.png)


【摘要】AI创业的生死分野不在技术突破,而在能否摆脱“定制化”引力,实现规模化复制。本文剖析其技术与商业陷阱,并提供一套构建“数据-价值”增长飞轮的实战路径。
引言
在我的职业生涯中,我见证了太多技术团队的悄然落幕。其中最令人惋惜的一幕,莫过于一家名为“Alpha Intelligence”的初创公司。他们的团队背景堪称豪华,手握一项在特定领域内识别率远超同行的图像分析算法。凭借这个技术Demo,他们在第一年就轻松签下了十几个大客户,风光无两。
然而,三年后,Alpha Intelligence在几乎无人察觉中倒闭。他们的技术从未落后,甚至在倒闭前夕还在优化着模型的最后一个百分点。真正的死因,记录在他们混乱的代码仓库和紧绷的现金流里。为了满足每一个早期客户的“独特需求”,他们为每个项目都维护了一个独立的代码分支。最终,公司拥有了十几个功能各异、数据无法互通的“特供版”产品。
他们不是死于技术不精,而是死于用手工作坊的模式,去打一场现代化工业战争。他们以为自己在打造AI产品,实际上却在无休止地交付AI项目,最终沦为一家披着AI外衣的“高级外包”。
这个场景,在今天的AI创业浪潮中正以十倍速重演。无数团队正走在同一条路上。本文的目的,就是彻底解构这个陷阱,并提供一套可执行的工程化路径,帮助真正的技术信仰者,从“项目交付”的泥潭中挣脱,走向“产品帝国”的彼岸。
💎 一、致命的幻象:90%的AI公司为何沦为“高级外包”?
%20拷贝.jpg)
AI创业的“死亡谷”,并非始于技术无法实现,而是始于第一个定制化项目的成功交付。这种短期的收入和客户认可,带来一种致命的幻觉,让团队误以为找到了通往成功的道路。殊不知,这正是通往“高级外包”陷阱的入口。
1.1 “项目交付”与“产品构建”的认知鸿沟
许多技术创始人对产品的理解存在一个根本性的偏差。他们认为 产品 = 软件 = 功能集合。在这种认知下,产品经理的角色被简化为需求翻译官,负责将客户的愿望清单转化为工程师的任务列表。
而一个真正意义上的产品,其可见的功能界面只是冰山一角。水面之下,是支撑其长期价值的庞大体系。
AI产品的冰山模型
当团队的全部精力都聚焦于水上10%的“功能实现”时,他们实际上是在做项目交付。而产品构建,则是对水下90%体系的系统性设计与建设。混淆这两者,是走向外包化的第一步。
1.2 技术债:定制化的三重技术恶果
从架构师的视角看,无休止的定制化会迅速累积起三类难以偿还的技术债务,最终锁死公司的发展潜力。
1.2.1 代码分支的噩梦
为每个客户维护一个独立的代码分支,是灾难的开始。起初,这似乎是最高效的方式。但随着客户数量增加到5个、10个,情况会迅速失控。
维护成本指数级增长。一个核心模块的Bug修复,需要在10个分支上分别修改、测试和部署。
新功能无法复用。为客户A开发的某个功能,无法轻易迁移给客户B,因为底层依赖和数据结构早已不同。
技术栈固化。团队被锁定在旧的技术栈上,任何架构升级的尝试都会因涉及所有分支而变得成本高昂,最终被放弃。
1.2.2 数据孤岛的诅咒
对于AI公司而言,数据是核心资产。定制化模式则亲手将这份资产分割、孤立,最终使其价值归零。
