.png)

【摘要】本文拆解了医疗AI从模型到产品的五维闭环评估体系,强调超越AUC,聚焦临床效用、安全伦理与工作流整合,旨在构建真正可用、可信的生产级系统。
引言
在医疗AI领域,我们常看到顶刊论文中展示的近乎完美的AUC曲线。这些成果无疑推动了技术边界的拓展。但在真实的临床环境中,高AUC模型却常常遭遇水土不服。一线医生面临的困惑真实而尖锐,AI工具可能干扰诊断节奏,缺乏决策依据,甚至异化为新的工作负担。
这揭示了一个核心问题,一个高分模型与一个成功、可靠、能被临床广泛接受的医疗AI产品之间,存在着巨大的鸿沟。跨越这道鸿沟,需要我们告别单一指标崇拜,转向一个多维度、全周期的闭环评估体系。这个体系必须系统性地回答三个根本问题。
模型是否准确可靠?
模型是否能带来临床获益?
模型是否安全且值得信赖?
本文将从实战出发,系统性拆解构建这一体系的五大核心维度。目标是将停留在“演示级”的模型,真正锻造成坚实的“生产级”产品。
🌀 一、算法性能与可靠性,超越AUC的稳健基石
%20拷贝-clen.jpg)
算法性能是评估的起点,但绝非终点。我们必须建立一套超越传统准确率的指标集,追求模型在复杂临床数据面前的稳健性与诚实度。
1.1 指标选择,从AUC-ROC到AUC-PR优先
在医疗数据中,样本不平衡是常态,尤其是在罕见病筛查或癌症早筛等场景,阳性样本占比极低。
1.1.1 AUC-ROC的局限性
AUC-ROC(受试者工作特征曲线下面积)衡量的是模型在所有排序对中,将随机抽取的正样本排在随机抽取的负样本前面的概率。在负样本远多于正样本的情况下,模型即便对正样本识别能力平平,只要能准确识别海量的负样本,其AUC-ROC值依然会显得很高。这种“虚高”会掩盖模型在关键少数(患者)上的性能缺陷,导致临床误用。
1.1.2 AUC-PR的“诚实度”
AUC-PR(精确率-召回率曲线下面积)则更适合不平衡场景。它聚焦于正样本的识别质量,直接关联两个临床最关心的问题。
召回率 (Recall),所有真患者中,有多少被模型找出来了?(查全能力)
精确率 (Precision),所有被模型判断为患者的,有多少是真的?(判准能力)
AUC-PR不受海量负样本的干扰,能更真实地反映模型在“不漏诊”和“少误诊”之间的平衡能力。在致命疾病早筛中,漏诊的代价极高,我们通常会优先保证高召回率,此时AUC-PR的变化比AUC-ROC更能敏锐地反映模型性能的优劣。
下面是一个简明的选择对比。
1.2 校准度,让模型的概率输出值得信赖
模型输出的“95%恶性概率”这个数字本身是否可信?这就是校准度 (Calibration) 要解决的问题。一个高AUC但校准度差的模型,其概率输出对临床决策毫无意义,甚至会产生误导。
1.2.1 期望校准误差 (ECE)
ECE (Expected Calibration Error) 是量化校准度的核心指标。它将模型的预测概率分箱(如0-10%, 10-20%, ...),计算每个箱内预测概率的平均值与真实阳性率之间的加权平均差。ECE越接近0,说明模型的概率输出越接近真实世界。例如,理邦心电AI通过超百万病例的训练与验证,将ECE误差控制在5%以内,这使其房颤预警的概率值具备了很高的临床参考价值。
1.2.2 可靠性图 (Reliability Diagram)
可靠性图是ECE的可视化呈现。它以模型预测概率为横轴,以真实阳性率为纵轴。一个完美校准的模型,其可靠性图上的点会紧密贴合y=x这条对角线。通过观察图形,我们可以直观地判断模型在哪些概率区间存在“过度自信”或“自信不足”的问题。
