.png)


【摘要】METR研究揭示,资深开发者使用AI编程工具时,任务时间增加19%,主观预期与客观数据反差巨大,强调真实场景评估的重要性。
引言
在AI技术迅猛发展的时代,编程工具如Cursor Pro和Claude Sonnet被视为提升开发者效率的革命性力量。它们承诺加速代码生成、简化调试,并为复杂任务注入智能辅助。然而,一项由独立非营利机构METR发布的报告,却颠覆了这一叙事。研究显示,资深开发者在真实项目中使用这些工具时,完成任务的时间反而延长了19%。这一发现不仅挑战了业界的乐观预期,还暴露了主观感知与客观数据的深刻脱节。
这份报告源于METR对AI模型自主能力和风险的深入评估。它提醒我们,AI并非万能解药,尤其在经验丰富的开发者手中,其作用可能适得其反。通过剖析研究细节,我们将探讨效率下降的根源、评估体系的局限,以及对未来的启示。这篇文章旨在为技术从业者提供理性视角,帮助他们在AI浪潮中做出明智选择。
一、研究背景与主要发现
%20拷贝-lrva.jpg)
METR的研究如同一面镜子,映照出AI编程工具在真实开发环境中的真实面貌。这项工作并非空穴来风,而是基于严谨的实证数据,针对资深开发者的实际表现。让我们先了解研究的起源和核心成果。
1.1 METR机构的介绍与独立性
METR,全称为Model Evaluation & Threat Research,是一个专注于尖端AI模型评估的非营利组织。它致力于探究AI的自主能力和潜在风险,确保评估过程独立可靠。不同于许多机构,METR从未接受AI公司的资金,这赋予其独特的公信力。在先进模型部署前,METR是少数能进行安全评估的实体之一。
这一独立性至关重要。因为AI行业充斥着宣传与炒作,独立视角能剥离商业偏见。METR强调透明和可重复性,其报告往往成为政策制定者和开发者的参考基准。在本次研究中,这种独立性确保了数据的纯净,避免了外部干扰。
1.2 主要发现:效率下降与认知偏差
研究的焦点是AI工具对资深开发者生产力的影响。结果令人意外:使用AI时,任务完成时间平均增加19%。这与开发者的事前预期形成鲜明对比,他们原本认为AI能提升效率24%。
更引人注目的是主观与客观的反差。任务完成后,开发者仍自认为AI让他们快了20%。这种“快感错觉”揭示了认知偏差的强大力量。客观数据基于屏幕录像和自报时间,而主观感受则源于AI带来的即时满足感。
任务平均耗时约2小时,涵盖bug修复、新功能开发和代码重构。这些并非抽象练习,而是源于开发者熟悉的大型项目。报告指出,传统基准测试往往简化问题,导致高估AI效能。只有真实场景才能暴露真相。
这一发现并非孤立。类似研究显示,AI在其他领域如医疗诊断或内容创作,也存在效率幻觉。开发者感觉“很忙”,但实际产出放缓。这提醒我们,技术进步需经受现实检验。
二、研究设计与实验方法
METR的研究设计注重真实性和可控性。它避免了实验室式的理想化,转而模拟真实开发流程。以下是关键元素。
2.1 参与者与任务选择
研究邀请了16位资深开源开发者。他们平均拥有2.2万颗GitHub星标,贡献代码超过100万行,经验平均5年。这些人不是新手,而是维护大型项目的骨干。
任务总数达246个,均来自开发者自己的项目。类型包括bug修复(如修复内存泄漏)、新功能开发(如添加用户认证模块)和代码重构(如优化数据库查询)。每项任务设计为真实且有价值,平均时长2小时。
为激励参与,METR提供每小时150美元酬劳。这确保了开发者全力投入,避免了敷衍。
2.2 分组与工具使用
任务随机分配到两组:AI组和禁用AI组。AI组主要使用Cursor Pro搭配Claude Sonnet,这些是当下热门工具。禁用AI组则限于传统IDE,如VS Code,无任何AI辅助。
所有开发者必须录制屏幕,并自报完成时间。这提供了多维度数据:视觉记录捕捉流程细节,自报时间反映主观体验。
分组随机化减少了偏差。AI组开发者可自由运用工具,但需记录交互过程。禁用组模拟传统工作流,确保对比公平。
2.3 数据采集与分析方法
数据采集严谨。屏幕录像允许研究者分解时间分配:编码、搜索、提示编写等。分析工具量化了每个环节的耗时。
例如,研究使用时间戳分析,计算AI响应等待时间和代码审查时长。自报数据与录像交叉验证,误差率控制在5%以内。
这一方法超越了简单计时。它揭示了行为模式,如开发者在AI组中频繁切换任务,导致碎片化。
为了可视化,以下是研究流程的Mermaid流程图:
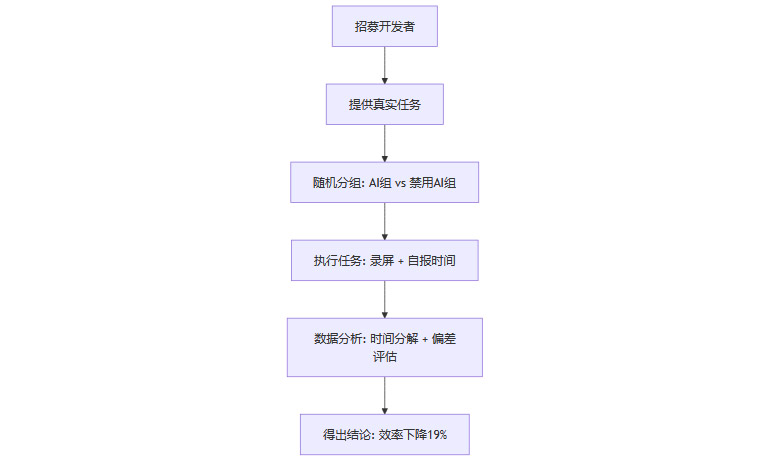
