.png)


【摘要】Search-R1开创了大语言模型“边查资料边思考”的新范式,通过强化学习赋予AI主动检索与多轮推理能力,显著提升复杂问题解答与泛化能力,推动AI从静态知识库迈向动态学习型智能体。
引言
在人工智能领域,如何让大语言模型(LLM)真正具备“像人一样思考”的能力,一直是学界和业界追求的目标。人类在面对复杂问题时,往往会先思考,再查找资料,反复验证,最终得出答案。而传统的AI系统,无论是依赖庞大的预训练知识库,还是采用检索增强生成(RAG)等技术,始终难以实现这种“边思考边查资料”的动态认知过程。
2025年,伊利诺伊大学厄巴纳-香槟分校金博文团队联合马萨诸塞大学阿默斯特分校、谷歌云AI等机构,提出了Search-R1框架。这一创新性研究不仅在COLM会议上发表,更以开源的方式推动了AI领域的范式变革。Search-R1通过强化学习,让大语言模型学会主动发起检索、动态整合外部信息,并在多轮推理中不断优化自身决策,极大提升了AI在复杂任务中的表现和泛化能力。
本文将系统梳理Search-R1的技术原理、创新机制、实验表现、应用前景与挑战,并结合真实案例,深入探讨其对AI未来发展的深远影响。
一、核心创新与技术机制
%20拷贝.jpg)
1.1 Search-R1的提出背景
1.1.1 传统AI的局限
只依赖内部知识库,难以应对实时变化和知识盲区。
检索增强生成(RAG)等方法仅支持单轮检索,且检索与推理割裂。
工具调用类AI需大量人工标注,泛化能力弱,训练和落地成本高。
1.1.2 人类式“边思考边查资料”的启发
人类遇到复杂问题时,常常先思考,再查找资料,反复验证,最终得出答案。
这种“思考-搜索-再思考”的循环,是高阶认知与创造力的基础。
1.2 Search-R1的技术亮点
1.2.1 强化学习驱动的主动搜索与推理
模型在推理过程中可随时发起搜索,形成“思考-搜索-再思考”的循环。
训练时无需人工标注搜索轨迹,仅依赖最终答案的正确性作为奖励信号,极大降低了训练难度和数据需求。
1.2.2 多轮交错推理与检索机制
通过结构化标记(如、、、等)管理推理、搜索和答案输出。
支持动态、多轮的信息获取与整合,显著提升复杂问题的解答能力。
1.2.3 检索内容掩码与奖励机制
训练时只优化模型自主生成的内容,对外部检索内容不反向传播梯度,保证训练稳定性和外部知识的真实性。
奖励机制极为简洁,仅基于最终答案的正确性,无需复杂的过程奖励。
1.2.4 多种RL算法兼容
支持PPO(近端策略优化)、GRPO(群体相对策略优化)等主流强化学习算法,兼顾训练稳定性与收敛速度。
1.3 Search-R1的工作流程
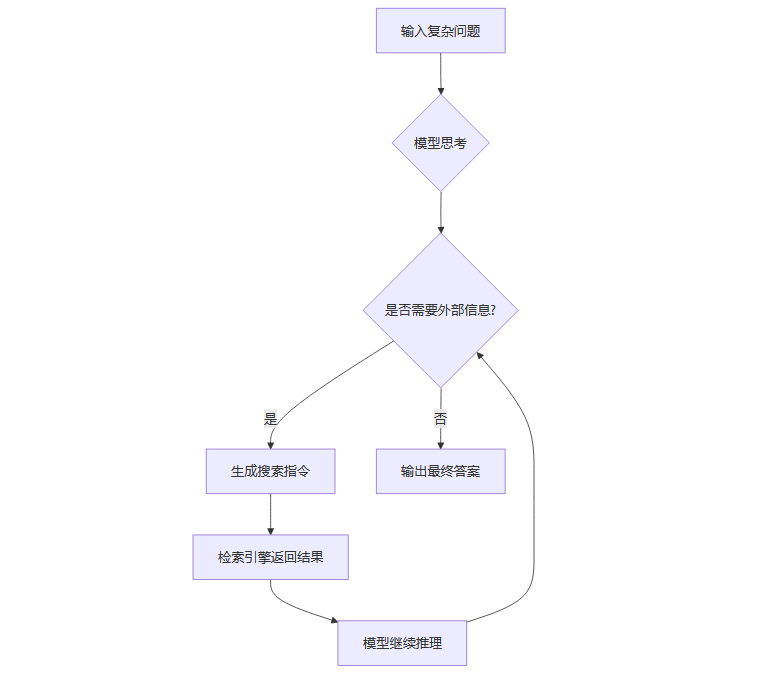
1.4 技术机制表述
二、性能表现与应用案例
2.1 显著性能提升
2.1.1 多数据集系统性验证
在NQ、TriviaQA、HotpotQA、2WikiMultiHopQA等七个问答数据集上,Search-R1在Qwen2.5-7B模型上相对提升26%,Qwen2.5-3B提升21%,LLaMA3.2-3B提升10%。
尤其在多跳推理任务上表现突出,能够有效整合多轮检索信息,显著提升复杂问题的解答能力。
2.1.2 泛化与适应性
不仅在训练集上表现优异,在未见过的新任务和领域也展现出良好泛化能力,证明其学到的是“如何搜索和推理”的能力,而非死记硬背答案。
2.1.3 与主流基线方法对比
2.2 真实案例分析
2.2.1 复杂问题分解与多轮检索
问题:“好奇香水是由哪个城市和州出生的歌手创作的?”
