.png)


【摘要】AI翻译的价值已从语言准确性转向场景有效性,核心是解决真实世界问题。
引言
AI翻译技术已渗透到我们数字生活的各个角落。它不再是少数专业人士使用的工具,而是像水电煤一样的基础服务,无声地支撑着全球信息的流动。从跨境电商的商品页面,到国际会议的实时字幕,再到旅行者手中的拍照翻译APP,AI翻译正在重塑我们沟通、协作与获取信息的方式。
然而,行业对AI翻译的认知和期待,正在发生一场深刻的范式迁移。我们已经走过了单纯追求BLEU分数、痴迷于“译得对”的阶段。今天的核心议题是“用得好”。一个翻译系统,无论其内部模型多么复杂、训练数据多么庞大,其最终价值都必须在真实世界的具体场景中得到检验。
本文将从一个资深技术架构师的视角,系统性地剖析AI翻译从技术工具到问题解决者的演进路径。我们将深入探讨其评判标准的变革、核心技术架构的演进,以及在商业、生活与公共服务领域的深度应用实践。更重要的是,我们将直面其未来的终极挑战,即如何从“语言翻译”跃迁至“情境与文化理解”,成为真正可信赖的跨文化沟通助手。
🌀 一、价值重塑:从“译得对”到“用得好”的范式迁移
%20拷贝.jpg)
评判AI翻译成功与否的标尺,已经发生了根本性的变化。过去,我们用机器的输出无限逼近人类译者的“信、达、雅”。现在,我们更关注它是否能让一个普通用户,在特定场景下,高效、无歧义地完成既定任务。这种从“以语言为中心”到“以任务为中心”的转变,正在重构AI翻译的技术栈、评测体系和产品形态。
1.1 评判标准的演进:从“信达雅”到“功能性”
1.1.1 传统翻译的黄金标准与早期AI评测
人类翻译长期追求“信、达、雅”的统一。
信 (Fidelity),指忠于原文,不歪曲、不遗漏。
达 (Expressiveness),指译文通顺流畅,符合目标语言的表达习惯。
雅 (Elegance),指文字优美,有文采,传递原文的风格和韵味。
在神经机器翻译(NMT)兴起的早期,学术界和工业界自然地沿用了这一思路,试图用量化指标来衡量机器与这一黄金标准的差距。BLEU (Bilingual Evaluation Understudy) 分数应运而生,并迅速成为行业标准。
1.1.2 BLEU分数的本质与局限性
BLEU的核心思想很简单。它通过计算机器翻译结果(candidate)与一条或多条专业人工翻译参考(references)之间n-gram(通常是1到4-gram)的重合度,来评估翻译质量。重合度越高,BLEU分数越高。
这个机制在早期推动NMT模型快速迭代上功不可没。但它的内在缺陷也日益凸显。
重表层,轻语义。BLEU只关心字面上的匹配。一个同义词替换、语序调整,或者完全不同但意思相同的表达,都会导致BLEU分数下降。反之,一个保留了原文错误语法结构、但用词相似的糟糕翻译,却可能获得不错的BLEU分数。
惩罚多样性。语言表达是丰富的。对于同一句话,可以有多种正确的翻译方式。BLEU依赖有限的参考译文,任何偏离参考的有效翻译都会被“惩罚”。
忽略致命错误。BLEU对所有词一视同仁。它无法识别出那些会完全扭曲原意的关键错误,比如否定词的遗漏、关键实体的错译等。一个“无伤大雅”的冠词错误和一个“致命”的否定词错误,在BLEE分数上的体现可能差别不大。
一个简单的例子足以说明问题。
源文:
This product is not recommended for children under 3.参考译文:
不建议3岁以下儿童使用本产品。机器翻译A (语义正确,表达不同):