1.3 鲁棒性与泛化,模型走出实验室的通行证
一个在单一数据集上表现优异的模型,必须经过严格的外部验证,才能证明其在真实世界中的价值。
多中心验证,数据必须来自不同的医院或医疗机构,以检验模型对不同地域、不同诊疗习惯的适应性。
跨设备验证,数据应覆盖不同品牌、不同型号的医疗设备(如CT、MRI),确保模型不会因设备差异导致性能下降。
跨人群验证,数据需包含不同年龄、性别、种族的人群,避免模型产生偏见。
谷歌的糖尿病视网膜病变(DR)筛查系统在泰国遭遇的“水土不服”,就是一个深刻教训。由于训练数据与实际应用场景的图像质量、人群特征存在差异,导致模型性能远未达到预期。这充分说明,前瞻性的、多维度的真实世界验证是模型开发不可或缺的一环。
1.4 不确定性量化,模型的“自知之明”
最安全的AI,是知道自己“不知道”的AI。不确定性量化 (Uncertainty Quantification) 旨在让模型在面对其知识边界之外的、模糊的或低质量的输入时,能够给出一个“我不确定”的信号。
1.4.1 不确定性的分解
不确定性通常分为两类。
偶然不确定性 (Aleatoric Uncertainty),源于数据本身的噪声和模糊性,是固有存在的,无法通过更多数据消除。
认知不确定性 (Epistemic Uncertainty),源于模型知识的局限性,可以通过增加训练数据或改进模型结构来降低。
1.4.2 设定“拒识”阈值
在临床应用中,我们可以计算模型的总不确定性,并设定一个安全阈值。当不确定性超过该阈值时,系统应触发“拒识” (Refuse to Predict) 机制,自动将该病例标记为高风险,并提示必须由人类专家进行复核。联影智能的“元智”大模型已将此机制作为内置功能,在多中心环境下实现高AUC的同时,有效防控了高风险场景下的误判,这是保障临床安全的最后一道技术防线。
🌀 二、临床效用与效率,衡量AI的真实世界价值
一个技术上完美的模型,如果不能为临床工作带来实际增益,甚至成为医生的负担,那么它就是失败的。评估AI的真实世界价值,必须深入临床场景,量化其效用与效率。
2.1 真实世界研究 (RWS),效用评估的“金标准”
RWS (Real-World Study) 是检验AI临床效用的核心方法。通过设计严谨的研究方案,我们可以客观地衡量AI的引入对诊疗过程的实际影响。
2.1.1 研究设计
常见的设计是前瞻性或回顾性的对照研究,将医生随机分为两组。
对照组,医生遵循传统工作流程,不使用AI辅助。
实验组,医生使用集成了AI工具的系统进行工作。
数据集应能代表目标临床场景的真实病例分布,包含不同疾病类型、严重程度、罕见病以及易混淆的阴性病例。
2.1.2 核心评估指标
评估指标必须是多维度的,覆盖效用和效率两个层面。
例如,商汤SenseCare平台在瑞金医院的应用研究显示,它将医生活检诊断时长从平均1分钟缩短至10秒,年节约工时超万小时。新华医院与AI全科医生的协作,则将基层诊断准确率提升了20%。这些都是AI真实世界价值的有力证明。
2.2 临床推理力评测,让AI真正“理解”病程
临床诊断并非简单的关键词匹配,它高度依赖时序和因果逻辑。一个只会“看图识字”的AI,无法成为真正的诊断助手。
2.2.1 “时序最小对立体”测试集
“持续一周的钝痛,今天突然变刺痛”与“持续一周的刺痛”,在临床上指向的诊断路径截然不同。传统的评测集很难捕捉这种细微但关键的差异。