模型无法统一迭代。来自不同客户的数据被物理或逻辑隔离,无法汇集到一个统一的数据湖中去训练和优化核心模型。这意味着,服务100个客户积累的数据,无法让模型比服务10个客户时更聪明。
反馈价值流失。用户的每一次交互、每一次反馈,本应是优化产品的燃料。但在数据孤岛中,这些宝贵的反馈数据只能用于优化对应客户的“特供版”模型,无法形成全局的、可复用的洞察。
1.2.3 架构腐化的必然
为了快速响应销售签下的定制需求,技术团队被迫不断在现有架构上“打补丁”。
牺牲通用性。为满足某个大客户的特殊流程,在核心模块中加入大量
if-else逻辑,破坏了设计的通用性和优雅性。规避重构。本应进行的架构重构,因为害怕影响线上众多客户的稳定运行而被无限期推迟。
接口混乱。系统对外暴露的API变得复杂且不一致,新成员接手开发的难度剧增。
长此以往,整个技术体系变得脆弱不堪,每一次微小的改动都可能引发雪崩式的故障。
1.3 成本结构:线性增长的陷阱
商业模式的失败是定制化陷阱的最终结局。项目制公司的收入模型是线性的。
收入 = 人天单价 × 投入人数 × 项目周期
这意味着,每一份新增的收入,都对应着几乎等量的成本增加。公司的增长受限于团队规模的扩张速度,无法产生规模效应。这与现代SaaS(软件即服务)的商业模式背道而驰 21。一个健康的SaaS产品,其边际成本趋近于零,每增加一个新用户,带来的几乎全是利润。
而项目制公司,利润微薄,现金流极其脆弱,高度依赖少数大客户的回款周期。一旦市场环境变化或大客户流失,公司便会立刻陷入生存危机。
1.4 死亡名单的警示
行业历史已经反复验证了这条路径的危险性。根据统计,高达42%的AI初创公司失败于产品与市场不匹配(PMF),而盲目的定制化是导致PMF缺失的核心原因之一 18。
这份“死亡名单”上不乏曾经的明星项目。例如,自动驾驶独角兽Argo AI,尽管技术实力雄厚,但因商业化落地成本过高,无法摆脱对大客户(福特、大众)的重度依赖,最终在烧掉数十亿美元后关闭 5 13。提供AI生成图库的StockAI,也因运营成本高昂且未能建立可持续的付费模式,仅维持4个月便宣告倒闭 5。曾被视为GPT-3“二创”标杆的Jasper,在OpenAI亲自下场后,因缺乏足够的技术护城河而迅速陷入困境 3 5。
这些案例共同指向一个残酷的现实,技术上的领先,无法自动转化为商业上的成功。如果不能从项目思维中跳出,再强的技术团队也只是在为他人做嫁衣,最终成为“高级外包”。
💡 二、破局之路:从项目思维到产品思维的三大跃迁
%20拷贝.jpg) 要逃离定制化陷阱,公司必须在关键节点上完成一次彻底的思维范式转换。这次转换的核心,是从“满足单个客户”的项目思维,跃迁至“服务一类客户”的产品思维。而推动这次跃迁的关键角色,正是那个常常被误解和低估的——产品经理。
要逃离定制化陷阱,公司必须在关键节点上完成一次彻底的思维范式转换。这次转换的核心,是从“满足单个客户”的项目思维,跃迁至“服务一类客户”的产品思维。而推动这次跃迁的关键角色,正是那个常常被误解和低估的——产品经理。
这里的产品经理,不是只会画原型的“功能协调员”,而是懂技术、懂商业、懂数据的“价值结构师” 19。他必须领导团队完成以下三大战略跃迁。
2.1 价值逻辑跃迁:从满足个案到定义范式