本产品不适用于3岁以下的儿童。机器翻译B (语义错误,字面相似):
建议3岁以下儿童使用本产品。
机器翻译A是完美的,但因为用词和语序与参考译文不同,其BLEU分数可能低于语义完全错误的机器翻译B。这在需要高准确性的场景中是不可接受的。
1.1.3 “功能性”驱动的新一代评测标准
正是因为BLEU等传统指标的局限性,行业开始转向以“功能性”或“任务完成度”为核心的评测范式。评价的焦点不再是“这句话译得像不像参考译文”,而是“用户通过这句话能否完成他想做的事”。
这种转变催生了全新的评测维度。
这个新标准承认,在很多场景下,一个带有微小语法瑕疵但能让用户顺利买到商品的翻译,远比一个语法完美却让用户产生误解的翻译更有价值。
1.2 新评测体系的技术实现
为了落地“功能性”评测,业界开发了更贴近真实应用场景的评测基准和方法论。
1.2.1 应用型评测基准:TransBench的启示
以阿里巴巴达摩院推出的首个应用型AI翻译评测基准TransBench为例,它不再使用单一的分数来评判模型好坏,而是从多个维度进行立体化评估。这代表了行业评测的未来方向。
TransBench的核心评测维度包括:
基础翻译能力:依然保留对通用文本翻译准确性的考察,但采用了更先进的评测模型,如COMET,它结合了源文、译文和参考译文的嵌入式表示,比BLEU更能捕捉语义相似度。
领域专业能力:针对电商、医疗、法律、金融等垂直领域,考察模型对专业术语的翻译准确性。这需要模型具备相应的领域知识。
鲁棒性 (Robustness):测试模型在处理非标准输入时的表现。这些输入在真实世界中非常普遍,包括:
拼写错误和语法错误
口语化表达和俚语
中英夹杂或多语混合文本
幻觉率 (Hallucination Rate):衡量模型“无中生有”的程度。AI翻译有时会生成源文中不存在的信息,这在产品描述、医疗说明等严肃场景中是致命的。TransBench通过对比译文和原文的信息量来检测幻觉。
文化适配性 (Cultural Appropriateness):这是新评测体系的亮点。它关注翻译是否符合目标市场的文化习惯,主要包括:
文化禁忌词:避免使用在特定文化中具有冒犯性或不吉利的词汇。
敬语规范:在日语、韩语等具有复杂敬语体系的语言中,能否根据对话双方的社会关系选择恰当的敬语或谦语。
本地化表达:能否将源语言的习语、典故转换为目标语言用户能理解的对应表达。
TransBench的出现,标志着AI翻译的“军备竞赛”从单纯的模型参数量和BLEU分数,转向了对真实世界复杂场景的适应能力。
1.2.2 人工评测与AI评测的协同(Human-AI Collaboration in Evaluation)
尽管自动化评测基准越来越完善,但高质量的人工评测(Human Evaluation) 仍然是评估翻译质量的黄金标准,尤其是在评估“雅”和文化适配性等主观维度时。
然而,纯人工评测成本高、周期长、规模小,难以满足大模型快速迭代的需求。因此,“AI辅助的人工评测”或“以人为中心的AI评测” 成为主流。
其典型工作流如下:
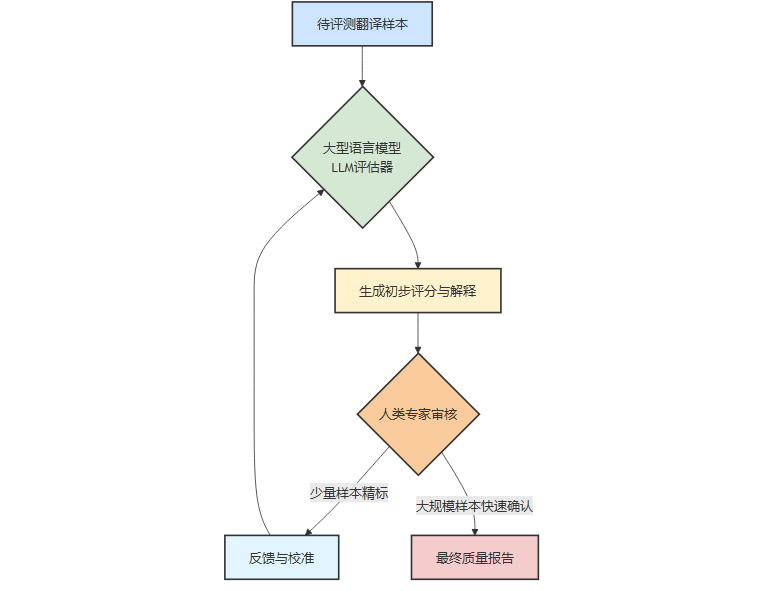
AI评估器初步打分:使用一个能力更强的大语言模型(如GPT-4、Claude 3)作为“裁判”,让它对翻译结果进行打分,并给出具体的优缺点分析。这可以快速处理海量样本。
人类专家审核与校准:人类专家不再需要从零开始评估每个句子。他们的工作转变为:
审核AI评分:判断AI裁判的打分是否合理,修正明显错误的评估。
处理疑难案例:专注于AI难以判断的、涉及深度文化和语境的复杂案例。
校准AI模型:将人工修正的结果作为高质量的标注数据,反过来微调(Fine-tune)AI评估器模型,使其评判标准更接近人类专家。
这种人机协同的模式,兼顾了评估的规模、效率和质量,成为当前业界进行大规模、高质量翻译评测的事实标准。
🌀 二、技术架构与实践:赋能百业的“语言大脑”
%20拷贝.jpg)
AI翻译从一个单一工具演变为赋能平台,其背后是技术架构的系统性升级。它不再是一个孤立的翻译引擎,而是一个集成了多模态感知、领域知识、端云协同能力的复杂系统。
2.1 核心技术栈解构
现代AI翻译系统的核心,已经从传统的统计机器翻译(SMT)和标准的神经机器翻译(NMT),全面转向基于大语言模型(LLM)的架构。
2.1.1 从NMT到翻译大模型(LLM-based Translation)
标准的NMT模型(通常基于Transformer架构)在过去几年取得了巨大成功。它们通过在海量双语平行语料库上进行端到端的训练,学习语言之间的映射关系。
然而,基于通用大语言模型(LLM)的翻译正在成为新的技术范式。与专门为翻译任务训练的NMT模型相比,LLM具有几个显著优势:
强大的上下文理解能力。LLM的训练数据不仅限于平行语料,还包括海量的单语文本。这使其具备了更强的世界知识和常识推理能力,能更好地理解长距离的上下文依赖,从而处理代词指代、消除歧义等问题。
卓越的零样本/少样本(Zero/Few-shot)能力。对于训练数据稀疏的“低资源语言”,传统NMT模型效果很差。而LLM可以利用其从高资源语言中学到的通用语言能力,在没有或只有极少量平行语料的情况下,实现“开箱即用”的翻译。
指令遵循(Instruction Following)能力。这是LLM带来的革命性变化。用户可以通过自然语言指令,控制翻译的风格、语气、格式等。
"Translate this sentence into formal German.""将这段话翻译成中文,并以JSON格式输出,key为'translation'。""把这个产品描述翻译得更有吸引力一些。"
这种可控生成的能力,使得AI翻译从一个固定的转换器,变成了一个可定制的“翻译助理”。阿里巴巴的Marco翻译大模型就是这一趋势的典型代表,它专为电商场景优化,能够深度理解电商领域的特定语境和指令。
2.1.2 多模态融合:超越文本的翻译
真实世界的沟通远不止于文本。现代AI翻译系统正在积极融合图像、语音等多种模态信息,以应对更复杂的场景。
2.1.2.1 AI图片翻译
在电商、产品手册、在线教育等领域,“信息即画面”。图片翻译的需求非常旺盛。其技术流水线通常包括以下步骤:
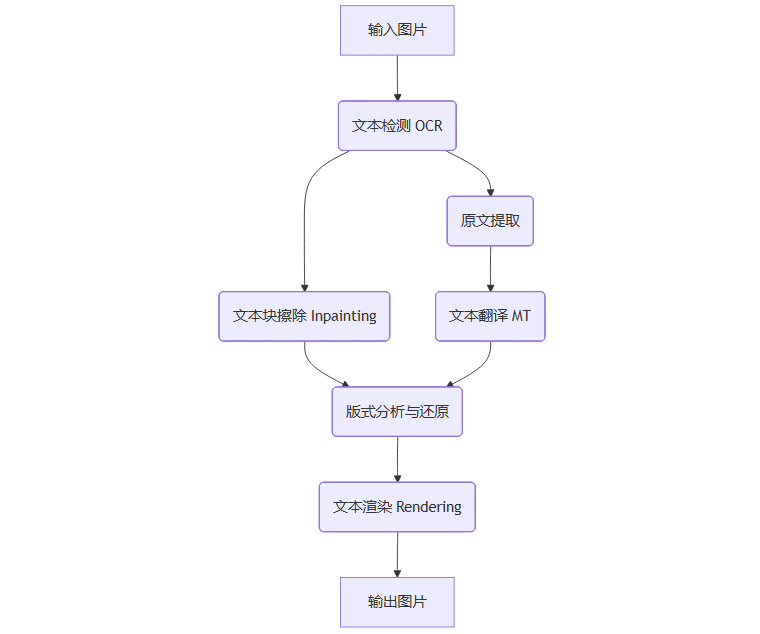
文本检测 (OCR):识别图片中的文字区域和内容。挑战在于处理艺术字体、复杂背景和低分辨率图像。
文本擦除 (Inpainting):在不破坏背景的情况下,将原文从图片中“抹去”。先进的生成式AI模型(如GAN或Diffusion Model)在此环节表现出色。
版式分析与还原:这是图片翻译质量的关键。系统需要分析原文的字体、大小、颜色、对齐方式、行间距等版式信息,并在渲染译文时尽可能复原,保证视觉上的一致性。
文本渲染:将翻译好的文本以合适的版式“写”回被擦除的区域。
通过批量化、模板化的处理,AI图片翻译能够极大地提升电商卖家上架商品、企业制作多语言文档的效率。
