.png)
%20%E6%8B%B7%E8%B4%9D.jpg)

【摘要】腾讯混元团队推出的UloRL(超长输出强化学习)算法,突破了大语言模型在复杂推理任务中的效率与能力瓶颈。通过分段生成、动态遮蔽和生成式验证等创新机制,UloRL显著提升了AI的深度思考与推理准确性,为AI在教育、科研、工程等领域的专家化应用奠定了坚实基础。
引言
人工智能的进步,正悄然改变着我们对“智能”的定义。曾几何时,AI被视为高效的工具,擅长在海量数据中迅速给出答案。然而,随着应用场景的复杂化,单纯的“快答”已无法满足人类对智能的更高期待。我们渴望AI不仅能回答问题,更能像专家一样,展现出深度思考、严密推理的能力。腾讯混元团队最新发布的UloRL(Ultra-Long Output Reinforcement Learning)算法,正是对这一需求的有力回应。本文将深入剖析UloRL的技术创新、实际成效及其对AI推理能力的深远影响。
一、AI深度思考的时代:从快答到慢思
%20拷贝.jpg)
1.1 人类专家的思维方式:耐心与细致
面对一道复杂的数学题,经验丰富的解题者往往会在草稿纸上写下详尽的推理步骤,反复推敲每一个环节。这种“慢思考”不仅是对问题的尊重,更是通向正确答案的必经之路。人类专家的这种耐心与细致,正是AI长期以来难以企及的能力。
1.2 传统AI的困境:快进快出,难以深度推理
当前主流的大语言模型,虽然在许多任务上表现出色,但在复杂推理场景下,往往陷入“快进快出”的模式。它们习惯于迅速给出答案,缺乏对推理链条的耐心梳理。尤其在面对需要多步推理、长链条逻辑的问题时,这种模式极易导致错误。
1.3 超长推理链的价值与挑战
研究发现,允许AI生成更长、更详细的推理过程,能够显著提升其解决复杂问题的能力。这一现象在数学、逻辑、工程等领域尤为突出。然而,超长输出也带来了前所未有的技术挑战,尤其是在训练效率和推理准确性之间的平衡上。
二、UloRL算法的核心创新
2.1 分段生成:高效处理超长推理链
2.1.1 传统强化学习的“长尾效应”困境
在传统的强化学习训练中,所有样本需同步完成生成,才能进入下一轮训练。这种机制在短文本任务中尚可接受,但在超长推理链场景下,极易出现“长尾效应”——大部分样本很快完成,少数超长样本拖慢整体进度,导致计算资源浪费和训练效率低下。
2.1.2 分段生成策略的提出与实现
UloRL巧妙地引入了“分段生成”机制。将超长推理过程切分为多个段落,每段长度适中(如1.6万个词符)。每当一个段落生成完毕,若未得出最终答案,则暂存,待后续继续生成。已完成推理的样本则立即进入训练流程。
分段生成流程图:
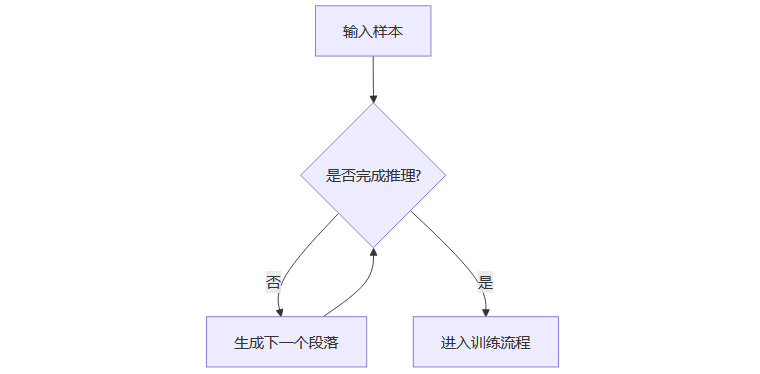
2.1.3 效率提升的实证
实验显示,采用两段分段生成,训练速度提升1.6倍;四段分段生成,提升2.06倍。原本需一天完成的训练任务,现仅需半天,极大降低了训练成本。
2.2 重要性采样:确保训练准确性
2.2.1 混合段落的评估难题
分段生成带来一个新问题:一个推理链可能由不同版本模型生成的段落拼接而成,如何准确评估其训练价值?
