊断和预警,极大提升了业务连续性与系统稳定性。
4.5 AR+大模型现场运维的创新实践
在夏甸金矿等场景,AR眼镜结合知识库与大模型,实现了现场维修效率提升40%。运维人员通过AR设备实时获取设备状态、故障信息和维修指南,极大提升了现场运维的效率与准确性。
4.6 典型行业应用场景与成效对比
不同类型企业在AIOps落地过程中,结合自身业务特点,形成了多样化的应用模式。下表对比了部分典型行业的AIOps应用场景与成效:
五、挑战与未来展望
%20拷贝-ynue.jpg)
5.1 数据质量与安全
AIOps的智能化能力高度依赖于高质量的数据。现实中,运维数据常常存在噪声、缺失、格式不统一等问题,影响模型训练和推理的准确性。此外,运维数据涉及大量敏感信息,数据安全与隐私保护成为企业关注的重点。为此,企业需加强数据清洗、加密、脱敏和分级治理,确保数据的可用性与合规性。
5.1.1 数据治理的关键措施
自动化数据清洗与标准化流程,提升数据一致性。
引入数据标注平台,结合人工与自动化标注,提升模型训练质量。
实施数据分级、加密与访问控制,防止数据泄露与滥用。
建立数据质量监控体系,持续评估与优化数据源。
5.2 模型泛化与定制化
AIOps模型在不同业务场景、不同厂商平台间的泛化能力仍是技术难点。业务差异、数据分布变化、系统架构多样性等因素,导致模型迁移和复用面临挑战。模块化设计、迁移学习和持续学习成为提升模型泛化能力的主要策略。
5.2.1 泛化能力提升路径
采用模块化模型架构,便于在不同场景下灵活组合与扩展。
利用迁移学习,将已有模型知识迁移到新业务场景,减少冷启动成本。
持续学习与在线训练,模型根据新数据不断自我优化,适应业务变化。
建立跨场景的知识图谱,增强模型的知识迁移与推理能力。
5.3 人机协同与组织变革
AIOps的落地不仅是技术升级,更是组织与流程的深刻变革。传统运维团队需与数据科学家、开发工程师深度协作,推动数据驱动的运维文化。AI Agent+知识库模式降低了运维门槛,但人机协同、技能提升与组织文化建设同样重要。
5.3.1 组织变革的关键举措
建立跨部门协作机制,促进运维、开发、数据科学团队的深度融合。
推动数据驱动的决策文化,强化数据素养与AI技能培训。
优化运维流程,结合AI Agent与知识库,实现人机协同高效闭环。
鼓励创新与持续改进,形成敏捷、开放的运维生态。
5.4 可解释性与信任
AI决策的可解释性和透明度,是AIOps大规模落地的前提。运维团队需要理解AI模型的决策逻辑,才能信任并采纳其建议。为此,AIOps平台需提供模型决策过程的可视化、溯源与验证机制,保障决策的透明与可控。
5.4.1 可解释性提升措施
引入可解释AI(XAI)技术,提供模型推理过程的可视化与解释。
支持模型输出的溯源与验证,便于运维人员追踪与复盘。
建立模型评估与反馈机制,持续优化模型的可解释性与准确性。
5.5 未来趋势展望
5.5.1 从辅助决策到自治系统
AIOps正从“辅助决策”向“无人值守”与“全自动化SRE”演进。未来,AI有望自主处理90%以上的告警,实现真正的自治运维系统。运维人员将从“救火队员”转变为“智能运维架构师”,专注于系统优化与创新。
5.5.2 多模态融合与边缘智能
随着物联网、边缘计算的普及,AIOps将整合更多数据源,实现毫秒级故障响应。边缘智能的引入,使得运维决策能够在本地快速完成,提升系统的实时性与鲁棒性。
5.5.3 深度强化学习与数字孪生
深度强化学习将推动AIOps向自主运维、无人化和全链路智能演进。数字孪生技术的应用,使得运维团队能够在虚拟环境中模拟、预测和优化系统行为,提升运维的前瞻性与主动性。
5.5.4 预测性运维的深化
未来AIOps将进一步提升故障预测的精度,实现更早期的预警和更高的系统稳定性。通过持续学习与知识积累,AIOps有望实现“零故障”目标,推动企业运维体系迈向更高水平。
六、AIOps全流程智能化运维示意
为更直观展现AIOps在大模型驱动下的全流程智能化运维,以下以Mermaid流程图形式描述典型运维闭环:
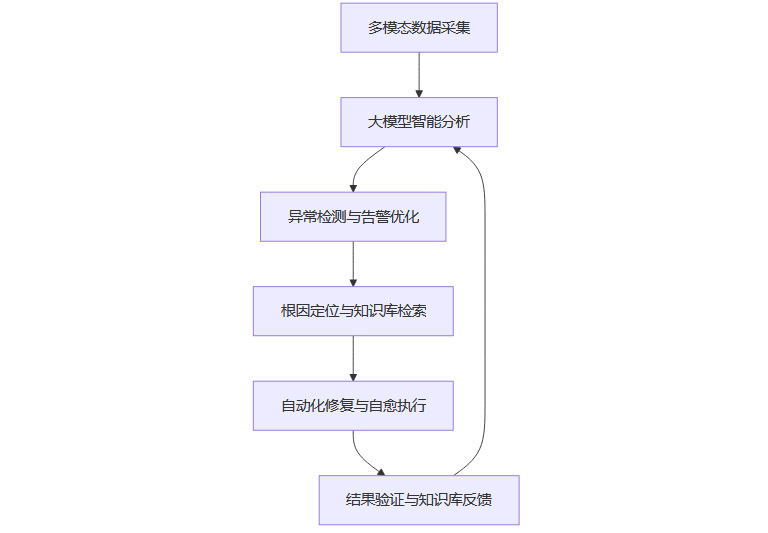
该流程体现了AIOps的核心闭环能力:从多源数据采集、智能分析、异常检测、根因定位、自动修复到结果反馈,形成持续优化的智能运维体系。
七、AIOps平台能力矩阵
下表总结了AIOps平台在大模型驱动下的核心能力模块及其关键价值:
八、结论
大模型与AIOps的深度融合,正推动IT运维体系从“救火式”向“预防式”、从“辅助决策”向“自治系统”转型。通过多模态数据融合、智能异常检测、告警降噪、自动化自愈和资源优化,AIOps显著提升了运维效率和系统稳定性。尽管在数据质量、模型泛化、组织协作、可解释性等方面仍面临挑战,但随着技术进步和行业实践的积累,AIOps有望成为未来主流运维范式。企业应积极拥抱智能化运维,构建数据驱动、智能自治的运维体系,为业务创新与持续竞争力提供坚实保障。
📢💻 【省心锐评】
AIOps的终极战场不在算法而在数据治理,当前企业需构建标准化数据管道,方能释放大模型潜能。

评论