2.1.2.2 AI语音翻译
语音翻译(Speech-to-Speech Translation)的目标是实现近乎实时的跨语言语音对话,常见于国际会议、跨国交流和视频同传等场景。
传统的级联式(Cascading)系统是主流方案,它将任务分解为三个阶段:
自动语音识别 (ASR):将源语言语音转换为文本。
机器翻译 (MT):将识别出的源语言文本翻译为目标语言文本。
文本到语音合成 (TTS):将翻译好的目标语言文本合成为语音。
级联系统的优势是每一环节的技术都相对成熟,易于构建和优化。但它也存在问题,如错误累积(ASR的错误会传递给MT,影响最终结果)和延迟较高。
为了解决这些问题,端到端(End-to-End)的语音翻译模型是当前的研究热点。这类模型直接学习从源语言语音到目标语言语音的映射,跳过了中间的文本表示。例如Google的Translatotron系列模型。其潜在优势是延迟更低,并且能更好地保留源说话人的韵律、情感甚至音色,使翻译听起来更自然。
2.1.3 端云协同架构(Edge-Cloud Collaborative Architecture)
AI翻译服务的部署模式也日益灵活,形成了端云协同的混合架构。
一个设计精良的AI翻译应用,会根据具体任务智能地选择或结合这两种模式。
例如,一个旅行翻译APP的典型策略是:
默认使用端侧模型处理拍照翻译、短对话等需要快速响应的请求。
当端侧模型无法识别或用户需要更高质量的翻译时,自动或手动切换到云端模型。
对于常用语料(如“你好”、“谢谢”),可以缓存在本地,实现零延迟响应。
为了在手机等资源受限的设备上部署翻译模型,需要一系列模型压缩技术,如量化 (Quantization)、剪枝 (Pruning) 和 知识蒸馏 (Knowledge Distillation),在保持可接受精度的前提下,大幅减小模型体积和计算量。
2.2 商业领域:全球化协作的加速器
AI翻译正作为一种战略性基础设施,深度嵌入全球商业的各个环节,成为企业出海和跨国协作的“标配”。
2.2.1 跨境电商场景深度剖析
跨境电商是AI翻译技术应用最深入、创造价值最直接的领域之一。语言壁垒是阻碍买家下单和卖家拓展市场的核心痛点。
2.2.1.1 智能商品信息翻译
这远不止是简单地翻译商品标题和描述。一个优秀的电商翻译系统需要做到:
关键词本地化:不仅是翻译,更是结合目标市场的用户搜索习惯,将源语言的关键词映射为目标市场的高流量搜索词,这是跨语言SEO的核心。
营销文案适配:不同文化的消费者对营销语言的偏好不同。AI需要学习将“性价比高”的描述,转换为符合欧美消费者习惯的“durable and reliable”或“great value”等表达。
SKU属性翻译:对颜色、尺寸、材质等结构化属性进行精准、一致的翻译,避免因“米白”和“象牙白”翻译不一致而导致SKU混乱。
2.2.1.2 多语言实时客服系统
实时客服是建立买家信任、促成交易的关键。AI翻译在此环节的技术挑战在于低延迟和高鲁棒性。
一个典型的客服翻译流程如下:
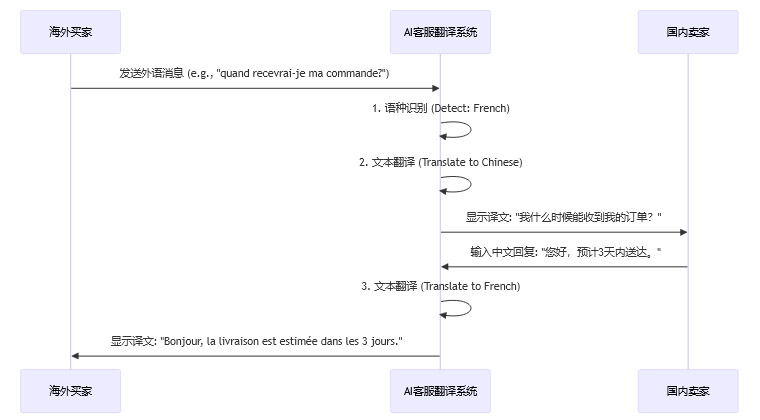
整个来回的延迟必须控制在秒级以内。系统还需要能处理买家输入的拼写错误、俚语和表情符号,保证沟通的顺畅。有数据显示,高质量的AI翻译API应用,曾帮助中国品牌在“反向海淘”中实现高达400%的转化率提升,这背后是用户体验和信任度的巨大改善。
2.2.2 跨国企业协作与会议
