.png)


【摘要】微软与中科院大学联合推出的BitNet v2,通过原生4位激活量化与创新的H-BitLinear模块,实现了大语言模型“极简主义”突破,兼顾高效、低能耗与卓越性能,为AI模型在边缘设备和绿色计算领域的普及奠定了坚实基础。
引言
人工智能的浪潮席卷全球,尤其是大语言模型(LLM)的崛起,推动了智能对话、自动写作、知识检索等众多应用的飞速发展。然而,随着模型规模的不断膨胀,AI系统的“臃肿”问题日益突出。庞大的参数量和高精度的数值表示,使得这些模型在实际部署时面临着巨大的计算和存储压力。如何让AI模型“减重不减智”,在有限的硬件资源下依然保持卓越的智能表现,成为业界亟需解决的核心难题。
2025年6月,微软研究院与中国科学院大学联合发布的BitNet v2,为这一难题带来了革命性的解决方案。该团队通过原生4位激活量化技术和创新的H-BitLinear模块,成功将大模型的“体重”大幅削减,同时几乎不损失其“智商”。这一突破不仅极大提升了AI模型的部署灵活性和能效比,也为AI在边缘设备、移动终端等资源受限场景的普及应用打开了新局面。本文将从技术原理、创新点、实验结果、实际应用、局限与展望等多个维度,深度剖析BitNet v2的技术内核与行业意义,力求为读者呈现一场关于AI“极简主义”革命的全景式解读。
一、AI大模型的“臃肿”困境与极简主义诉求
%20拷贝.jpg)
1.1 大模型的“臃肿”本质
1.1.1 参数规模的爆炸式增长
近年来,AI大模型的参数规模呈现指数级增长。以GPT系列为例,从最初的1.17亿参数到GPT-3的1750亿参数,模型的“体重”不断攀升。参数量的增加带来了更强的表达能力和泛化能力,但也带来了巨大的计算和存储负担。
1.1.2 高精度数值表示的资源消耗
主流大模型通常采用32位或16位浮点数进行权重和激活的存储与计算。即使后续有8位量化等优化手段,模型整体的内存占用和推理能耗依然居高不下。对于边缘设备和移动终端而言,这种高精度、高资源消耗的模型几乎无法直接部署。
1.1.3 实际应用中的瓶颈
移动端部署难:智能手机、平板等设备的内存和算力有限,难以承载大模型的运行需求。
服务器并发压力大:在云端场景下,单台服务器需同时服务大量用户,高资源消耗导致响应延迟和能耗飙升。
能耗与碳排放问题:大模型的高能耗不仅增加了运营成本,也对绿色计算和碳中和目标构成挑战。
1.2 “极简主义”AI的技术诉求
在上述背景下,业界对“极简主义”AI的需求愈发迫切。所谓“极简主义”,并非简单地削减模型规模或精度,而是在保证核心智能能力的前提下,最大限度地降低模型的计算和存储资源消耗,实现“减重不减智”。
1.2.1 量化技术的兴起
量化(Quantization)技术通过降低模型参数和激活的数值精度,有效压缩模型体积、提升推理效率。主流量化方法包括:
权重量化:将权重从32位/16位浮点数压缩为8位、4位甚至更低比特的整数或三元值。
激活量化:对中间激活值进行低比特表示,进一步降低内存和带宽需求。
1.2.2 低比特量化的挑战
尽管量化技术带来了显著的资源节约,但低比特量化(如4位、3位)往往会导致模型性能大幅下降,尤其是在激活量化环节。如何在极低比特下保持模型的“智商”,成为量化技术的最大挑战。
二、BitNet v2:AI极简主义的技术范式
2.1 BitNet v2的技术架构
BitNet v2是微软团队在BitNet b1.58基础上的重大升级。其核心创新在于:
原生4位激活量化:将模型激活的数值精度从8位进一步降至4位,每个激活值仅有16种可能,极大压缩了模型的内存和带宽需求。
极低比特权重:权重采用1.58位三元值({-1, 0, 1}),在保证表达能力的同时,实现极致压缩。
H-BitLinear模块:通过Hadamard变换(哈达玛变换)平滑激活分布,解决低比特量化下的异常值问题。
两阶段训练策略:先用8位激活训练至95%,再切换到4位激活完成剩余训练,确保训练稳定性和最终性能。
2.1.1 技术架构流程图
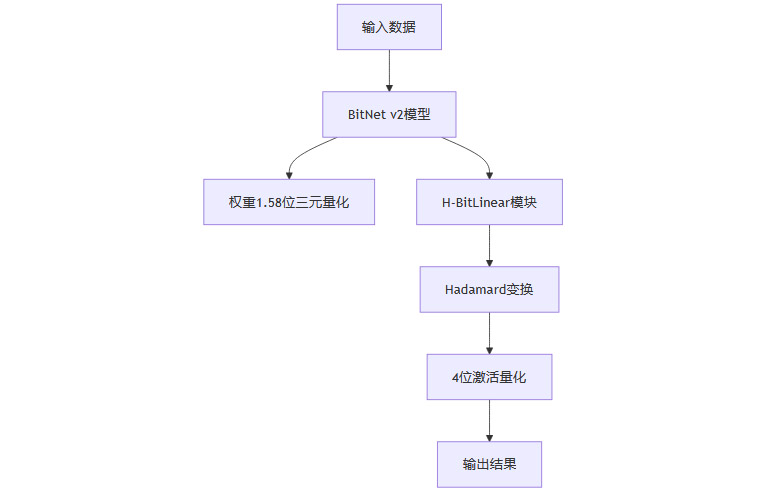
2.2 原生4位激活量化的突破
2.2.1 传统量化的局限
以往的量化方法多集中于权重量化,激活量化则因其分布复杂、异常值多而难以进一步压缩。8位激活量化已是主流,4位激活量化则面临严重的信息损失和性能下降。
2.2.2 BitNet v2的创新实现
BitNet v2通过H-BitLinear模块和Hadamard变换,有效平滑了激活分布,使得4位激活量化成为可能。具体而言:
Hadamard变换:将激活分布“搅拌”成更接近高斯分布的平滑形态,减少异常通道。
H-BitLinear模块:在注意力机制输出和前馈网络下投影层集成Hadamard变换,针对激活分布最不平滑的关键位置进行优化。
2.2.3 技术原理表格
2.3 H-BitLinear与Hadamard变换的关键作用
2.3.1 激活分布中的异常值问题
在大模型的实际运行中,激活分布往往存在大量异常值(outlier),尤其是在注意力机制输出和前馈网络下投影层。这些异常值如同河流中的巨石,极易导致低比特量化下的信息损失和模型性能下降。
2.3.2 Hadamard变换的数学原理
Hadamard变换是一种基于正交矩阵的高效变换,能够将原本尖锐不规则的数值分布“搅拌”成更为平滑、接近正态分布的形态。其计算复杂度为O(nlogn),适合硬件加速。
2.3.3 H-BitLinear模块的集成方式
H-BitLinear模块将Hadamard变换集成到模型的关键位置,具体包括:
注意力机制的输出投影层
前馈网络的下投影层
这种集成方式如同在高速公路的关键路段安装减速带,确保“车流”平稳,极大提升了4位激活量化的可行性和鲁棒性。
2.3.4 消融实验验证
消融实验表明,去掉Hadamard变换后,模型在4位激活训练时会出现发散现象,性能大幅下降。这一结果充分验证了H-BitLinear模块的关键作用。
三、BitNet v2的训练策略与实验验证
%20拷贝.jpg)
3.1 两阶段训练策略
3.1.1 渐进式训练法
BitNet v2采用两阶段训练策略:
第一阶段:使用8位激活训练模型至95%,确保模型参数和结构的稳定性。
第二阶段:切换到4位激活,完成剩余5%的训练,实现模型的最终量化和性能优化。
这种渐进式训练法类似于“浅水区到深水区”的学习过程,既保证了训练的稳定性,也提升了最终模型的性能。
3.1.2 训练流程表
3.2 大规模实验验证
3.2.1 数据集与模型规模
数据集:RedPajama等大规模数据集,包含1000亿训练样本,相当于让模型“阅读”了几百万本书籍。
模型规模:涵盖4亿、13亿、30亿、70亿等不同参数规模,全面测试从小型到大型模型的适用性。
3.2.2 性能测试任务
常识推理
阅读理解
逻辑推理
注意力机制键值缓存压缩
3.2.3 实验结果亮点