我们可以构建**“时序最小对立体” (Temporal Minimal Pairs)** 测试集。即构造一对或多对病例,这些病例在核心症状关键词上完全相同,仅在时间描述词(如“持续”、“突然”、“加重”)或事件顺序上存在微小差异。通过检验模型在这些病例对上的诊断结果是否符合临床逻辑,可以精准评估其对病程动态变化的理解能力。
2.2.2 “症状因果图”匹配
对于“腹泻、呕吐后出现口干、乏力”的病例,医生能清晰地构建出“腹泻/呕吐(因) -> 脱水 -> 口干/乏力(果)”的因果链。而模型可能仅将这些症状视为一堆独立的关键词。
评测时,我们可以让标注专家为典型病例构建**“症状因果图”。同时,利用思维链(Chain of Thought, CoT)等技术,让模型不仅给出诊断,还要输出其推理路径。最后,通过图论算法计算模型推理路径与专家因果图的图相似度**,从而量化评估AI的临床逻辑一致性。
🌀 三、安全、伦理与可信赖性,构建技术与流程的安全网
%20拷贝-zssj.jpg)
在医疗这个高风险领域,信任是AI产品被接受的前提。构建信任,需要系统性的风险管理和贯穿始终的合规意识。
3.1 深度可解释性 (XAI),打开模型的“黑箱”
解释性不应止于在影像上叠加一张模糊的“热力图”。一个有临床价值的XAI,必须满足以下标准。
忠实性 (Fidelity),解释必须真实反映模型的内部决策逻辑,而非事后生成的“合理化”说辞。
一致性 (Consistency),对相似的输入,模型应产生相似的解释。
临床意义 (Clinical Meaningfulness),解释应能对应到具体的解剖结构或病理特征,为医生的判断提供有效信息。
商汤的PathOrchestra病理分析平台,通过最小对抗样本测试等方法,确保其关键异常热区标注具备高度的临床对齐性,这是XAI从技术走向实用的典范。
3.2 失效模式与效应分析 (FMEA),前瞻性的风险管理
FMEA (Failure Mode and Effects Analysis) 是一种系统性的、前瞻性的风险管理方法,旨在“预见”并“预防”模型在各种情况下的潜在失败。
3.2.1 FMEA的实施流程
识别潜在失败模式,组织跨职能团队(算法、产品、临床、法规),从模型本身、人机交互、技术环境等多个层面,头脑风暴所有可能的失败场景。
量化风险,对每个失败模式,从三个维度进行打分(1-10分)。
严重性 (S - Severity),该失败发生后对患者或临床工作造成的危害程度。
可能性 (O - Occurrence),该失败发生的频率或概率。
可检测性 (D - Detection),该失败在发生前或发生时被检测到的难易程度。
计算风险优先级数 (RPN),RPN = S × O × D。RPN值越高,说明该风险项的优先级越高。
制定并实施缓解措施,针对高RPN项(如设定阈值,RPN > 150),必须强制制定并实施风险缓解措施,如增加二次审核流程、优化UI警报、加强医生培训等。
下面是一个FMEA分析的简化示例。
通过FMEA,我们可以将模糊的安全顾虑,转化为可量化、可管理、可追溯的工程任务。
3.3 法规与伦理合规
产品研发的全流程必须对标NMPA、FDA、CE等监管机构的要求,尤其是在数据隐私、网络安全、算法变更管理等方面。对于生成式AI,还需遵循相应的伦理备案和内容安全规范。将评测结果与卫生技术评估(HTA)框架接轨,也能为后续的医保准入提供高级别证据。