Search-R1推理流程:
首先思考需要找出香水的创作者。
发起第一次搜索,检索“好奇香水信息”,发现布兰妮·斯皮尔斯为代言人。
第二次搜索“布兰妮·斯皮尔斯出生地”,获得密西西比州麦库姆。
第三次搜索“麦库姆,密西西比州位置”确认地理信息。
输出最终答案:“麦库姆,密西西比州”。
2.2.2 自适应搜索与知识整合
问题:“克里斯·杰里科和加里·巴洛有什么共同职业?”
Search-R1多轮搜索,先分别获取两人信息,再搜索共同点,最终确认两人都是音乐家。
2.2.3 失败案例与改进空间
问题:“Weezer乐队首张专辑名称?”
Search-R1检索到“蓝色专辑”信息,但最终输出为“Weezer”,显示在复杂语言理解和细致推理方面仍有提升空间。
2.3 性能提升的本质
Search-R1的提升不仅体现在准确率数字,更在于其主动分解任务、动态整合信息、反复验证答案的能力。
这种能力极大拓展了AI在复杂、开放、动态环境下的适应性和实用性。
三、变革性应用场景
%20拷贝.jpg)
3.1 智能研究与教育助手
支持学术研究、个性化学习,动态整合多源信息,生成定制化解答。
能够根据学习者需求,主动查找最新资料,辅助知识梳理与创新。
3.2 专业决策支持
在金融、医疗、法律等领域,实时抓取和分析多源信息,辅助专家做出高质量决策。
能够动态监控市场、政策、舆情等变化,生成实时报告或预警。
3.3 动态信息服务
新闻舆情分析、客户服务等场景,持续整合多渠道信息,生成实时、精准的解决方案。
支持多轮交互,提升用户体验和服务质量。
3.4 创意产业与内容生成
为内容创作、设计等领域提供灵感激发和素材整合。
能够主动查找相关案例、趋势、数据,辅助创意生成与优化。
四、面临的挑战与局限
4.1 信息可信度与偏见风险
Search-R1高度依赖外部搜索结果,若检索到虚假或有偏见的信息,可能导致错误推理。
需加强信息源可信度评估和事实核查机制,防止“垃圾进,垃圾出”。
4.2 “搜索依赖症”与思考惰性
过度依赖外部检索可能削弱AI及用户的深度推理和批判性思维能力。
需平衡自主推理与外部信息整合,防止“机械查找”取代“深度思考”。
4.3 效率与成本
多轮搜索增加响应延迟和计算成本,对大规模部署和实时性场景构成挑战。
需优化检索策略和模型结构,提升效率与可扩展性。
4.4 可解释性与责任归属
多轮推理-搜索过程复杂,决策链条难以追溯,责任界定和可解释性需进一步提升。
需开发可视化工具和决策溯源机制,增强用户信任和监管合规。
4.5 技术局限
当前主要支持文本检索,尚未实现多模态(如图像、视频)信息整合。
奖励机制仅基于最终答案,难以捕捉中间推理质量,影响复杂任务的优化。
五、未来发展方向
%20拷贝.jpg)
5.1 智能化、多模态检索
开发更智能的搜索代理,支持语义、布尔逻辑、多模态(图像、视频、结构化数据)检索。
实现跨模态信息整合,提升AI对现实世界的理解和适应能力。
5.2 深度融合推理与验证
结合内部知识库、事实核查、交叉验证和符号推理,提升信息整合与推理的准确性和鲁棒性。
引入多源信息一致性检测,防止被单一错误信息误导。
5.3 人机协作与可控性
增强推理过程透明度,允许用户介入和反馈,提升系统可解释性和用户信任。
支持用户自定义检索策略和推理偏好,实现个性化智能助手。
5.4 高效训练与轻量化部署
探索更高效的RL算法、模型压缩和知识蒸馏,实现小模型在边缘设备上的部署。
降低训练和推理成本,推动AI普及到更多实际场景。
5.5 伦理与安全框架
制定主动搜索AI的伦理准则,强化信息溯源、偏见审查和用户知情权。
建立责任追溯和合规监管机制,保障AI安全可控发展。
六、结语:通向“动态学习型”通用智能
Search-R1的最大突破,在于模拟并自动化了人类主动获取和整合外部知识的认知过程,标志着大语言模型从“静态知识库”向“动态学习代理”的关键转变。它不仅提升了AI在复杂任务中的表现,更为通用人工智能(AGI)提供了一条可行路径——通过强化学习赋予AI自主探索和持续成长的能力。
尽管前路仍有信息可信度、效率、伦理等挑战,但Search-R1已点亮了AI助手未来的方向:不再只是“百科全书”,而是能够主动求知、持续验证、动态成长的“智能伙伴”。
对于普通用户而言,未来的AI助手将不再局限于预训练知识,而是能够像人类一样主动搜索最新信息,进行深入思考,给出更准确、更全面的答案。无论是学术研究、专业决策,还是日常生活,Search-R1都将成为值得信赖的智能助手。
有兴趣深入了解这项研究技术细节的读者,可访问研究团队提供的开源代码仓库,亲自体验这种新一代的搜索推理能力。
论文与代码开源地址:
https://github.com/PeterGriffinJin/Search-R1
📢💻 【省心锐评】
“Search-R1将认知科学与强化学习熔铸为利剑,斩开了静态AI的枷锁。其价值不在答案本身,而在获取答案的智慧。”

评论