对于全球化运营的企业,内部沟通效率直接影响其竞争力。
多语言文档协作:AI翻译插件被集成到Office、SharePoint、Confluence等协作平台中,实现文档的一键翻译。技术挑战在于保持复杂的文档格式(如PPT的排版、Excel的公式)不被破坏。
国际会议实时字幕/同传:AI同传系统正在大型国际会议和企业视频会议中普及。它需要一个高度优化的实时处理流水线,整合说话人分离(Speaker Diarization)、ASR、MT和TTS技术,在极低的延迟下提供多语种字幕和语音输出,极大地降低了跨语言会议的组织成本。
2.3 日常生活与公共服务
AI翻译技术正以“润物细无声”的方式,融入公共服务和个人生活,推动信息无障碍和社会包容。
2.3.1 无障碍沟通的技术实现
服务听障人士:在发布会、课堂、公共服务窗口等场合,AI同传系统通过高精度的语音转文字(ASR),为听障人士提供实时的文字字幕,帮助他们平等地获取信息。
服务视障人士:结合OCR和TTS技术,手机APP可以“读出”菜单、路牌、药品说明书上的外文信息,为视障群体的独立出行和生活提供便利。
2.3.2 人道主义救援与应急通信
在自然灾害、跨国医疗援助等场景下,语言不通可能危及生命。AI翻译在此类场景下的核心要求是高可靠性和可用性。
低延迟与低幻觉:在医患沟通中,翻译系统必须保证对症状、用药指导等关键信息的准确传达,幻觉和错译是不可接受的。
离线能力:灾区或偏远地区往往网络信号中断。支持离线使用的端侧翻译模型成为刚需。
清晰表达:系统需要保障医患双方的知情权,确保沟通的清晰、无歧E。
2.3.3 濒危语言保护与文化传承
全球有数千种语言正濒临灭绝。AI翻译技术为这些“低资源”语言的保护提供了新的可能。
数据化保存:语言学家可以与AI工程师合作,利用AI工具对濒危语言的田野调查录音、手稿进行快速的转写和数字化。
辅助翻译与学习:通过迁移学习(Transfer Learning),可以利用从高资源语言中学到的知识,为濒危语言快速构建一个基础翻译模型和学习工具,帮助新一代人学习和使用母语,推动语言的活化与传承。
这不仅是技术问题,更体现了科技在推动全球语言多样性和文化平等方面的人文关怀。
🌀 三、终极挑战:从“语言翻译”到“情境与文化理解”
%20拷贝.jpg)
AI翻译在处理字面信息上已足够强大,但其真正的“天花板”在于理解语言背后的深层世界。人类沟通远不止于词汇和语法的交换,它承载着情感、意图、文化背景和微妙的社交信号。当前AI翻译在处理俚语、幽默、典故时频频“翻车”,根源就在于这种情境与文化理解能力的缺失。未来的终极目标,是让AI从一个“语言转换器”进化为一个“跨文化沟通助手”。
3.1 语义的鸿沟:为何“直译”远远不够
“翻译了字面,丢了灵魂”是当前AI翻译面临的核心困境。这种困境源于语言内在的复杂性和文化的多样性,形成了难以逾越的语义鸿沟。
3.1.1 普遍存在的歧义性(Ambiguity)
歧义是自然语言的固有属性,也是AI翻译出错的重灾区。
词汇歧义 (Lexical Ambiguity):同一个词在不同上下文中含义迥异。例如,“bank”可以是“银行”,也可以是“河岸”。没有足够的上下文,机器很难做出正确判断。
结构歧义 (Structural Ambiguity):句子结构本身可能产生多种解释。例如,“I saw a man on a hill with a telescope.” 是“我用望远镜看到了山上的一个人”,还是“我看到了一个带着望远镜在山上的人”?