🌀 四、工作流深度融合与人机协同,从“能用”到“爱用”
AI产品的最终成败,取决于它能否无缝地融入复杂的临床工作流,成为医生得心应手的工具,而非一个需要额外适应的“外挂”。
4.1 信息呈现与交互设计
信息降噪,AI的分析结果是否清晰直观?关键信息是否被突出显示?过多的信息或警报会导致“警报疲劳”,反而降低医生的警觉性。
操作简化,调用AI、查看结果、进行交互(如确认、修改、拒绝)的操作是否简便快捷?是否增加了不必要的点击和等待?
4.2 工作节点精准匹配
AI功能必须精准匹配医生在初筛、精读、会诊、报告书写等不同环节的实际需求。它应该在医生最需要的时候提供帮助,而不是生硬地打断原有的工作节奏。
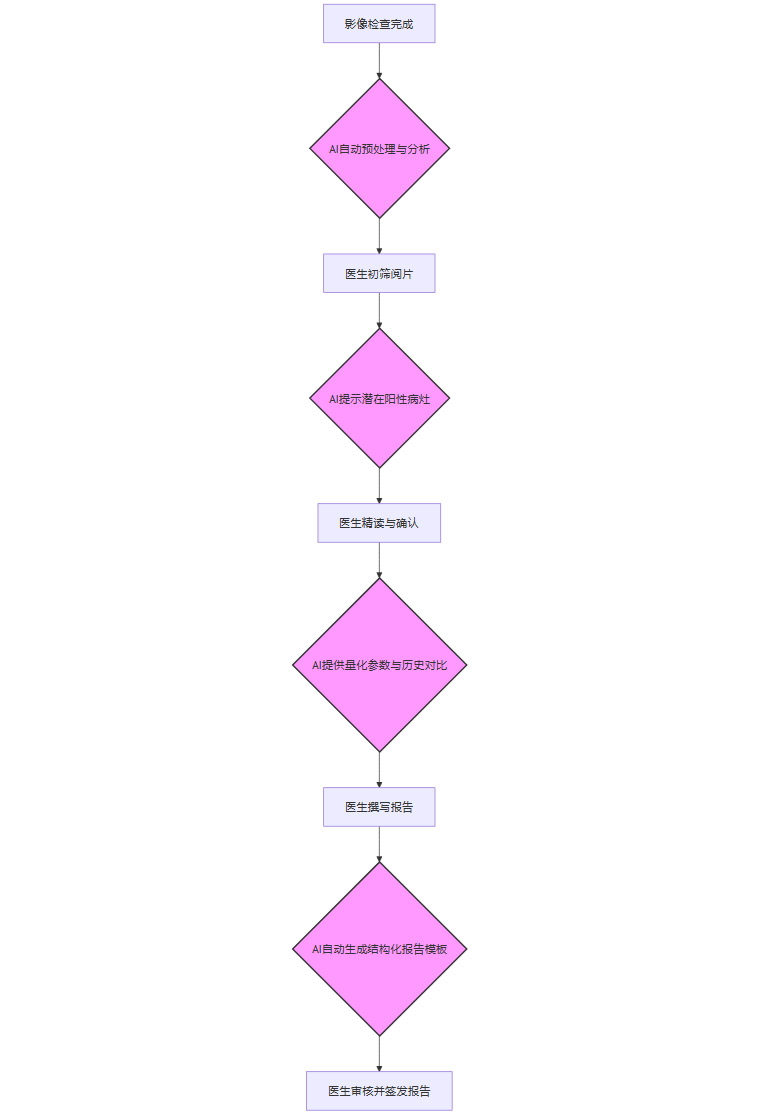
上图展示了AI在影像科阅片工作流中的理想嵌入点
新华医院通过“零代码”平台,让基层医生可以灵活配置AI工具,使其深度嵌入当地的诊疗流程,最终将操作复杂度降低了50%。理邦的AI心电分析系统(AI-SEIMIP)直接嵌入急诊分诊流程,为实时决策提供了有力支持。
4.3 建立持续反馈与迭代机制
建立高效的临床反馈闭环至关重要。通过平台化的数据和工作流管理,持续汇聚、复盘临床使用中的问题和需求,并将其转化为产品迭代的动力,让AI与医生共同成长。
🌀 五、经济价值与持续治理,打通支付与管理的最后一公里
%20拷贝-wodb.jpg)
一个临床有效、医生爱用的产品,还必须向医院管理者和医保支付方证明其经济价值,并建立长效的治理机制。
5.1 卫生经济学评估
成本-效果/效益分析,量化AI带来的直接和间接经济价值,如减少不必要检查、缩短住院日、降低并发症发生率等。
预算影响分析,预测在一定规模的医疗机构或区域内,全面部署该AI产品后,对总体医疗支出的影响。
场景化ROI (投资回报) 分析,针对不同级别的医院,计算其投资回报。在基层,ROI可能体现在扩大筛查覆盖、降低转诊成本;在三甲医院,则更侧重于提升疑难病症诊疗水平和释放高价值医务资源。
这些分析报告是支撑医院采购决策和医保支付谈判的坚实数据基础。
5.2 持续治理与演进
模型上线绝非终点,而是一个新起点的开始。
数据漂移监测,临床实践在不断变化,新的设备、新的诊疗指南都可能导致“数据漂移”,使模型性能下降。必须建立自动化的监测仪表盘,持续追踪模型在真实世界数据上的表现。
模型再校准与再训练SOP,一旦监测到显著的性能衰减,应立即启动标准作业程序(SOP),进行模型的再校准或再训练,确保其长期有效。
真实世界证据的持续积累,通过多中心RWS队列,持续积累AI在性能、效用、效率、安全事件等方面的数据,这些证据不仅能反哺产品迭代,也是与监管机构沟通、支持支付决策的关键资产。
结论
从高AUC走向临床落地,医疗AI的评估是一场从单点技术突破到体系化工程能力的深刻变革。一个高质量的评估闭环,必须是多维度的,它应兼具系统性的理论框架、真实世界的效用证据、明确的风险管控机制、无缝的工作流整合以及可持续的经济与治理模式。
构建这样的体系并非易事,它需要算法、产品、临床、法规、管理等多方角色的深度协作。但唯有如此,医疗AI才能真正从“高分模型”迈向“可靠产品”,切实为医生赋能,为患者造福,为整个医疗健康行业创造可持续的价值。
📢💻 【省心锐评】
医疗AI落地,技术指标是入场券,临床价值是生命线,工作流整合是通行证。抛弃AUC崇拜,拥抱多维闭环评估,才能让AI从“能看”进化到“能用、能信”。

评论