.png)


【摘要】本文深度剖析浙江大学与阿里巴巴通义实验室联合提出的TimeHC-RL方法,探讨其如何通过时序感知与分层认知强化学习,显著提升大语言模型的社交智能。文章涵盖社交智能的独特挑战、技术创新、实验验证、未来展望等多个维度,结合丰富案例与技术细节,全面展现AI理解人情世故的前沿进展。
引言
在人工智能的浪潮中,大语言模型(LLMs)已然成为推动科技进步的中坚力量。它们在数学、编程、逻辑推理等领域屡创佳绩,甚至在某些场景下超越了人类专家。然而,令人困惑的是,这些“聪明绝顶”的AI,在面对人类日常生活中最常见的社交场景时,却常常显得“呆板”、“不解风情”——它们能解高等数学,却未必能读懂朋友的一个眼神、理解一场聚会的微妙气氛。
为什么AI在社交智能上如此“掉链子”?人类的社交世界到底有多复杂?我们又该如何让AI真正“懂人情世故”?浙江大学与阿里巴巴通义实验室的联合研究团队,针对这一难题,提出了创新性的TimeHC-RL方法,试图让大模型不仅“聪明”,更“通人情”。本文将带你深入这项前沿研究的技术细节与思想火花,探讨AI社交智能的挑战、突破与未来。
一、🌏 社交智能的独特挑战:AI为何难以“通人情”?
%20拷贝-jvql.jpg)
1.1 社交智能与数学智能的本质区别
1.1.1 认知模式的多样性
人类的社交智能,远非单一的逻辑推理所能涵盖。我们在日常生活中,既有“秒懂”朋友情绪的直觉反应,也有对复杂人际关系的深度推理。心理学家丹尼尔·卡尼曼提出的“系统1”和“系统2”理论,恰好揭示了人类思维的两大模式:
系统1(直觉思维):快速、自动、无需刻意思考。例如,看到朋友皱眉,立刻意识到他心情不好。
系统2(深度推理):缓慢、费力、需要逻辑分析。例如,分析同事间的微妙关系,推断背后动机。
而在社交场景中,往往还需要一种“表层思考”——既不完全依赖直觉,也不必深度推理,而是对情境做出快速、适度的分析。
1.1.2 社交事件的时序性
社交世界的另一个显著特征,是事件的时间顺序极为重要。比如:
“小明先发了脾气,小红才哭了。”
“老板先表扬了小李,大家才鼓掌。”
如果打乱事件顺序,整个社交情境的意义就会发生根本变化。人类天然地理解这种时序关系,但大模型却常常忽略这一点。
1.1.3 复杂的情境与隐含规则
社交场景中充满了隐含规则和未明说的线索。比如,朋友的沉默可能意味着不满,也可能只是累了。人类会结合场合、关系、过往经验做出判断,而AI往往只看到表面文本,难以把握深层含义。
1.2 现有大模型的局限性
1.2.1 “一刀切”的推理方式
以DeepSeek-R1为例,研究团队发现其在社交情境理解时,无论问题复杂与否,都采用系统2的深度推理。这种“杀鸡用牛刀”的方式,既浪费计算资源,也无法灵活应对多样化的社交问题。
1.2.2 计算资源消耗大
在ToMBench等社交智能测试中,DeepSeek-R1虽然准确率高达78.4%,但推理过程冗长,消耗大量算力。相比之下,人类往往能用极少的“脑力”快速做出判断。
1.2.3 泛化能力有限
现有模型在未见过的社交场景、不同推理深度下,表现大幅下降。这说明它们“死记硬背”能力强,但“举一反三”能力弱,难以适应真实世界的复杂多变。
1.3 社交智能的三大核心挑战
二、🚀 TimeHC-RL:让AI“通人情”的创新方法
2.1 研究背景与目标
浙江大学与阿里巴巴通义实验室的研究团队,正是基于上述挑战,提出了“时序感知分层认知强化学习”(TimeHC-RL)方法。其核心目标是:
让大模型像人类一样,灵活切换不同认知模式;
让模型真正理解社交事件的时间顺序和因果关系;
显著提升模型在社交智能任务上的表现和泛化能力。
2.2 数据集构建:多维度社交“课程表”
2.2.1 数据来源与类型
研究团队精心挑选并整合了8个具有代表性的数据集,覆盖从基础情感识别到高阶人际推理的多种社交场景:
2.2.2 数据集多样性与难度分级
这些数据集不仅覆盖不同难度,还包含多种社交情境,如:
情绪识别
行为动机推断
多人关系网络分析
事件因果链推理
2.3 TimeHC-RL方法核心机制
2.3.1 分层认知框架
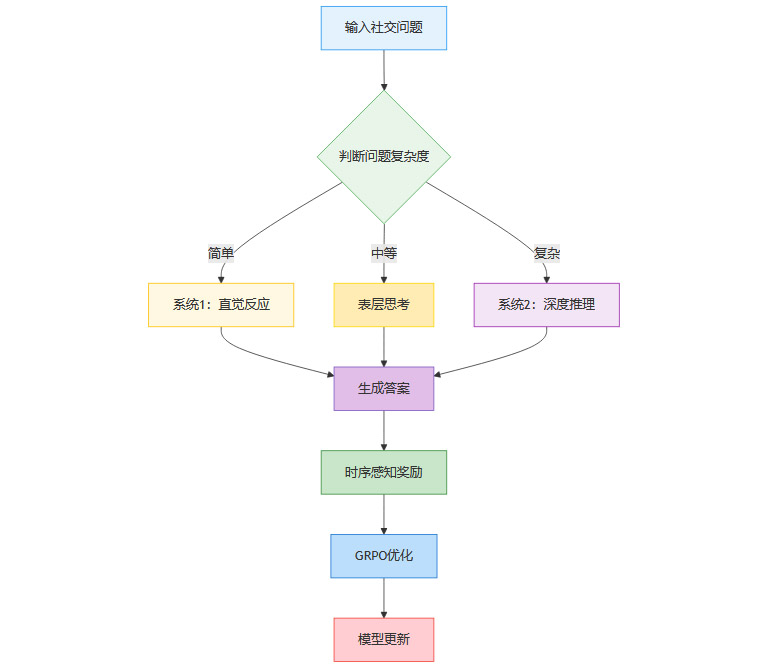
TimeHC-RL的第一个创新,是为大模型设计了“分层认知”机制,让其能像人类一样,根据问题复杂度灵活选择思考方式:
系统1(直觉反应):适用于简单情境,直接给出答案。