这是最艰难,也最关键的一步。它要求产品经理顶住来自销售、客户甚至创始团队内部的巨大压力。
项目思维。目标是满足客户A的所有需求,无论多么独特。成功的标准是客户A满意并付款。
产品思维。目标是找到100个像客户A一样的客户,提炼出他们共同需求的最大公约数,并将其固化为标准解决方案。成功的标准是市场占有率和可复制性。
产品经理的核心职责,是勇敢地对那些偏离产品主航道的个性化需求说“不”。这并非傲慢,而是对产品愿景的坚守和对规模效应的信仰。他需要具备极强的抽象能力,从无数看似杂乱的个案需求中,淬炼出行业的本质痛点,并定义出解决这一痛点的标准范式。
2.2 商业模式跃迁:从贩卖时间到复制价值
价值逻辑的转变,直接带来了商业模式的重构。
产品经理设计的标准化产品体系,是实现这种商业模式跃迁的唯一载体。他设计的每一个功能、每一个模块,都必须以**“可复用性”和“可配置性”**为第一原则。通过巧妙的设计,将不同客户的“个性化需求”转化为标准产品的“配置选项”,从而在满足客户多样性的同时,守住产品核心的统一性。
2.3 组织能力跃迁:从依赖个体到固化于体系
一个公司的核心能力,最终必须沉淀在组织和体系上,而非少数几个“英雄”身上。
项目制公司。核心竞争力是几个资深的工程师和销售。他们懂技术、懂客户。一旦他们离开,公司的核心能力就随之流失。公司的规模受限于“英雄”的数量。
产品化公司。核心竞争力是产品本身。产品是公司对行业所有理解的结晶。新员工可以通过理解产品,快速掌握公司的核心打法。组织效率极高,规模扩张不受限于个体。
在这个过程中,产品经理扮演着**“首席知识编码官”**的角色 19。他负责将顶尖算法工程师的智慧、行业专家的洞察、金牌销售的客户理解,全部“编码”进产品的架构、逻辑和流程之中。他构建的不是一个简单的软件,而是一个能够产生结构性复利的系统。每一次客户服务、每一次功能迭代,都能为这个系统提供养料,使其不断进化。
完成这三大跃迁,公司才能真正摆脱对人的依赖,建立起可规模化、可复制的增长引擎,从一个“技术作坊”进化为一家现代化的“产品工厂”。
🚀 三、飞轮构建:实战拆解AI产品的“数据-价值”闭环
%20拷贝.jpg)
从思维跃迁到落地执行,需要一套清晰的工程化方法论。AI产品的规模化,核心在于构建一个能够自我强化的**“增长飞轮”**。这个飞轮的本质,是一个“数据-价值”的闭环反馈系统 4 6 10。它让产品不再依赖于外部的功能堆砌,而是能够通过用户的使用,“越用越聪明”,从而提供更大价值,吸引更多用户,形成正向循环。
3.1 飞轮的起点:从MVP(最小可行产品)开始
构建飞轮的第一步,是坚决摒弃大而全的项目式开发,拥抱MVP-first策略 18 23。MVP的目标不是交付一个完美的产品,而是用最低的成本、最快的速度,验证一个核心的价值假设。
AI产品的开发路径,应遵循严格的递进逻辑。
PoC (Proof of Concept, 概念验证)。回答“技术上能否实现?”。这个阶段可能只是一个Jupyter Notebook里的算法原型,用来验证核心模型的可行性。
MVP (Minimum Viable Product, 最小可行产品)。回答“用户是否愿意为核心价值买单?”。MVP是一个具备了最小闭环功能的产品。它可能很粗糙,但必须能解决一个真实痛点。例如,一个智能客服的MVP,可能只是一个能准确回答TOP 10高频问题的API接口,而不是一个功能完善的对话平台 23。