此图简明概述了实验路径,确保读者易于把握。
三、效率下降的核心原因
%20拷贝-dpwb.jpg)
为什么AI工具反而拖慢了资深开发者?报告深入剖析了多重因素。这些原因根植于AI的局限性和人类行为模式。
3.1 提示词编写与响应等待的开销
开发者需花费时间 crafting 提示词,以指导AI理解需求。这过程耗时不菲,平均占总活跃时间的13%。其中,9%用于清理AI生成的代码,4%纯属等待响应。
想象一个场景:开发者描述一个复杂功能,AI输出需反复迭代。手动编码可能只需5分钟,但提示交互延长到10分钟以上。
在大型项目中,提示需包含上下文细节,这进一步放大开销。AI响应虽快,但不总是准确,导致循环调整。
3.2 低代码采纳率与审查成本
AI生成的代码采纳率仅44%。其余56%需修改或丢弃。这意味着大量时间用于审查和修正。
原因在于AI忽略项目特异性,如风格指南或隐含依赖。资深开发者对代码库的深度知识远超AI的上下文窗口(通常限于数千token)。
例如,在一个110万行代码的项目中,AI可能修改错误文件,导致连锁错误。审查这些输出成为瓶颈。
以下表格总结代码处理分布:
此表突出审查负担。
3.3 项目复杂性与AI的局限
大型项目平均110万行代码,充满历史依赖和隐含规则。AI难以把握这些,导致输出偏差。
开发者经验丰富,能直观导航代码库。AI则依赖有限输入,常忽略边缘案例。这在bug修复中尤为明显:AI可能修复表面问题,却引入新漏洞。
此外,AI不擅长维护一致性,如遵守DRY原则(不要重复自己)。这增加技术债务,长期看放大维护成本。
3.4 碎片化工作流与心理因素
使用AI时,工作流碎片化:提示、等待、审查、修正。开发者频繁切换,节奏被打乱。
主观上,这感觉“高效”,因为AI提供即时反馈。但客观上,产出放缓。过度自信加剧问题:即使进度落后,开发者仍坚持使用AI,形成陷阱。
报告引用行为心理学,解释这一偏差源于锚定效应:初始预期扭曲了后续判断。
3.5 质量隐患的延伸影响
AI代码往往增加“代码更改率”——短期内被删除的比例。这破坏项目稳定性。
例如,AI生成的冗余代码违反DRY,导致后期重构困难。GitClear的研究支持此点,显示AI引入的技术债务可达传统方法的1.5倍。
这些因素综合,导致19%的效率损失。理解它们有助于开发者规避陷阱。
四、对行业评估体系的反思与启示
这项研究不止于数据,它引发了对AI评估范式的深刻反思。传统方法已显疲态。
4.1 基准测试的局限性
业界常用基准如SWE-Bench,测试AI在小型、理想化任务中的表现。这些测试简化复杂性,高估实际效能。
真实项目涉及协作、遗留代码和不确定性。基准忽略这些,无法预测部署影响。METR呼吁转向现场实测,如本研究般模拟真实环境。
4.2 主观反馈的误导性
开发者主观认为AI提升20%,但数据反驳。这偏差源于即时满足:AI快速生成代码,掩盖了整体延误。
启示是:评估需依赖客观指标,如时间日志和产出质量,而非问卷。管理者应警惕这一陷阱,避免基于感觉决策。
4.3 更广泛的行业启示
这一反思延伸到AI在其他领域的应用。如在软件工程外,AI写作工具也存在类似偏差:用户感觉高效,但输出质量需大量编辑。
行业需构建新框架:结合实测数据、长期跟踪和跨学科分析。这将推动AI从炒作走向实用。
五、适用性与未来建议
%20拷贝-iulv.jpg)
AI工具并非一无是处。其价值取决于上下文。
5.1 AI工具的潜力与局限
对于新手或原型开发,AI可加速学习和迭代。在标准化任务中,它节省时间。
但在复杂、大型项目中,AI局限凸显。资深开发者经验无可替代,AI可能成为累赘。
5.2 警惕认知偏差与合理应用
开发者应自我审视:追踪实际时间,而非依赖感觉。管理者可引入A/B测试,量化AI影响。
根据项目类型选择:小型任务用AI,核心开发靠人工。
5.3 优化AI的未来路径
要提升AI适应性,需扩大上下文窗口、整合项目知识图谱,并训练于真实数据集。
未来研究应扩大样本,涵盖更多模型如GPT-4o。社区反馈显示,样本量虽小,但发现一致性强。
争议存在:有些人质疑测量忽略后续节省。但整体共识是,AI需谨慎整合。
总结
METR的研究如警钟,提醒AI编程工具在资深开发者手中的双刃剑效应。效率下降19%、认知偏差的揭示,呼吁从基准转向真实评估。行业应理性拥抱AI,优化其局限,推动可持续创新。最终,技术进步需服务于人类智慧,而非取代它。
📢💻 【省心锐评】
METR报告戳破AI效率泡沫,资深开发者别迷信工具,真实项目中经验仍是王道,理性评估方能避坑。

评论