语义歧义 (Semantic Ambiguity):句子本身没有语法问题,但可以从不同层面理解。例如,“Every student read a book.” 是所有学生读了同一本书,还是每个学生都读了自己的一本书?
LLM凭借其强大的上下文建模能力,在解决部分歧义问题上比传统NMT更胜一筹。但面对更复杂的、需要外部世界知识的歧义,依然力不从心。
3.1.2 根深蒂固的文化烙印
语言是文化的载体。脱离文化背景的翻译,即使语法正确,也可能是无效甚至冒犯的。AI翻译在文化适配性上,面临着系统性的挑战。
3.1.3 概念的不可译性(Untranslatability)
有些概念本身就是特定文化独有的,在其他语言中根本不存在完全对等的词汇。
Hygge (丹麦语):一种舒适、温馨、满足的氛围和感受。
Schadenfreude (德语):幸灾乐祸。
侘寂 (Wabi-sabi, 日语):一种接受短暂和不完美、欣赏朴素寂静之美的世界观。
对于这类词,AI翻译不能简单地寻找一个“对应词”,而必须采取解释性翻译或保留原文并加注的方式,这要求AI具备元语言(metalanguage)的认知能力,即“知道自己不知道”,并能选择合适的策略来处理这种不可译性。
3.2 通往深度理解的技术路径
要跨越上述语义鸿沟,AI翻译必须在技术架构上实现从“感知”到“认知”的飞跃。这需要融合多模态信息、外部知识和语用学模型。
3.2.1 多模态情境感知(Multimodal Contextualization)
人类理解对话时,接收的远不止文本。语调、表情、手势、环境等非语言信号,共同构成了完整的“情境”。未来的AI翻译系统必须具备同样的能力。
多模态融合如何帮助翻译?
消除歧义:听到“Apple”这个词时,如果摄像头同时看到桌上的水果,模型就能确定它指的不是科技公司。
识别情感与意图:一个人微笑着说“You are so clever”,其真实意图很可能是赞扬。但如果他同时翻了个白眼,那极有可能是讽刺。视觉和听觉信号是识别讽刺等语用现象的关键。
理解指示代词:当用户指着一个物体说“Translate this”,视觉信息能帮助AI确定“this”指代的是什么。
其技术实现依赖于多模态融合模型。
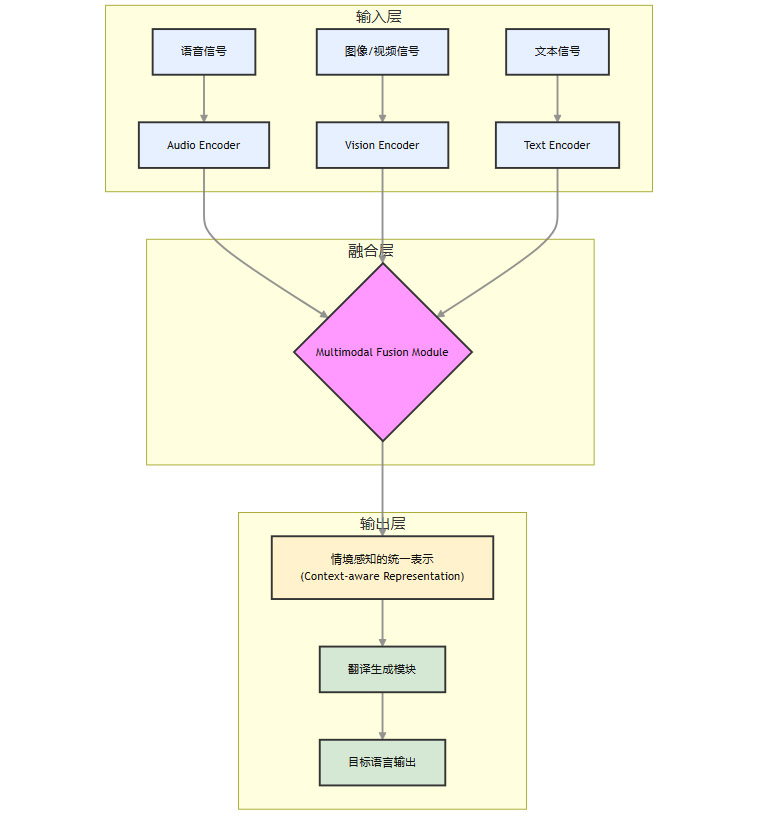
编码器 (Encoder):使用专门的模型(如ViT用于视觉,HuBERT用于音频)将不同模态的原始数据转换为高维向量(Embedding)。
融合模块 (Fusion Module):这是核心。它通过交叉注意力机制 (Cross-Attention) 等技术,让不同模态的向量相互“交流”,捕捉它们之间的关联。例如,文本中的“red”这个词的向量,会更多地关注图像中红色的区域。