Standardized Product (标准化产品)。在MVP验证成功的基础上,逐步将解决方案固化、封装,形成可规模化销售的标准产品。
从一开始就追求做一个庞大的平台,是创业公司最容易犯的错误。正确的路径是“先造一艘能渡河的独木舟(MVP),验证航线是否正确,再逐步把它扩建成一艘远洋巨轮(产品帝国)”。
3.2 飞轮的核心组件:用户反馈机制的技术实现
飞轮转动的动力,来源于高质量的用户反馈数据。因此,在产品设计之初,就必须从技术上规划好反馈数据的采集、处理和应用机制。这套机制是AI产品区别于传统软件的核心 8 11 15。
3.2.1 显式反馈与隐式反馈的采集
反馈数据分为两类,需要设计不同的采集策略。
显式反馈 (Explicit Feedback)。用户主动提供的、意图明确的反馈。
技术实现。在UI层面设计简洁、低干扰的反馈组件。例如,在AI生成内容的旁边放置“👍/👎”按钮、星级评分、或“复制”、“重写”按钮。当用户点击时,前端通过API将
{content_id, user_id, feedback_type, timestamp}等信息发送到后端日志系统。
隐式反馈 (Implicit Feedback)。从用户行为中推断出的、隐含的反馈。
技术实现。通过前端埋点和后端日志,大规模采集用户行为数据。例如,对于一个推荐系统,用户对推荐结果的点击率 (CTR)、停留时长、转化率 (CVR) 都是强烈的隐式反馈信号。这些数据需要与具体的推荐策略和内容ID关联,形成可供模型分析的训练样本。
3.2.2 反馈数据的处理流水线
原始的反馈数据是嘈杂的,无法直接用于模型训练。必须建立一套自动化的数据处理流水线(Pipeline)。
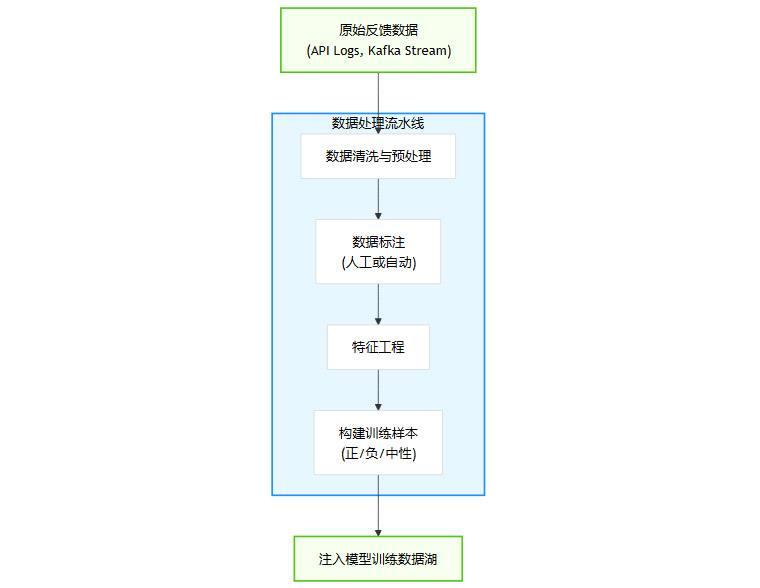
数据清洗。去除机器人流量、处理格式错误、统一数据规范。
数据标注。对于复杂的反馈(如用户评论),可能需要引入人工标注或模型自动标注(用一个模型去标注另一个模型的数据)。例如,用一个情绪分析模型,将用户评论自动标注为“正面”、“负面”或“中性”。
特征工程。从原始数据中提取对模型有用的特征。例如,从用户设备、IP地址、历史行为中提取用户画像特征。
样本构建。将处理后的数据构造成模型可以理解的训练样本。例如,对于一个生成模型,“用户点击了重写按钮”可以被构造成一个负样本,而“用户复制了生成内容”则是一个强正样本。
3.3 飞轮的引擎:自动化模型迭代流水线 (MLOps)
收集并处理好数据后,下一步是让这些数据能够自动、持续地优化我们的模型。这就需要建立一套成熟的MLOps (Machine Learning Operations) 流水线 17。
3.3.1 触发与调度机制
模型的重新训练(Re-training)或微调(Fine-tuning)不能是随意的,需要有明确的触发机制。
周期性触发。例如,每天晚上利用闲置算力,使用过去24小时的新增数据对模型进行增量训练。
事件驱动触发。当收集到的高质量反馈数据达到一定阈值(如10000条)时,自动触发一次训练流程。