4位激活的BitNet v2在大多数任务上与8位版本表现几乎持平,部分任务甚至略有提升。
在困惑度(perplexity)指标上,BitNet v2显著优于主流后训练量化方法(如SpinQuant、QuaRot)。
注意力键值缓存进一步压缩至3位时,模型性能依然稳定,显示出极强的鲁棒性。
3.2.4 性能对比表
3.3 细致的消融实验与鲁棒性分析
3.3.1 消融实验设计
为了深入理解各技术组件对BitNet v2性能的贡献,研究团队设计了多组消融实验,分别去除或替换关键模块,观察模型在4位激活量化下的表现。主要实验包括:
去除H-BitLinear模块,仅用传统线性层
不使用Hadamard变换,仅做普通量化
采用单阶段直接4位激活训练
3.3.2 消融实验结果
实验结果显示:
去除H-BitLinear模块:模型在4位激活下训练发散,无法收敛,性能大幅下降。
不使用Hadamard变换:激活分布异常值增多,量化误差显著,模型困惑度急剧上升。
单阶段直接4位激活训练:训练过程极不稳定,最终性能远低于两阶段训练法。
这些结果充分证明了H-BitLinear模块和两阶段训练策略在实现极低比特量化中的不可替代性。
3.3.3 鲁棒性与泛化能力
BitNet v2在不同任务、不同数据集、不同模型规模下均表现出极强的鲁棒性和泛化能力。尤其是在注意力机制键值缓存进一步压缩至3位时,模型依然保持稳定输出,显示出对极端低精度的适应性。
四、BitNet v2的实际应用价值与行业意义
%20拷贝.jpg)
4.1 硬件适配性与推理效率提升
4.1.1 新一代AI硬件的低精度计算支持
随着AI芯片和GPU架构的不断演进,4位甚至更低比特的原生计算能力已成为主流。例如,NVIDIA GB200等新一代GPU专为低精度AI计算优化,能够在4位量化模型上实现更高的吞吐量和能效比。
4.1.2 BitNet v2的硬件友好性
BitNet v2的4位激活量化与极低比特权重设计,能够充分发挥现代AI硬件的低精度计算优势。其在批量推理场景下,显著提升了硬件利用率,降低了推理延迟和能耗。
4.1.3 推理效率对比表
4.2 边缘设备与移动终端的AI普及
4.2.1 资源受限场景的需求
智能手机、物联网设备、自动驾驶汽车等边缘设备,普遍面临内存、算力、电池续航等多重限制。传统大模型难以直接部署,成为AI普及的最大障碍。
4.2.2 BitNet v2的边缘友好性
BitNet v2通过极致量化,大幅降低了模型的内存和算力需求,使得高性能AI模型能够在边缘设备上高效运行。用户将体验到:
更快的AI应用启动速度
更低的响应延迟
更长的电池续航时间
4.2.3 应用场景举例
智能手机:本地语音助手、实时翻译、图像识别等AI功能无需云端依赖
物联网终端:智能家居、安防监控、工业自动化等场景下的本地智能决策
自动驾驶:车载AI模型实时感知与决策,提升安全性与可靠性
4.3 绿色计算与碳减排贡献
4.3.1 AI能耗的行业挑战
AI大模型的高能耗已成为行业关注的焦点。数据中心的电力消耗和碳排放压力日益加剧,绿色计算成为AI发展的重要方向。
4.3.2 BitNet v2的环保价值
通过大幅降低推理计算需求,BitNet v2显著减少了AI模型的运行能耗。以大规模部署为例,4位量化模型可将能耗降低数倍,助力AI行业实现碳减排目标。
4.3.3 绿色计算效益表
4.4 用户体验的全面提升
4.4.1 响应速度与流畅性