2.2.2 段落感知重要性采样(SAIS)与伪在线重要性采样(POIS)
SAIS:精确追踪每段由哪个模型版本生成,动态调整训练权重。
POIS:简化处理,假定所有段落均由最新模型生成,计算更高效,训练更稳定。
2.2.3 实验对比与结论
在多种输出长度下,POIS方法在推理准确性和训练稳定性上均优于SAIS,且实现更为简洁,适合大规模实际应用。
2.3 动态遮蔽已掌握正面标记(DMMPTs):防止熵坍塌
2.3.1 熵坍塌现象的本质
随着训练深入,模型输出趋于单一,丧失多样性,类似学生只会背标准答案,缺乏创新与灵活性。这种“熵坍塌”严重制约了AI的推理能力。
2.3.2 DMMPTs策略的创新机制
持续监控模型输出多样性。
当多样性低于阈值时,自动识别并遮蔽预测概率超99%的标记。
促使模型关注尚未掌握的部分,恢复多样性。
多样性恢复后,解除遮蔽,回归正常训练。
2.3.3 多模型规模下的验证
在千文3-4B、3-8B、3-30B-A3B等不同规模模型上,DMMPTs均能有效维持多样性,确保推理能力与灵活性同步提升。
2.4 生成式验证器:智能评判AI推理结果
2.4.1 传统评判方法的局限
基于规则的答案匹配,难以识别等价表达,易误判。例如,“9π平方厘米”与“28.27平方厘米”本质相同,但格式不同。
2.4.2 生成式验证器的工作原理
利用生成式AI理解答案语义,判断不同表达是否等价。
类似经验丰富的老师阅卷,关注实质而非表面。
2.4.3 数据清理与优化
删除多子问题题目,避免因回答不完整被误判。
统一题型格式,防止AI通过猜测得分。
利用多模型一致性,识别并剔除标准答案有误的题目。
2.4.4 超长回答的处理策略
对于因长度限制被截断的回答,直接判为不正确。实验表明,这一简化策略与复杂处理方法效果相当,系统实现更为高效。
三、UloRL的实验验证与实际成效
%20拷贝.jpg)
3.1 实验设计与参数设置
基础模型:千文3-30B-A3B
最大输出长度:128k词符,分8段,每段16k词符
优化器:AdamW,学习率1×10^-6
每项测试重复32次,取平均值,确保结果可靠
3.2 主要实验结果
30B参数模型经UloRL训练后,超越了235B参数的更大模型,显示出训练方法优化的巨大潜力。
3.3 组件消融实验
去除DMMPTs策略后,AIME2025准确率降至78.6%,BeyondAIME降至57.1%,验证了动态遮蔽策略对推理能力提升的关键作用。
3.4 输出长度对性能的影响
32k词符下,性能提升有限,因基础模型已表现优异。
64k、96k、128k词符下,性能提升显著,验证了“更长推理链带来更好性能”的假设。
3.5 Yarn技术扩展与进一步提升
通过Yarn技术将输出长度扩展至140k词符,模型在AIME2025和BeyondAIME上的准确率分别达到85.1%和61.9%,进一步巩固了超长推理链的价值。
四、UloRL的技术深度与广度
4.1 分段生成的普适性
分段生成不仅适用于数学推理,在长文档理解、代码生成、创意写作等需处理超长序列的任务中同样适用。其核心思想是将复杂任务拆解为可管理的子任务,提升整体效率与可控性。
4.2 动态遮蔽策略的启示
DMMPTs揭示了高效学习的本质:资源应聚焦于尚未掌握的知识点,而非反复强化已熟练内容。这一理念可推广至各类机器学习任务,优化训练资源分配。
4.3 生成式验证器的未来趋势
用AI训练AI,已成为提升数据质量与训练效率的重要手段。生成式验证器不仅提升了奖励信号的准确性,也为AI自我改进、自我监督提供了技术基础。
4.4 UloRL对AI专家化的推动
UloRL的成功,标志着AI从通用型向专家型转变。未来,AI将在教育、科研、工程等领域,成为具备深度推理能力的智能伙伴,而非仅仅是信息检索工具。
五、UloRL的行业应用前景
%20拷贝.jpg)
5.1 专业领域的深度应用
教育:AI数学家教,能够详细讲解解题思路,辅助学生理解复杂概念。
法律:AI法律顾问,能梳理案件逻辑,推演多种判决可能。
工程:AI设计助手,参与复杂方案论证与优化。
5.2 普通用户的未来体验
随着技术成熟,普通用户也将受益于具备深度思考能力的AI助手。无论是学业辅导、生活决策还是职业发展,AI都能提供专家级的分析与建议。
5.3 技术开放与生态共建
UloRL相关代码与模型已开源,全球研究者与开发者可基于此进行创新,推动AI推理能力的持续进化。
六、UloRL的技术与社会意义
6.1 重新定义AI推理能力
UloRL证明,AI的推理能力不仅取决于模型规模,更取决于训练方法的科学性。通过“慢思考”,AI能够像人类专家一样,步步为营地解决复杂问题。
6.2 AI与人类专家的协作新模式
随着AI推理能力的提升,人机协作模式将发生深刻变化。AI将不再是简单的工具,而是能够与人类专家并肩作战的智能伙伴。
6.3 可解释性与可信度的挑战
AI推理过程的可解释性与可信度,将成为未来研究的重点。只有让用户理解并信任AI的推理链条,AI才能在关键领域发挥更大作用。
6.4 技术进步与社会责任
AI能力的提升,既带来机遇,也伴随风险。如何确保AI推理的可靠性、防止被恶意利用、维护人类主导地位,是全社会需要共同面对的问题。
结论
UloRL算法的诞生,标志着AI推理能力迈入新纪元。通过分段生成、动态遮蔽和生成式验证等创新机制,腾讯混元团队不仅解决了超长推理链训练的效率与准确性难题,更为AI在专业领域的专家化应用奠定了坚实基础。未来,具备深度思考能力的AI将成为人类解决复杂问题的得力助手,推动社会各领域的智能化升级。与此同时,AI推理能力的提升也对可解释性、可信度和社会责任提出了更高要求。UloRL的开源与开放,为全球AI研究者提供了宝贵资源,必将加速AI推理能力的持续进化。让我们共同期待,AI在深度思考的道路上,走得更远、更稳、更智慧。
论文来源:https://github.com/liushulinle/ULORL
📢💻 【省心锐评】
UloRL让AI真正学会“慢思考”,推理能力质变,未来AI专家化已现雏形。

评论