模型性能监控触发。通过线上监控发现模型的核心指标(如准确率、CTR)出现显著下降(即模型漂移 Data Drift 4),自动触发重训练。
3.3.2 自动化训练与评估
训练流程需要完全自动化,无需人工干预。
数据拉取。从数据湖中拉取最新的训练集、验证集和测试集。
模型训练。执行预设的训练脚本,产出一个新的候选模型版本。
离线评估。在测试集上对新模型进行全面评估,并与当前线上的生产模型进行对比。评估指标不仅要包括模型指标(如Accuracy, F1-score),也要包括业务指标(如预估CTR)。
模型注册。如果新模型的综合表现优于旧模型,则将其注册到模型仓库(Model Registry)中,并附上版本号、性能报告和训练数据快照。
3.3.3 A/B测试与安全部署
一个离线评估表现更好的模型,不代表在线上真实流量中也会有更好的效果。严格的线上A/B测试是模型上线的最后一道,也是最重要的一道门槛 4 6。
流量切分。将一小部分用户流量(如5%)分配给新模型(实验组),其余流量继续使用旧模型(对照组)。
指标观测。在一段时间内(如一周),持续观测两组用户在核心业务指标上的差异。
决策与全量。只有当新模型在统计上显著优于旧模型时,才逐步将全量用户切换到新模型。同时,必须具备快速回滚到旧版本的能力,以应对突发问题。
3.4 飞轮的闭环:价值驱动的持续增长
至此,一个完整的“数据-价值”飞轮已经形成。
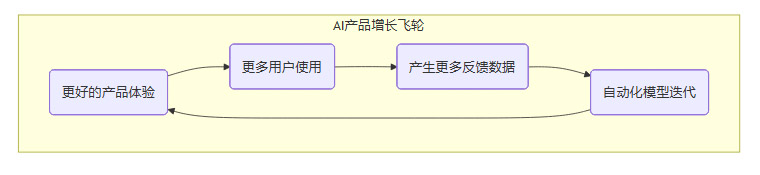
这个飞轮的每一次转动,都会让产品变得更好。更好的模型提供更精准、更有价值的服务,这会提升用户满意度和留存率,从而吸引更多用户。更多用户的深度使用,又会产生更多、更高质量的反馈数据,为下一轮模型迭代提供了更丰富的燃料。
这就是从“高级外包”走向“产品帝国”的核心路径。它将公司的价值积累,从依赖于人力的线性堆叠,转变为一个能够自我驱动、指数增长的系统。
结论
我们正处在一个技术的黄金时代,但商业的法则从未改变。AI创业的下半场,竞争的核心早已不是模型跑分的技术之战,而是商业模式的可持续性之战。
定制化陷阱,本质上是一个商业模式的陷阱。它用短期的、看得见的合同收入,换取了公司长期增长潜力的丧失。无数技术实力卓越的团队,最终不是倒在技术攻关的路上,而是溺亡在了一个个定制项目的汪洋大海里。
逃离这个陷阱的唯一路径,是进行一场彻底的、自上而下的产品化转型。这意味着:
在战略上,完成从项目思维到产品思维的三大跃迁,将公司的核心价值从“人”转移到“体系”。
在战术上,坚决执行MVP策略,并围绕用户价值,构建一套自动化的、闭环的“数据-价值”增长飞轮。
这条路充满挑战。它要求创始人具备抵制短期诱惑的战略定力,要求产品经理具备定义行业范式的抽象能力,更要求整个技术团队具备构建可规模化、可迭代系统的工程能力。
成为“产品帝国”的关键,从来不是技术最强,而是最早建立起规模化复制能力的团队。愿每一位投身AI浪潮的创业者,都能看清脚下的道路,做出正确的选择。
📢💻 【省心锐评】
AI创业的生死劫,不在技术能否登顶,而在商业模式能否复制。放弃“一客一策”的工匠执念,拥抱“体系驱动”的规模化飞轮,才是从作坊走向帝国的唯一路径。

评论