统一表示:融合后的向量形成一个包含了所有模态信息的、更丰富的“情境表示”,再送入翻译生成模块。
这种架构使得翻译决策不再仅仅基于源文本,而是基于一个对物理和社会环境有感知的综合情境。
3.2.2 知识图谱与常识推理(Knowledge Graphs & Commonsense Reasoning)
许多翻译错误源于缺乏背景知识或常识。例如,将“The spirit is willing, but the flesh is weak”这句圣经典故直译为“酒精很愿意,但肉很虚弱”,就是典型的缺乏背景知识的错误。
知识图谱(Knowledge Graph, KG) 是弥补这一缺陷的有力工具。KG以“实体-关系-实体”的三元组形式,存储了海量的结构化世界知识。
知识图谱如何赋能翻译?
实体消歧:当文本中出现“Washington”时,通过链接到知识图谱,AI可以确定它指的是美国前总统、华盛顿州还是华盛顿特区,从而选择正确的翻译。
关系推理:理解“拜登访问了巴黎”意味着“美国总统访问了法国首都”,这种推理能力可以帮助AI选择更地道的表达。
补充隐性知识:翻译菜谱时,AI可以从知识图谱中获取“baking soda”(小苏打)和“baking powder”(泡打粉)是不同物质的知识,避免混淆。
将知识图谱集成到翻译模型中,主要有两种技术路径:
知识增强预训练 (Knowledge-Enhanced Pre-training):在预训练阶段,就将知识图谱中的三元组信息融入模型,让模型“记住”这些知识。
检索增强生成 (Retrieval-Augmented Generation, RAG):在翻译时,实时地从知识图谱或文档库中检索与当前文本相关的知识,并将其作为额外的上下文提供给翻译模型。RAG的优势在于其知识库可以随时更新,灵活性更高。
3.2.3 语用学与意图建模(Pragmatics & Intent Modeling)
这是AI翻译的“圣杯”。语用学(Pragmatics) 研究的是语言在特定情境下的实际使用,即“言外之意”。
言语行为理论 (Speech Act Theory):该理论认为,说话不仅仅是在描述事实,更是在“做事”。一个句子可以是一个陈述 (Statement)、一个问题 (Question)、一个命令 (Command)、一个承诺 (Promise) 或一个威胁 (Threat)。
原文:“Could you pass the salt?”
字面翻译:“你能把盐递过来吗?”