BitNet v2的高效推理能力,使得AI应用在终端设备上响应更快、体验更流畅。用户无需等待云端响应,AI助手、智能推荐等功能可实现本地实时处理。
4.4.2 电池续航与便携性
低能耗设计延长了设备的电池续航时间,提升了移动设备的便携性和实用性。对于长时间运行AI应用的场景,BitNet v2带来的续航提升尤为显著。
五、局限性与未来展望
5.1 当前局限性分析
5.1.1 对极高精度场景的适用性
尽管BitNet v2在大多数任务中表现优异,但在对精度极端敏感的应用(如医疗诊断、金融风控等)下,4位量化可能带来微小但不可忽略的性能损失。这类场景对模型输出的准确性有极高要求,任何量化误差都可能影响最终决策。
5.1.2 小批量推理的计算开销
Hadamard变换虽然计算复杂度低,但在小批量推理时,其额外计算开销相对更为突出,可能影响部分实时性要求极高的应用。
5.1.3 架构适用范围
目前BitNet v2主要针对BitNet架构和1.58位权重的特殊设计,直接迁移到传统全精度模型或其他神经网络架构时,效果尚需进一步验证和优化。
5.2 未来发展方向
5.2.1 更低比特量化的探索
研究团队正在积极探索3位、2位激活量化的可行性,力求在更低精度下依然保持模型性能。这将进一步推动AI模型的极致高效化。
5.2.2 多架构适配与通用化
未来,BitNet v2的核心技术有望推广到更多神经网络架构,包括卷积神经网络(CNN)、Transformer变体等,提升其通用性和适用范围。
5.2.3 硬件协同优化
随着AI芯片对超低精度计算的支持不断完善,BitNet v2等极简主义AI技术将与硬件深度协同,释放更大潜力。软硬件一体化优化将成为AI高效化的主流趋势。
5.2.4 AI普及与社会影响
BitNet v2的成功不仅是技术突破,更为AI的普及应用奠定了基础。随着模型高效化、能耗降低,AI将更广泛地走进千家万户,推动智能社会的到来。
六、方法论启示与行业影响
6.1 深入理解模型机制的重要性
BitNet v2的突破,源于对大模型内部激活分布、异常值机制的深入剖析。通过精确定位瓶颈,创新性地引入Hadamard变换,团队实现了低比特量化的质的飞跃。这一过程彰显了“知其然,更知其所以然”的研究精神。
6.2 极简主义AI的行业趋势
AI技术正从“堆参数、拼算力”的粗放式发展,转向“高效、绿色、普惠”的极简主义范式。BitNet v2的成功,预示着未来AI模型将在效率、能耗、性能之间实现更优平衡,推动AI技术的可持续发展。
6.3 对后续研究的启发
BitNet v2为业界提供了宝贵的方法论启示:
深入挖掘模型内部规律,寻找优化突破口
软硬件协同创新,释放AI潜能
关注AI技术的社会价值与普惠性
结论
微软与中科院大学联合推出的BitNet v2,以原生4位激活量化、极低比特权重、H-BitLinear模块和两阶段训练策略为核心,实现了大语言模型“极简主义”的重大突破。该技术不仅大幅降低了模型的内存和计算资源消耗,提升了推理效率和能效比,还为AI在边缘设备、移动终端、绿色计算等领域的普及应用提供了坚实基础。尽管在极高精度场景和小批量推理等方面仍有局限,但BitNet v2无疑为AI模型的高效化、普及化指明了方向。随着相关技术和硬件的持续进步,BitNet v2及其后续创新有望引领AI模型向更高效、更智能、更普惠的未来迈进。
📢💻 【省心锐评】
“BitNet v2的价值超越技术本身:它用4比特的枷锁练就AI的芭蕾,当算力霸权被瓦解,普惠智能才真正触手可及。”

评论