表层思考:适用于中等复杂度情境,先做简要分析再答题。
系统2(深度推理):适用于复杂人际推理,详细推理过程后给出答案。
这种机制不仅提升了效率,也让模型的“社交智商”更贴近人类。
2.3.2 时序感知奖励机制
第二大创新,是引入“时序感知奖励”。具体做法是:
对同一社交问题,分别用正确和打乱顺序的事件输入模型;
只有模型在正确顺序下表现更好,才获得额外奖励;
强化模型对事件时间线的敏感度,避免“只看表面”。
2.3.3 强化学习算法:GRPO
TimeHC-RL采用了Group Relative Policy Optimization(GRPO)算法。与传统RL不同,GRPO不是单独评价每个答案的好坏,而是通过同组内不同答案的相对优劣来优化策略。这种“组内竞争”机制,能更高效地引导模型学习复杂社交规则。
2.3.4 方法流程图
2.4 代码实现要点
系统1:
最终答案表层思考:
社交情境理解 + 最终答案系统2:
思考过程 + 最终答案
这种分层输出格式,既提升了模型效率,也让其回答更贴近人类思维习惯。
三、🔬 实验验证:AI社交智能的质变飞跃
%20拷贝-oehl.jpg)
3.1 实验设计与评估指标
3.1.1 训练与测试设置
基础模型:7B参数大语言模型
训练方法:TimeHC-RL、系统2 RL、系统1 RL、SFT(监督微调)、长思考SFT
评估维度:领域内(见过的数据集)、领域外(未见过的数据集)、推理深度外推
3.1.2 主要评估指标
综合准确率
推理深度外推能力
泛化能力
计算资源消耗
3.2 主要实验结果
3.2.1 领域内表现
3.2.2 领域外泛化
3.2.3 推理深度外推
TimeHC-RL在三阶、四阶推理任务上,准确率显著高于SFT和系统2 RL,展现出强大的“举一反三”能力。
3.2.4 计算资源效率
TimeHC-RL训练后的7B模型,能以更低算力达到与更大模型相当的社交智能水平,极大提升了性价比。
3.3 关键洞见与对比分析
3.3.1 SFT vs RL
SFT方法在领域外泛化和高阶推理上表现不佳,甚至有时“越学越笨”;
RL方法(尤其是TimeHC-RL)则能有效提升泛化与外推能力。
3.3.2 分层认知的必要性
系统2 RL适合高阶推理,系统1 RL适合情境认知;
TimeHC-RL通过分层机制,兼顾两者优势,全面提升社交智能。
3.3.3 时序感知的独特价值
仅靠“预算强制”让模型多思考,并不能提升社交情境认知;
必须在训练中引入时序奖励,才能让模型真正理解事件先后关系。
3.3.4 方法对比表
四、🌱 未来展望:迈向更“人性化”的AI社交智能
%20拷贝.jpg)
4.1 行为智能的下一个前沿
TimeHC-RL已在情境智能和认知智能上取得突破,但“行为智能”——即AI如何在社交互动中做出恰当行为——仍是未解之谜。未来研究可探索:
AI如何根据社交情境,选择合适的言语、动作、表情;
如何让AI在多轮对话、群体互动中展现“情商”;
如何让AI在跨文化、跨语境的社交场景中自如应对。
4.2 可扩展的社交情境框架
构建更丰富、多样的社交情境数据集,让AI“见多识广”;
引入真实世界的社交互动数据,提升模型的现实适应性;
探索多模态(文本、语音、图像)社交智能,打破单一文本限制。
4.3 不同规模模型的探索
小模型通过TimeHC-RL可“以小博大”,但大模型是否能进一步突破社交智能极限?
不同规模模型在社交智能上的表现差异,或许能揭示AI认知的本质规律。
4.4 应用前景展望
智能助手:不仅能答题,更能理解用户情绪、主动安慰、适时建议;
虚拟角色:在游戏、影视、教育等场景中,展现真实、复杂的社交行为;
心理健康:AI能识别用户情绪波动,提供个性化心理支持;
教育辅导:根据学生情绪和社交状态,调整教学策略,提升学习体验。
结论
TimeHC-RL的提出,标志着AI社交智能研究迈入新阶段。通过时序感知与分层认知的巧妙结合,研究团队不仅让大模型“更聪明”,更让它们“更懂人情”。这一方法的成功,既是技术创新的结晶,也是对人类社交智慧的深刻致敬。
未来,随着行为智能、多模态社交智能等方向的深入探索,我们有理由相信,AI终将成为真正“通人情、懂世故”的伙伴,助力人类社会迈向更加智能与和谐的明天。
📢💻 【省心锐评】
“社交智能是AGI最后一公里,TimeHC-RL用分层认知拆解人情世故密码。但若止步于‘理解’而缺‘行为输出’,仍是纸上谈兵。”

评论