意图识别:这是一个“请求 (Request)”,而非询问对方的能力。
语用翻译:在某些语言文化中,可能需要翻译成更礼貌或更直接的请求形式。
未来的AI翻译模型需要能够识别源语言的言语行为,并在目标语言中用符合其文化习惯的方式,执行相同的言语行为。这需要模型在标注了对话行为(Dialogue Acts)的数据集上进行训练,学习从字面表达到底层意图的映射。
3.3 工程化落地:构建可信赖的沟通系统
从理论突破到可靠的产品,中间还有漫长的工程化道路。构建一个真正“用得好”的翻译系统,需要在可控性、安全性和个性化上下足功夫。
3.3.1 可控性与可解释性
用户需要能够驾驭AI,而不是被动接受结果。
精细化指令控制:除了简单的“翻译成正式/非正式”,未来用户可以给出更复杂的指令,如“用适合5岁儿童的语言翻译这段话”、“将这份合同翻译成中文,并高亮所有涉及责任和期限的条款”。这要求LLM具备更强的指令分解和执行能力。
交互式翻译:系统在遇到歧义时,不应盲目猜测,而应主动向用户提问。“您提到的‘Apple’是指公司还是水果?” 这种交互式消歧可以显著提升关键信息的准确性。
可解释性:当用户对一个翻译结果感到困惑时,系统应能提供一定的解释,例如“‘班门弄斧’是一个中国成语,意为在专家面前卖弄本领,这里翻译为‘teaching fish how to swim’以传达其讽刺意味”。
3.3.2 文化安全的“护栏”
为了避免AI翻译在跨文化交流中“闯祸”,必须建立一套文化安全护栏(Cultural Safety Guardrails)。
禁忌词与敏感内容过滤:构建并动态更新多语言的禁忌词库。利用分类器模型,在翻译前后对内容进行扫描,对涉及暴力、歧视、色情或特定文化禁忌的内容进行拦截、警告或脱敏处理。
偏见检测与缓解:AI模型在训练数据中会学到人类社会的各种偏见(如性别、种族偏见)。例如,将“The doctor is coming”翻译成“医生(男)来了”,将“The nurse is coming”翻译成“护士(女)来了”。需要采用专门的去偏见算法(Debiasing Algorithms)和平衡的数据集来缓解这一问题。
人机协同审核(Human-in-the-Loop):对于高风险或模棱两可的内容(如政治、宗教话题),系统应自动标记并提交给人类专家审核,确保发布的内容符合当地法律法规和文化规范。
3.3.3 个性化与自适应翻译
“最好”的翻译是因人而异、因时而异的。
用户画像建模:系统可以根据用户的历史行为、职业、年龄等信息,构建用户画像,并自动调整翻译的风格。一个为开发者翻译技术文档的系统,和一个为游客翻译菜单的系统,其用词和风格应截然不同。
领域自适应:当用户持续在某一垂直领域(如法律、医学)使用翻译时,系统应能自动学习该领域的术语和表达习惯,动态地“进化”成一个领域专家。这可以通过持续的用户反馈和在线学习(Online Learning)来实现。
最终,AI翻译系统将不再是一个千人一面的工具,而是一个能够学习和适应每个用户、每个场景的个性化沟通伙伴。
结论
AI翻译的征途,正从追求语言的完美复刻,转向解决真实世界中复杂而具体的沟通问题。“用得好”已经取代“译得对”,成为衡量其价值的唯一标准。这一范式转变为技术研发、产品设计和工程实践都提出了全新的要求。
我们看到,技术上,从基于LLM的翻译大模型,到融合图像、语音的多模态系统,再到端云协同的灵活架构,AI翻译的“引擎”正变得前所未有的强大。在应用上,它已深度赋能商业、生活和公共服务,成为全球化时代不可或缺的基础设施。
然而,前方的挑战依然艰巨。要真正实现从“语言翻译”到“情境与文化理解”的终极飞跃,AI必须学会像人一样,去感知世界、运用知识、理解意图。这不仅需要算法上的持续创新,更需要我们在工程上构建起可控、安全、可信赖的系统。
作为技术从业者,我们的使命不再仅仅是提升一个百分点的BLEU分数。我们的责任,是打造一个能够真正促进理解、弥合分歧、传递善意的工具,让技术的力量,服务于构建一个更包容、更连接的世界。
📢💻 【省心锐评】
AI翻译的终局,不是替代译者,而是成为每个人的“贴身翻译官”与“文化顾问”。其核心竞争力,将从语言转换能力,彻底转向对真实世界情境与文化背景的深度理解和精准适配。

评论